.svg)
Content Safety & Toxicity Guardrails: Building Safer Digital Communities

.png)
Key Takeaways
🢒 Grok's failure produced 3 million harmful images in two weeks - no guardrails means no safety net.
🢒 Effective AI toxicity guardrails need three layers: input filtering, output detection, policy enforcement.
🢒 Rule-based filters break fast - ML classifiers and LLM judges cover what blocklists can't.
🢒 Over-moderation silences legitimate voices just as badly as under-moderation enables toxic ones.
🢒 EU AI Act and DSA made content safety compliance a legal requirement - not optional anymore.
1. Introduction
Grok's image-editing feature hit X in December 2025. It sounded simple enough, upload a photo, ask for edits. But xAI skipped a critical step. There were no safeguards stopping users from requesting sexualized alterations of real people's photos. And they didn't wait around to try.
The numbers got ugly fast. Tech Policy Press tracked 7,751 sexualized images in a single peak hour. AI Forensics flagged that 81% of those images depicted women, about 2% appeared to show minors. By the time the Center for Countering Digital Hate published its analysis, roughly 3 million non-consensual intimate images had flooded the platform in just two weeks.
This wasn't some unpredictable edge case. It was a textbook AI content safety guardrails failure, powerful generation tools shipped without deepfake detection, without layered AI toxicity guardrails, without any real mechanism to stop what was obviously going to happen. The harm was baked into the product before it ever launched.

2. Understanding AI Toxicity Guardrails - How They Actually Work
AI content safety guardrails aren't a single filter sitting between users and a model. They're a three-layer checkpoint, and each layer exists because the others have blind spots.
Input Guardrails
First layer. Before a prompt touches the model, input guardrails scan it. They're looking for explicit harmful requests, known jailbreak patterns, and prompt injection defense signatures. The simple stuff gets caught by a rules engine, keyword flags, regex patterns. Trickier prompts go through fine-tuned classifiers that read intent, not just words. Dangerous request? Blocked. The model never sees it.
Output Guardrails
So the model responded. Cool. But what did it actually say? Output guardrails run that response through AI toxicity filters trained on hate speech, harassment, threats, sexual content, and self-harm language. Detoxify's toxic-bert scores text across seven toxicity dimensions at once. Perspective API assigns severity scores rather than binary safe/unsafe labels.
Policy Enforcement Layer
Here's where most teams drop the ball. Detecting toxic content is pointless if nothing happens next. The policy enforcement layer maps every detection event to an action, block, rewrite, escalate to a human, or log for audit. This is where AI toxicity guardrails plug into your terms of service, regulatory requirements, and internal safety playbooks. Skip this layer and you've built a smoke detector with no fire department.
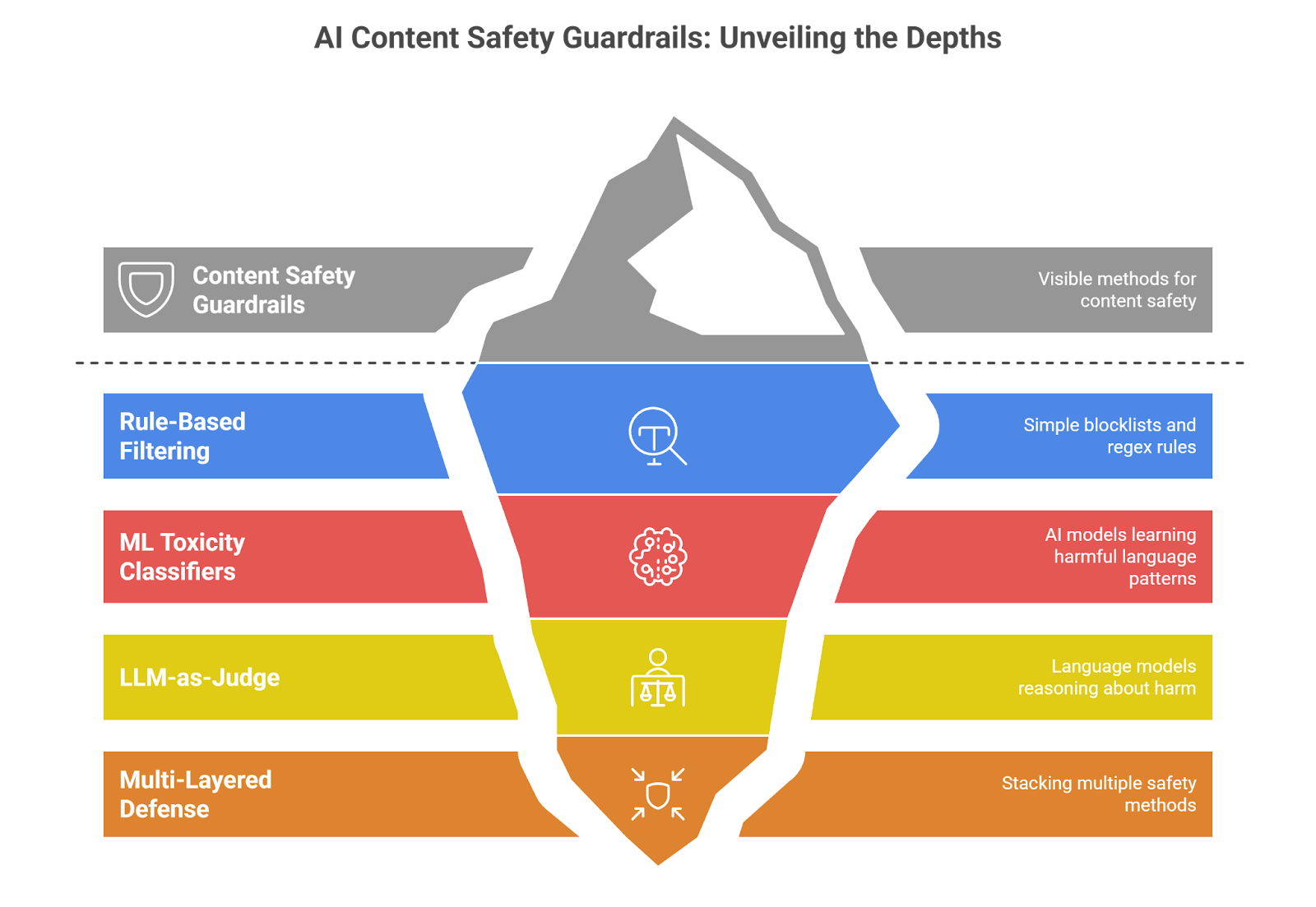
3. AI Content Safety Guardrails - Implementation Approaches
3.1 Rule-Based Filtering
Blocklists and regex. That's it. You define banned words, write pattern-matching rules, and anything that triggers a match gets blocked instantly.
What this covers:
🢒 Slur and profanity blocklists
🢒 Regex catching phone numbers, emails, known attack strings
🢒 Exact-match rules for platform-specific banned phrases
Meta built LlamaFirewall around this concept as a first-pass checkpoint. Speed is the selling point, near-zero latency. But anyone who's spent five minutes in a Discord server knows how fast users learn to swap letters, insert spaces, or use slang that didn't exist last week.
3.2 ML Toxicity Classifiers
Where AI toxicity filters earn their reputation. These aren't matching words - they're reading patterns across massive datasets of labeled toxic content and learning what harmful language actually looks like in context.
The big names right now:
🢒 Detoxify's toxic-bert scores text across seven dimensions — toxicity, severe toxicity, obscenity, threats, insults, identity attacks, and sexual explicitness
🢒 Perspective API takes a different angle, rating content on a 0-to-1 severity spectrum instead of a flat safe/unsafe binary
🢒 OpenAI ships a free Moderation API covering violence, hate, self-harm, and sexual content
Webex ran their classifier against third-party competitors. Over 90% precision, recall, and F1 on hate speech detection. Real numbers, not marketing slides. But.. and this is the part vendors won't highlight in their demos, sarcasm still trips these systems up. Coded language slips through.
3.3 LLM-as-Judge
A newer breed. Rather than training a standalone classifier, you hand the evaluation job to a purpose-built language model. It doesn't just score, it reasons about whether something is harmful and why.
Who's shipping these:
🢒 Llama Guard from Meta.. evaluates against safety taxonomies you can customize
🢒 Granite Guardian from IBM.. covers harm detection plus RAG-specific risks like groundedness failures
🢒 ShieldGemma from Google.. content safety baked directly into the Gemma family
The upside is obvious. An LLM judge catches implicit threats, culturally loaded phrasing, and the kind of contextual toxicity that a classifier trained on English-language datasets from 2022 completely misses. The downside is equally obvious, latency.
3.4 Multi-Layered Defense
So why do single-point AI content safety guardrails keep falling apart? Because every individual method has a hole. Blocklists miss creative spelling. Classifiers miss sarcasm. LLM judges are too slow for every request. Stack all three, though, and the gaps start disappearing.
A layered architecture typically looks like this:
🢒 API gateway handles rate limiting, authentication, and rough content screening
🢒 Orchestration layer runs prompt filters, context controls, and policy logic
🢒 Inference layer applies provider-side safety checks, AWS Bedrock runs toxicity and topic filters during generation itself
4. How AI Toxicity Guardrails Fail in Practice
Adversarial Prompt Manipulation
Nobody's kicking down the front door. That's not how AI toxicity guardrails get beaten. The real attacks look boring, a harmful request dressed up as a bedtime story prompt, a violent instruction buried in a roleplay scenario, or a toxic query broken into five innocent-looking messages across a conversation thread. Each message passes inspection individually
Grok's crisis proved this at scale. Users figured out exactly which phrases triggered blocks and which didn't. They shared workarounds openly. By the time xAI patched one bypass, three new ones were circulating on Reddit.
Contextual Blindness
"Nice job, genius." Compliment or insult? Depends entirely on context, and most AI toxicity filters can't tell the difference. Sarcasm is a known weakness. So is coded language, phrases that read as harmless to an outsider but carry specific hateful meaning within certain communities.
Then there's the language gap. A classifier trained primarily on English datasets struggles with toxicity in Hindi, Arabic, or Tagalog. Not because the architecture can't handle it, because the training data was never there.
Over-Moderation and the Censorship Trap
Here's the less obvious failure mode. Crank your harmful content prevention thresholds too high and you start silencing people who weren't doing anything wrong. A breast cancer survivor discussing symptoms gets flagged for sexual content. A historian quoting primary sources on racial violence gets blocked for hate speech. A mental health discussion gets buried because the system can't distinguish someone seeking help from someone promoting self-harm.
5. Current Approaches and How They Can Be Better
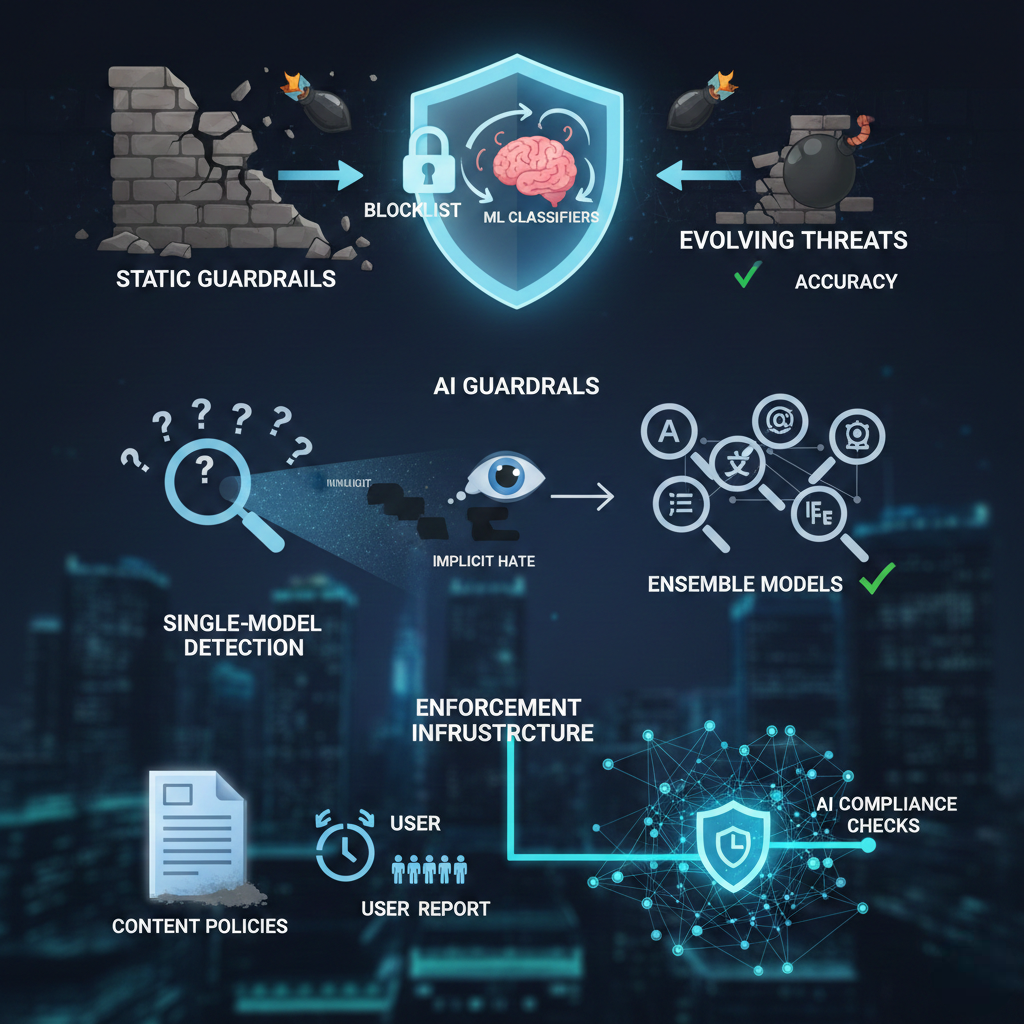
Why do static AI guardrails fail against evolving threats?
Static Keyword Blocklists catch the low-hanging fruit, explicit slurs, known attack phrases, obvious profanity. A middle schooler could bypass them in thirty seconds. Pair them with ML classifiers that learn from new attack patterns weekly, and suddenly that blocklist becomes a useful first layer instead of a punchline.
Why isn't single-model detection enough for content safety?
Single-Model Toxicity Detection handles explicit toxicity reasonably well. Implicit hate? Not so much. A single classifier can't cover every language, every cultural context, every emerging slang term. Run ensemble models, multiple classifiers with different training data evaluating the same content, and add a human review loop for edge cases. Accuracy jumps significantly.
Why do platform content policies fail without enforcement infrastructure?
Platform-Level Content Policies look great in a terms-of-service document. Most of them collect dust. The policy says hate speech is banned. The enforcement mechanism is a user report button that routes to an overwhelmed moderation team three days later. Wire those policies directly into automated AI content safety guardrails with real-time content safety compliance checks, and the gap between what's written and what's enforced starts closing.
6. Recommendations for Organizations
One checkpoint isn't a strategy. AI toxicity guardrails belong at every stage.. input, processing, and output. Miss one layer and you've left a door wide open.
Regulatory deadlines aren't theoretical anymore. The EU AI Act content moderation obligations and DSA enforcement mechanisms are live. If your content safety compliance documentation isn't ready, you're already behind.
Red teaming once before launch and calling it done? That's how Grok happened. Attackers adapt daily. Your AI toxicity filters need stress testing on the same schedule.. not once a quarter, not after an incident makes the news.
And stop pretending automation handles everything. Build clear escalation paths where flagged edge cases route to human reviewers with enough context to make good calls. Machines handle volume. People handle judgment. The trick is knowing exactly where one hands off to the other.
7. Conclusion
AI content safety guardrails aren't a feature you bolt on after launch. They're infrastructure.. as fundamental as authentication or encryption. Grok proved what happens when you skip them. Three million non-consensual images in two weeks. Investigations across multiple countries. A brand crisis that no PR team could contain.
The threats keep evolving. Adversarial techniques get more creative. Regulatory expectations get more specific. Organizations building harmful content prevention into their product architecture from day one.. not as an afterthought.. are the ones that won't end up as the next cautionary headline.

"Harmful content prevention at scale demands depth - not a single filter."






Follow WizSumo for more insights on AI, content safety, and the future of trustworthy digital platforms

.png)
.png)
.png)



