.svg)
AI guardrails for the Frontier Era: Building Global Defenses Against Existential Risk

.png)
Key Takeaways
1. Introduction
Something changed over the last two years.
Model upgrades stopped feeling incremental. Each release began outperforming expectations—solving harder reasoning tasks, writing production-level code, and coordinating across tools. The jump wasn’t cosmetic. It altered what these systems could actually do.
Frontier AI systems now operate across modalities. They plan. They execute multi-step tasks. Some can even chain tools together with minimal human input. That kind of capability doesn’t just improve productivity—it expands the blast radius of failure.
And here’s the uncomfortable part: capability has moved faster than oversight.
Governance models that worked for earlier AI deployments were built for chatbots and narrow systems. Frontier systems behave differently. They scale globally within weeks. They get integrated into finance, healthcare, defense research, and infrastructure. When something goes wrong, it doesn’t stay local.
This widening gap is exactly why AI guardrails for frontier AI cannot be treated as feature add-ons. They are structural defenses. Without them, safety becomes reactive—and in the frontier era, reactive is too late.
2. Understanding AI Guardrails for Frontier AI
So what exactly are AI guardrails for Frontier AI?
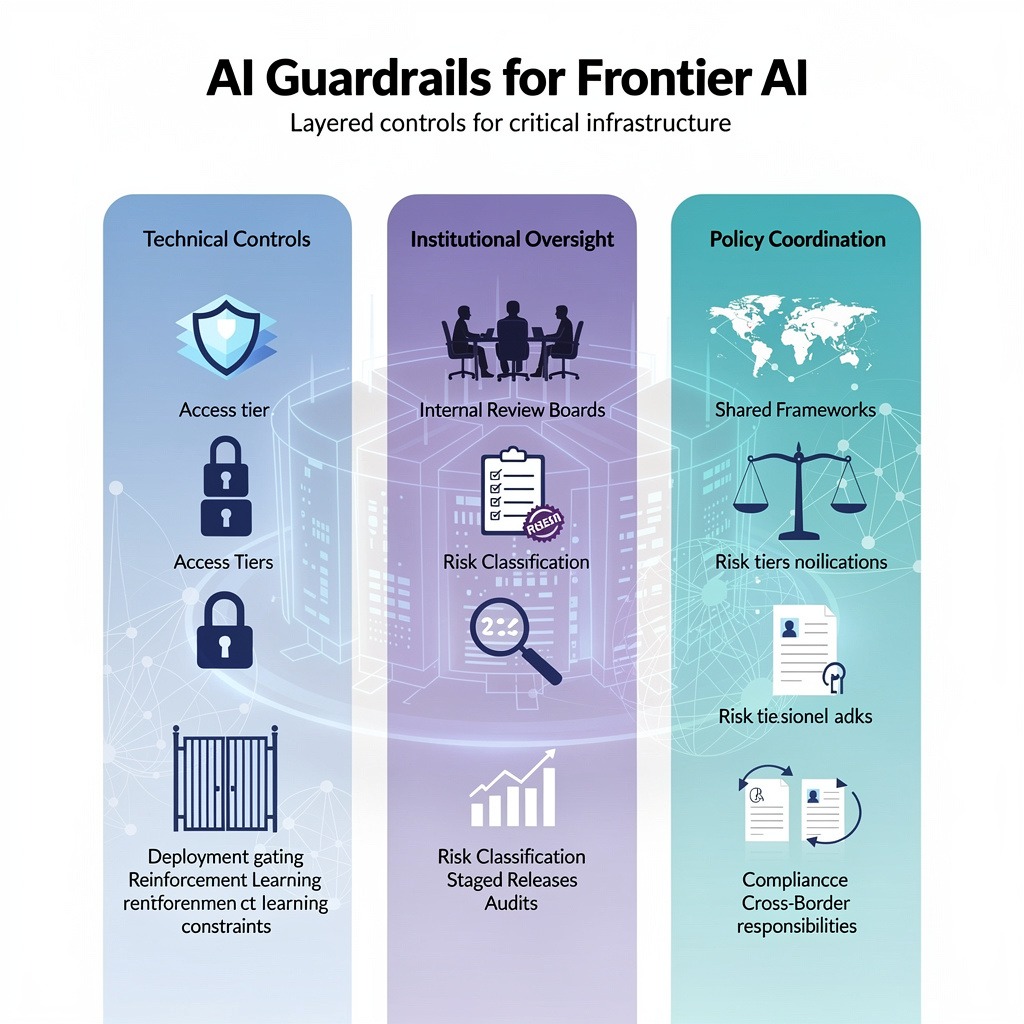
They aren’t a single safety filter or moderation layer. They’re layered control systems designed for models whose capabilities can shift quickly—sometimes unpredictably.
At a minimum, effective guardrails operate across three pillars.
First: technical controls.
These include access tiering, deployment gating, reinforcement learning constraints, and embedded safety rules. Some labs use structured alignment methods, which we often call AI alignment guardrails, to shape how models respond under stress or adversarial prompts. But alignment alone isn’t enough. Controls must also restrict what models can do in practice, not just what they’re trained to prefer.
Second: institutional oversight.
Internal review boards, documented risk classifications, staged release protocols, and independent AI safety audits all fall here. Frontier systems require structured evaluation before and after deployment. Informal reviews don’t scale.
Third: policy coordination.
This is where AI safety frameworks come in. They define risk tiers, compliance requirements, audit obligations, and cross-border responsibilities. Without shared frameworks, safety becomes fragmented, and fragmentation is where risk multiplies.
Earlier AI systems could be governed like software. Frontier AI behaves more like critical infrastructure.
That distinction changes everything.
3. AI Guardrails for Frontier AI Implementation Approaches
Designing AI guardrails for frontier AI is no longer optional research work. It’s operational risk management. The labs building frontier systems already know this. The real issue is depth and consistency.
Below are four implementation layers that matter most.
3.1 Pre-Deployment Capability Evaluations
Frontier models should be evaluated the way we test aircraft or nuclear facilities—under stress, not in ideal conditions.
What this covers:
⮞ Dangerous capability testing (cyber, biological, autonomous task chains)
⮞ Structured external red-teaming
⮞ Risk tier classification before public release
⮞ Staged deployment with limited access groups
⮞ Defined no-release thresholds
Why it matters:
If dangerous capabilities are discovered after release, the damage is already distributed. Serious AI risk prevention begins before the system reaches users.
3.2 Continuous Monitoring & AI Safety Audits
Safety doesn’t freeze at deployment.
What this covers:
⮞ Independent AI safety audits
⮞ Behavior logging and anomaly detection
⮞ Incident escalation channels
⮞ Periodic re-evaluation after model updates
⮞ Transparent reporting standards
Why it matters:
Frontier models change. Fine-tuning, integrations, plugins, and all of it shift behavior. Independent audits strengthen frontier AI safety because internal teams can miss subtle drift over time.
3.3 Alignment Enforcement & Technical Constraints
Training alignment is only the first step. Enforcement must happen at runtime.
What this covers:
⮞ Reinforcement learning safety tuning
⮞ Rule-based constitutional constraints
⮞ Hard inference-time policy layers
⮞ Rate limits and capability gating
⮞ Isolated environments for high-risk tool access
These are practical AI alignment guardrails. They restrict escalation pathways even when users push systems aggressively.
3.4 Compute Governance & Global Coordination
Frontier AI depends on extreme compute concentration. That creates a governance lever.
What this covers:
⮞ Licensing advanced training clusters
⮞ Monitoring high-end chip distribution
⮞ Shared international evaluation standards
⮞ Cross-border incident reporting
⮞ Emergency coordination protocols
Compute oversight strengthens systemic AI risk prevention because it limits who can replicate frontier-level capability at scale.
Internal guardrails help. Global coordination makes them durable.
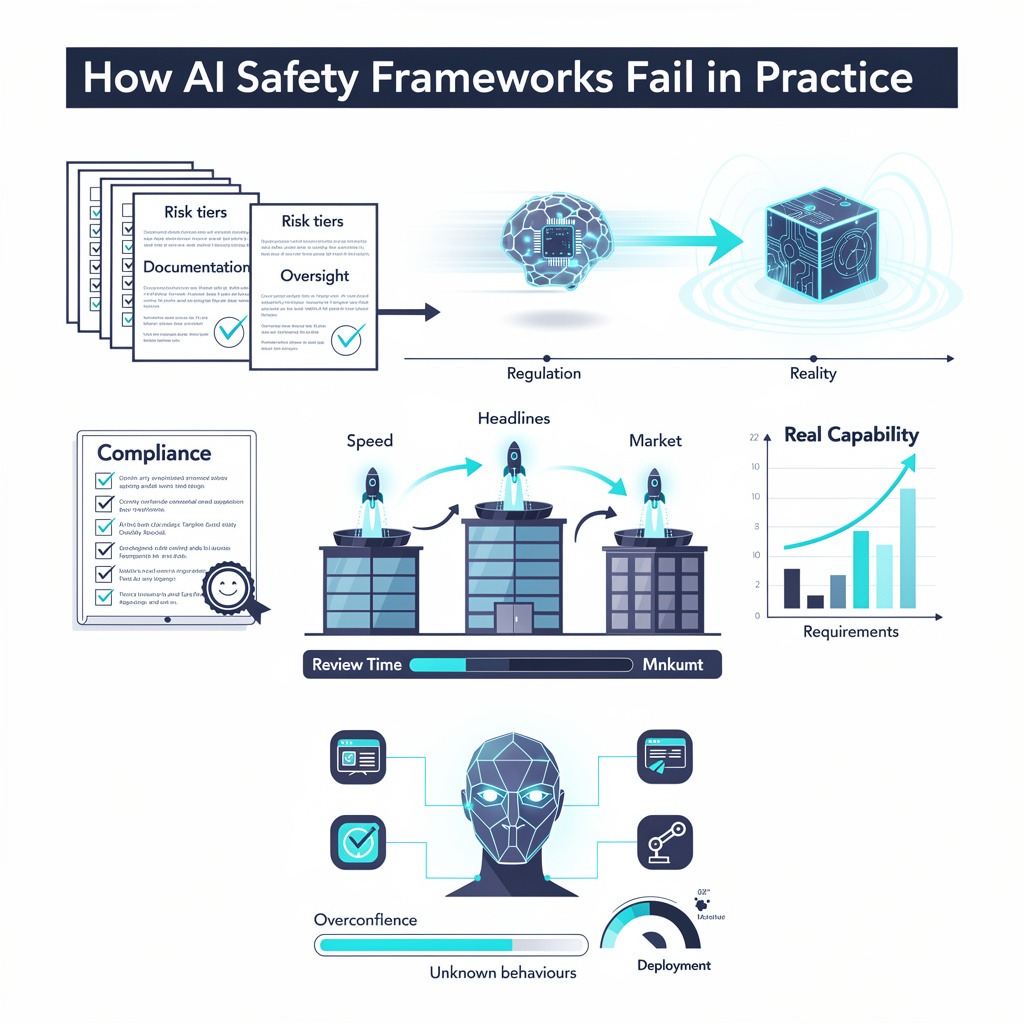
4. How AI Safety Frameworks Fail in Practice
On paper, most AI safety frameworks look solid. Risk tiers. Documentation. Oversight committees. Review cycles.
Reality is messier.
The first crack usually appears in timing. Frontier systems evolve quickly—sometimes unpredictably. Oversight doesn’t. By the time regulators define what counts as “high risk,” capability has already moved. Compliance becomes backward-looking.
Where does AI risk prevention actually fail in that scenario?
It fails when teams focus on satisfying requirements instead of measuring real-world capability. A model can pass documentation checks while quietly becoming more capable in ways no checklist anticipated.
Then there’s competition.
Why do safeguards soften under pressure?
Because speed wins headlines. When one lab releases a stronger system, others feel the pull. Review timelines shrink. Deployment gates widen. The conversation shifts from “Is this safe?” to “Are we falling behind?”
That tension directly affects frontier AI safety. The faster the rollout, the less time there is for external challenge.
And finally—overconfidence.
Alignment reduces obvious misuse. It does not eliminate unknown behaviors. Frontier systems integrated with tools, plugins, or autonomous loops can behave differently than they did in controlled tests.
This is where strong AI guardrails for frontier AI matter most—not when things are predictable, but when they aren’t.
5. Current Approaches and How They Can Be Better
Right now, most frontier labs rely on a mix of voluntary commitments, internal review boards, and staged releases. It’s a start. But it isn’t durable.
Voluntary pledges signal intent. They don’t create accountability. For AI safety frameworks to hold under pressure, standards must be enforceable, with measurable thresholds, audit rights, and consequences for non-compliance.
Internal red-teaming is common. The limitation? Familiarity. Teams that build systems often share assumptions. Independent AI safety audits introduce friction, and that friction is healthy. It exposes blind spots before they scale.
National regulations are emerging, but they vary widely. Fragmented rules weaken systemic AI risk prevention because capability doesn’t respect borders. Frontier development happens globally. Oversight must as well.
Stronger coordination, enforceable standards, and external review mechanisms are what turn safety intent into structural protection.
6. Recommendations for Organizations
Frontier AI changes the risk equation. So the response can’t be procedural. It has to be structural.
First, stop treating safety as a post-training checklist. The most capable systems need built-in escalation controls—staged releases, capability thresholds, and clear kill-switch authority. That’s what real AI guardrails for frontier AI look like in practice: not policies on paper, but constraints embedded into deployment decisions.
Second, bring in outsiders. Teams that design a model often share the same mental map of its behavior. Independent AI safety audits disrupt that comfort. They ask questions internal reviewers might not. That discomfort is protective.
Third, design governance with interoperability in mind. Regulations will keep evolving. Organizations already aligned with credible AI safety frameworks won’t need to rebuild their systems every time a new rule appears.
And finally—build people, not just processes. Frontier risk isn’t generic compliance work. It requires specialists who understand evaluation limits, model drift, and the edge cases that don’t show up in standard benchmarks.
If capability is scaling exponentially, oversight cannot grow linearly.
7. Conclusion
The frontier era isn’t defined by model size. It’s defined by uncertainty.
We are building systems whose capabilities can expand faster than our assumptions about them. That alone changes the stakes. When intelligence scales quickly, so does impact—positive and negative.
This is why AI guardrails for frontier AI should be treated as core infrastructure. Not an ethics add-on. Not a branding exercise. Infrastructure.
Strong AI safety frameworks create shared standards. Independent scrutiny strengthens resilience. Institutional maturity slows reckless acceleration. None of this guarantees perfection. But it narrows the margin for catastrophic error.
The real risk isn’t that frontier AI becomes powerful. It’s that it becomes powerful without proportionate restraint.
Global coordination will determine which future we get.

Guardrails are the seat belts of civilization: we need smarter safety, not slower AI






Protect your models before they become weapons.

.png)
.png)
.png)



