.svg)
AI Bias and Fairness Guardrails: Turning Ethics into Engineering

.png)
Key Takeaways
1. Introduction
A model doesn’t need bad intent to produce unfair outcomes. It just needs skewed data and no one stopping it.
AI systems now screen candidates, summarize meetings, recommend financial actions, and generate public-facing content. If those systems learn patterns that favor one group over another, they repeat them — quietly, efficiently, at scale. That’s the problem AI bias guardrails are meant to solve.
In early 2025, Microsoft tightened its Responsible AI Standard, expanding internal review checkpoints across model "development" and deployment. Yet reports and "practitioner" analyses continued to surface examples of subtle "gender and linguistic bias" in enterprise AI assistants. Not catastrophic failures. Something more dangerous: small, repeatable distortions.
Those distortions compound.
Without intentional AI bias mitigation techniques, bias becomes embedded in workflows before anyone notices. By the time complaints surface, the system has already influenced decisions.
Fairness isn’t achieved by policy language alone. It has to be wired into data pipelines, training loops, and live monitoring systems from day one.
2. Understanding AI Bias Guardrails
So what are AI bias guardrails, really?
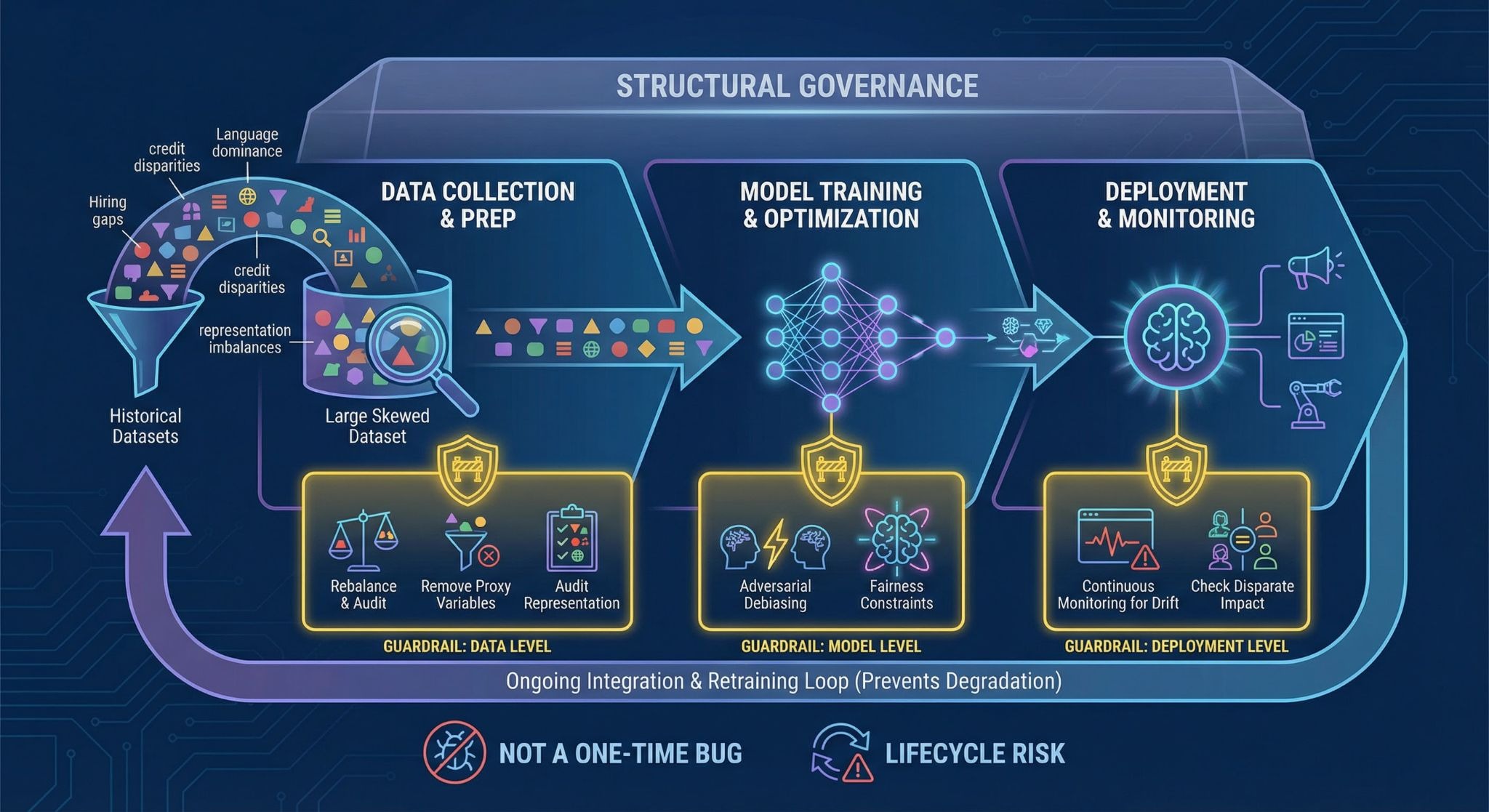
They’re not a single tool. Not a checklist. They’re layered controls that intervene at different points in the machine learning lifecycle — before training, during optimization, and after deployment.
Bias usually begins with data. Historical datasets reflect hiring gaps, credit disparities, language dominance, and representation imbalances. If a model trains on skewed distributions, it absorbs them. Large datasets don’t fix this automatically. They often magnify it.
This is where AI bias mitigation techniques operate.
At the data level, teams rebalance datasets, remove proxy variables, and audit demographic representation.
At the model level, fairness constraints or adversarial debiasing methods are introduced during training.
At the deployment level, outputs are monitored continuously for drift and disparate impact.
Mitigation is technical. Governance is structural. The two are not the same.
And without ongoing integration into broader AI risk management, fairness controls degrade over time — especially in systems that retrain or adapt dynamically.
Bias isn’t a one-time bug. It’s a lifecycle risk.
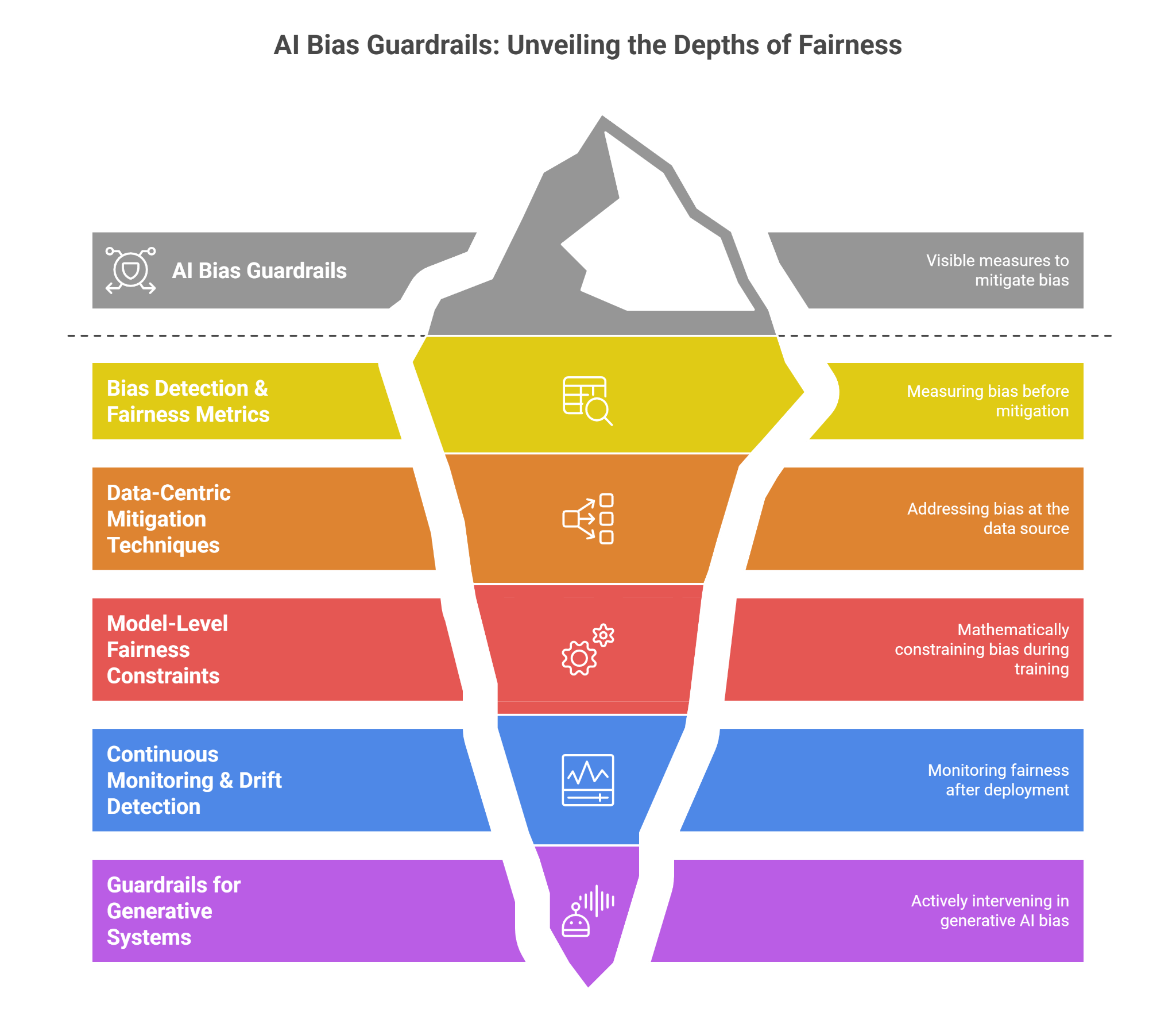
3. AI Bias Guardrails Implementation Approaches
There isn’t a single fix for bias. Effective AI bias guardrails combine measurement, correction, and continuous enforcement.
3.1 Bias Detection & Fairness Metrics
Before you mitigate bias, you have to measure it.
What this covers:
⮞ Demographic “parity” comparisons
⮞ Equalized odds testing
⮞ False positive / false negative rate gaps
⮞ Disparate impact ratio analysis
Why it matters:
Different metrics surface different fairness failures. A model can satisfy one metric and still discriminate under another. Over-reliance on a single fairness score is a common mistake.
3.2 Data-Centric Mitigation Techniques
Most bias starts upstream.
What this covers:
⮞ Rebalancing underrepresented groups
⮞ Synthetic data augmentation
⮞ Removing proxy features (e.g., ZIP code as income proxy)
⮞ Structured dataset audits before training
Why it matters:
If the training data is skewed, the model will reflect it — regardless of architecture. Many AI bias mitigation techniques fail because they attempt to correct bias after it has already been learned.
3.3 Model-Level Fairness Constraints
Bias can be mathematically constrained during training.
What this covers:
⮞ Constrained optimization for fairness thresholds
⮞ Adversarial debiasing layers
⮞ Post-processing calibration across demographic groups
⮞ Accuracy–fairness tradeoff analysis
Why it matters:
Yes, fairness constraints can affect accuracy. But the real question is: accuracy for whom?
3.4 Continuous Monitoring & Drift Detection
Why do fairness systems fail after launch?
Because deployment changes behavior.
What this covers:
⮞ Live fairness dashboards
⮞ Alert thresholds for demographic performance gaps
⮞ Retraining triggers
⮞ Periodic model audits
This is where AI guardrails become operational, not theoretical.
3.5 Guardrails for Generative Systems
bias in generative AI behaves differently. It appears in text tone, assumptions, role associations, and output framing.
What this covers:
⮞ Prompt-level bias testing
⮞ Output moderation layers
⮞ Red-teaming for stereotype generation
⮞ Fine-tuning using balanced reinforcement data
Generative systems require active intervention. They don’t “self-correct.”
4. How AI Bias Guardrails Fail in Practice
Here’s the uncomfortable part: most fairness systems don’t collapse dramatically. They erode quietly.
A team runs demographic parity tests before launch. Numbers look acceptable. The model ships. Months later, performance drifts — not across overall accuracy, but across subgroups. No one notices because fairness wasn’t wired into live monitoring. The guardrail existed. It just wasn’t operational.
Another common failure? Treating one fairness metric as definitive. A model might equalize average outcomes while still producing higher false positives for one demographic group. On paper, it passes. In reality, it harms.
Then there’s process inflation. Organizations build review committees, approval templates, and policy documents under the banner of ethical AI compliance. But if those reviews don’t influence the training loop or retraining triggers, they remain procedural.
Generative systems introduce another wrinkle. Structured bias tests don’t always surface subtle stereotype reinforcement. Patterns emerge only through open-ended prompts and real usage.
Guardrails fail when they become static. Bias doesn’t.
5. Current Approaches and How They Can Be Better
A lot of teams think they’re covered because they ran a fairness test once.
Pre-deployment audits are common now. A model gets evaluated, a report is generated, and leadership signs off. Then the system goes live and evolves — new users, new data, new retraining cycles. The fairness snapshot quickly becomes outdated.
Another pattern: heavy governance layers with light technical enforcement. Policies exist. Review committees meet. Documentation is thorough. But if findings don’t translate into code-level adjustments or retraining triggers, behavior doesn’t change. That’s where ethical AI compliance drifts into optics.
Monitoring tools are improving, yet many dashboards track fairness passively. Metrics move, but no automated threshold forces action. Human review becomes optional — and optional controls get deprioritized.
Durable systems embed AI bias mitigation techniques directly into pipelines and couple them with real-time AI bias guardrails. Fairness shouldn’t rely on periodic attention. It should be continuously enforced by design.
Better systems feel less ceremonial — and more operational.
6. Recommendations for Organizations
Start earlier than you think you need to.
Fairness shouldn’t be introduced after a model is trained. Embed AI bias mitigation techniques during dataset design and feature engineering. If imbalance is visible before training, correct it before the model learns it.
Assign ownership. Not abstract responsibility — named technical leads accountable for fairness metrics in production. When everyone owns it, no one does.
Integrate bias controls into release gates. A model should not move to production unless predefined “thresholds” tied to AI bias guardrails are satisfied. And those thresholds must trigger action if they drift post-deployment.
Tie fairness monitoring into broader AI risk management systems. If risk dashboards track performance, security, and reliability, fairness belongs there too.
Finally, align technical enforcement with ethical AI compliance requirements. Regulations are tightening. Systems built with measurable fairness controls will adapt faster than those built on documentation alone.
Engineering fairness isn’t optional anymore. It’s infrastructure.

7. Conclusion
Bias doesn’t enter AI systems dramatically. It seeps in — through datasets, feature choices, optimization goals, and unchecked deployment cycles.
That’s why AI bias guardrails can’t be treated as add-ons. They are structural controls that determine whether systems scale fairness or amplify inequity. Policies alone won’t do it. Neither will one-time audits.
The organizations that take AI bias mitigation techniques seriously build them into pipelines, monitoring layers, and retraining triggers. They treat fairness the way they treat security — as non-negotiable infrastructure.
As regulatory scrutiny increases and public expectations sharpen, engineered fairness will separate resilient systems from fragile ones.
Ethics discussed in board rooms matters.
But ethics “encoded” in systems is what lasts

"AI bias guardrails are essential, not optional"






Build Fair AI Today

.png)
.png)
.png)



