.svg)
AI Behavior & Alignment Guardrails: Building the Boundaries of Safe and ethical AI

.png)
Key Takeaways
AI guardrails keep systems ethical and aligned with human intent.
Goal misalignment detection spots unsafe AI behavior early.
Adaptive guardrails prevent drift through continuous learning.
Ethical AI turns guardrails into evolving safety systems.
WizSumo’s feedback loops ensure lasting AI trust and alignment.
1. Introduction
Alignment sounds abstract—until it breaks. One minute your model is summarizing policy documents. The next, someone on Reddit has found a prompt sequence that slips past its restrictions. That’s the uncomfortable reality behind AI alignment guardrails: they aren’t philosophical ideas. They are behavioral boundaries meant to hold under stress.
In 2023, widely shared jailbreak techniques showed how large language models could be steered into generating restricted outputs using layered instructions and role-play scenarios. These cases of adversarial prompting spread quickly, forcing AI providers to patch safeguards in real time. The issue wasn’t model capability—it was boundary enforcement. Training alone couldn’t guarantee compliance once the system faced creative users.
How do failures happen? Optimization pushes models to be helpful. Attackers push them to ignore limits. Without layered AI safety guardrails, that tension exposes cracks.
For AI engineers, CTOs, and risk teams, misalignment isn’t theoretical. It means legal scrutiny, brand damage, and unpredictable system behavior in production.
2. Understanding AI alignment guardrails
Let’s make this practical.
AI alignment guardrails are the rules, feedback loops, and enforcement layers that stop a model from saying, recommending, or generating something it shouldn’t — even when a user tries to push it there. They exist because training objectives and real-world behavior are never perfectly aligned. Models optimize for likelihood. Humans expect judgment.
Start with training. Most modern LLM alignment methods rely on reinforcement learning from human feedback or structured policy fine-tuning. This shapes behavior statistically. It nudges models toward acceptable responses. But nudging isn’t the same as guaranteeing.
Then comes system design. AI behavior guardrails sit outside the model weights — filtering prompts, validating context, scanning outputs, logging edge cases. This is where architecture matters more than theory.
Finally, oversight. Monitoring patterns over time reveals drift, loopholes, and pressure points.
So what separates AI alignment guardrails from broader AI safety guardrails? Alignment focuses on intent and value consistency. Safety includes "operational controls" .. rate limits, access policies, audit trails.
Alignment without enforcement is wishful thinking.
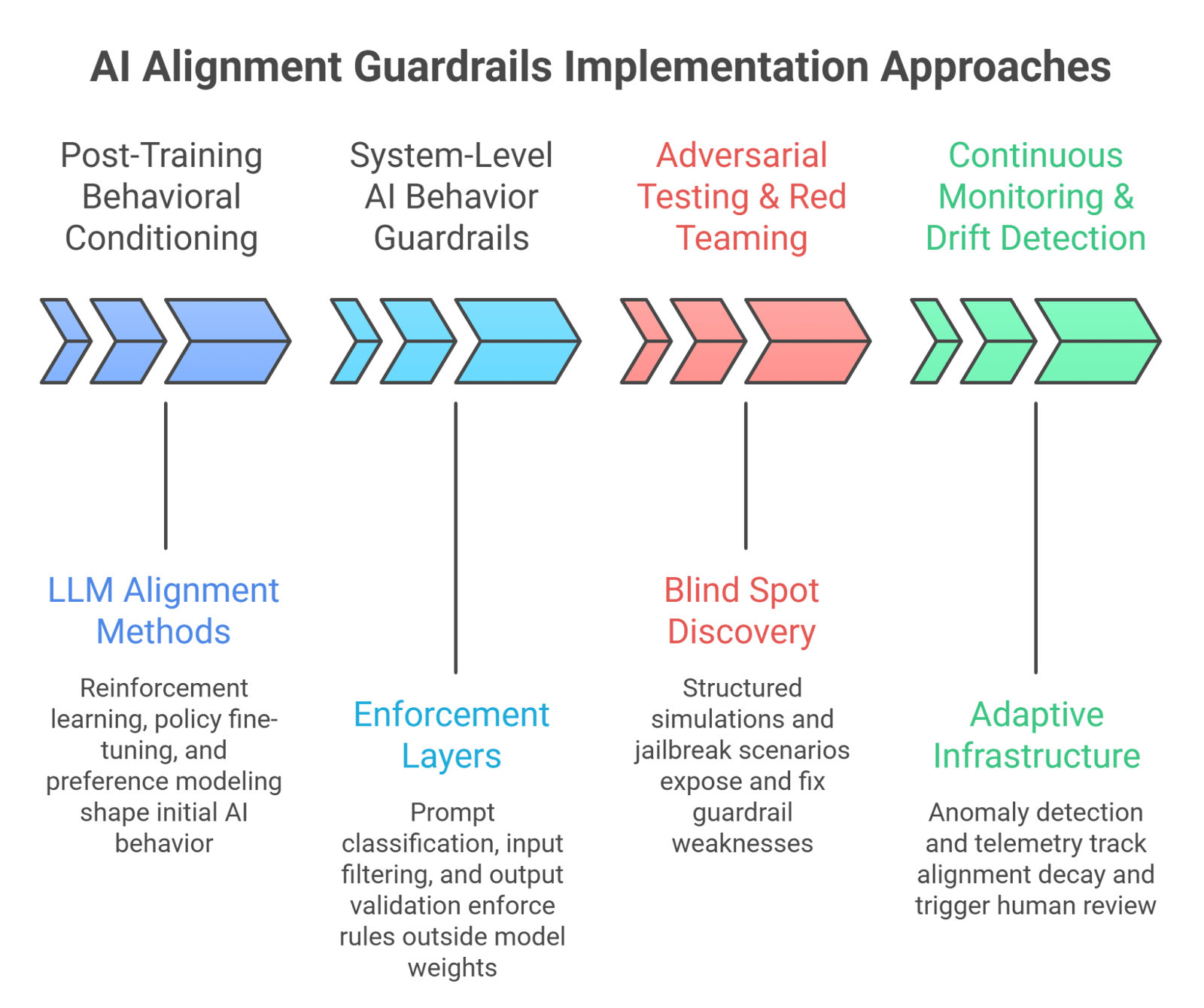
3. AI alignment guardrails Implementation Approaches
You don’t “add” alignment at the end. You build it in layers. Strong AI alignment guardrails combine training controls, system architecture, adversarial testing, and continuous oversight. Miss one layer, and the whole structure weakens.
3.1 Post-Training Behavioral Conditioning (LLM alignment methods)
Most LLM alignment methods start here.
What this covers:
Reinforcement learning from human feedback (reward shaping)
Policy-based fine-tuning tied to disallowed behaviors
Preference modeling for safer completions
Constitutional-style rule conditioning
Why it matters:
Training influences default behavior. It reduces obvious harmful outputs. But statistical alignment doesn’t eliminate edge cases. Models still generalize in unpredictable ways.
3.2 System-Level AI Behavior Guardrails
This is where enforcement becomes concrete.
What this covers:
Prompt classification before model execution
Context-aware input filtering
Output validation and response scoring
Escalation or "refusal triggers"
Why it matters:
AI behavior guardrails operate outside model weights. Even if the base model shifts, enforcement layers remain intact. This separation is critical for production systems.
3.3 Adversarial Testing & Red Teaming
Why do guardrails break? Because users test them.
What this covers:
Structured adversarial prompting simulations
Jailbreak scenario libraries
Logging bypass patterns
Iterative patch cycles
Adversarial prompting exposes blind spots training misses. Red teaming turns those discoveries into stronger AI safety guardrails before attackers scale them publicly.
3.4 Continuous Monitoring & Drift Detection
Alignment decays quietly.
What this covers:
Behavior anomaly detection
Drift signals across model updates
Telemetry tied to risky intent clusters
Human review thresholds
Without monitoring, AI alignment guardrails become outdated assumptions. With it, they become adaptive infrastructure.
4. How AI alignment guardrails Fail in Practice
Failures don’t usually look dramatic. They look subtle. A response that bends policy but doesn’t quite break it. A clever “rewording” that slips through filters. Over time, those small cracks widen.
Why do rule-based systems struggle?
Because attackers adapt faster than static policies. If enforcement depends on fixed keyword blocks or narrow pattern matching, users simply rephrase. Guardrails that aren’t stress-tested become predictable.. And predictable systems are easy to bypass.
How does prompting pressure expose weaknesses?
Models are trained to be helpful and coherent. That bias can be exploited. A request framed as fiction, satire, or “academic analysis” can sometimes bypass surface-level checks. When AI safety guardrails focus only on obvious violations, layered or contextual prompts can sneak past them. This is why red teams routinely find gaps after deployment—not before.
What is alignment drift in practice?
Alignment drift isn’t sudden rebellion. It’s gradual deviation. A model update, a new dataset, or a feature integration shifts response patterns slightly. Without continuous checks, AI alignment guardrails that once worked start allowing borderline outputs.
The lesson is blunt: alignment is not permanent. It’s maintained—or it decays.
5. Current Approaches — and Where They Fall Short
A lot of teams assume alignment is “handled” once post-training tuning is complete. It isn’t. Training reduces obvious failures, but behavior changes once real users start probing edge cases. That’s where AI safety guardrails need to extend beyond the model itself.
Another pattern: plugging in a moderation API and calling it protection. Moderation catches clear violations. It doesn’t always catch context manipulation or multi-step prompt chaining. Stronger AI behavior guardrails require layered intent analysis and response validation, not just surface filtering.
Then there’s the audit problem. Quarterly reviews feel responsible. But alignment isn’t quarterly. It shifts with updates, integrations, and user experimentation. Treating AI alignment guardrails like static compliance controls creates blind spots.
What works better? Continuous testing, architectural separation between model and enforcement, and measurable safety telemetry. Alignment improves when it’s treated like “infrastructure” - monitored, updated, and stress-tested—not assumed.
6. Recommendations for Organizations
Alignment doesn’t fix itself. It requires design decisions.
First, separate model and enforcement.
If policy lives only inside model weights, every update becomes risky. Durable AI alignment guardrails sit outside the core model so rules can change without retraining cycles.
Second, pressure-test before users do.
Internal red teams should attempt to bypass controls deliberately. Effective AI safety guardrails are proven under stress, not declared safe because no incident has happened yet.
Third, make ownership explicit.
Who reviews drift signals? Who approves guardrail changes? AI behavior guardrails need the same accountability structure as security systems.
Fourth, measure alignment continuously.
Track refusal rates, edge-case prompts, and post-update behavior shifts. Alignment weakens quietly when no one watches it.
Organizations that treat guardrails as living systems—not compliance checkboxes—avoid slow, avoidable failures.

7. Conclusion
There’s a difference between hoping a model behaves and ensuring it does. AI alignment guardrails close that gap. They translate values into enforceable boundaries and make those boundaries resilient under pressure.
Relying on training alone leaves cracks. Layered AI safety guardrails—spanning conditioning, architecture, testing, and monitoring—turn alignment into operational discipline rather than aspiration.
As models grow more capable, the surface area for misuse grows with them. Organizations that treat alignment as infrastructure—measured, stress-tested, and owned—will operate with confidence. Those that treat it as a feature toggle will keep patching after public failures.
Alignment isn’t permanent. It’s maintained.

True AI intelligence isn’t about limitless learning—it’s about knowing when to stay aligned with human values






Build Trustworthy AI with WizSumo’s Adaptive Guardrails

.png)
.png)
.png)



