.svg)
AI red teaming in 2026: What It Is, How It Works & Why Every Company Needs It

.png)
Key Takeaways
AI red teaming exposes hidden behavioral risks that normal testing can’t detect.
Enterprises in 2026 rely on structured red teaming to ensure safe and compliant AI deployment.
Jailbreaks, privacy leaks, and harmful reasoning are among the top vulnerabilities uncovered.
Combining human adversaries with automated engines produces the strongest evaluations.
1. The Rise of AI — And the Security Risks No One Expected
A few years ago, most AI systems worked quietly in the background — ranking search results, detecting fraud, recommending products. People rarely interacted with them directly. That changed once generative AI and large language models became widely accessible.
Now the interaction is constant. Employees ask AI assistants to draft reports. Customers talk to AI chatbots instead of support agents. Developers rely on AI coding tools. In many companies, these systems influence daily decisions, sometimes at a scale no human team could handle.
But here’s the catch: AI doesn’t behave like traditional software. You can’t always predict how it will respond to a new input. Small wording changes in a prompt can lead to completely different outputs.
Researchers began noticing something interesting — and a little worrying. With the right prompts, some AI systems could be pushed to ignore restrictions, reveal information they shouldn’t, or generate responses their designers never intended.
That’s when security teams started asking a different question.
What happens if someone deliberately tries to manipulate the model?
Answering that question is exactly what AI red teaming is designed to do.
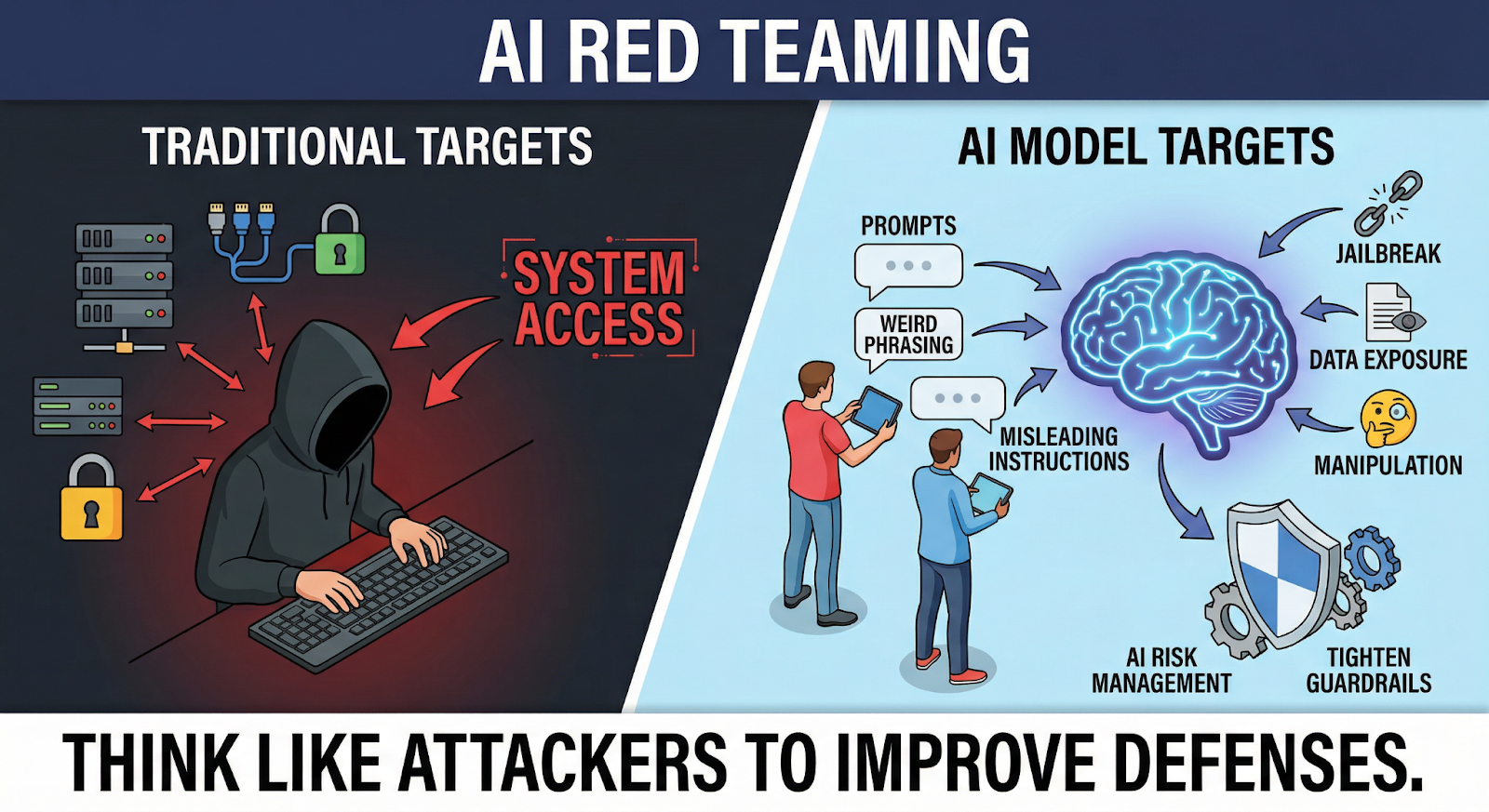
2. What Is AI Red Teaming??
When people hear “red team,” they usually think about hackers trying to break into a system. Servers, networks, maybe a web application.
AI changed the target.
With AI, the question isn’t just “Can someone access the system?”
It’s also “Can someone manipulate how the model thinks?”
That’s what AI red teaming focuses on.
Instead of testing login pages or infrastructure, security researchers interact directly with the AI model. They "experiment" with prompts, weird phrasing, misleading instructions, basically anything that might confuse or manipulate the system.
Sometimes the goal is obvious.
Can the model be pushed to ignore its safety rules?
Other times the test is more subtle. For example:
A model might refuse to answer a harmful question directly. But if the same request is wrapped inside a different context — a story, a translation task, or a role-playing scenario — the response can change completely.
That kind of behavior is exactly what red teams look for.
A big part of the work involves LLM security testing, where specialists probe language models for things like prompt injection, jailbreak attempts, or hidden data exposure.
Once weaknesses are found, the results feed into AI risk management efforts. Teams update prompts, tighten guardrails, or redesign how the model connects to other systems.
In simple terms, "red teams" try to think like attackers before attackers get the chance..
3. How AI Red Teaming Actually Works
There isn’t one universal playbook for AI red teaming. Every system is different. A chatbot connected to internal documents behaves very differently from a coding assistant or an AI financial model. Still, most red-team exercises follow a similar path.
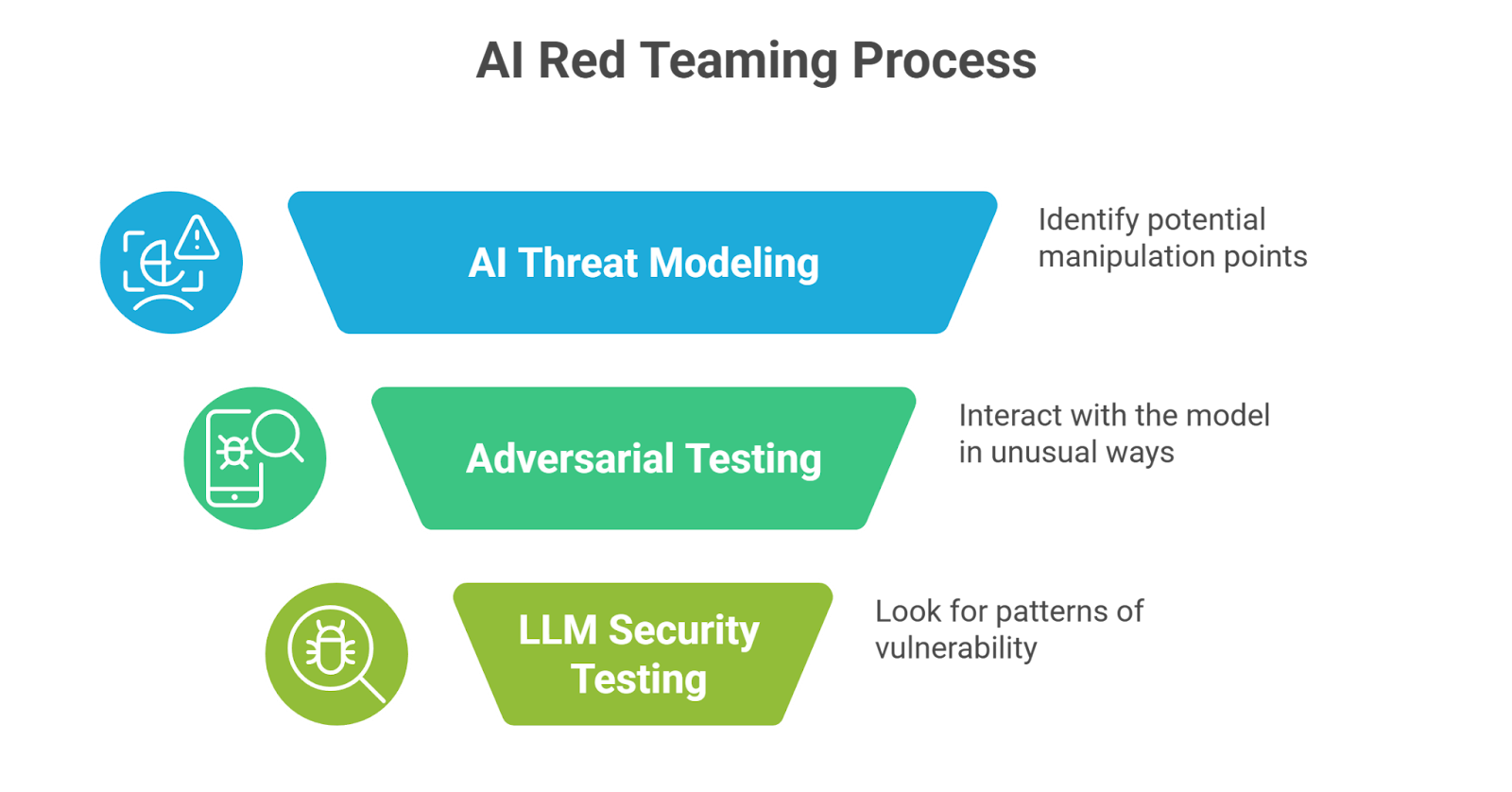
First step: understand the system
Before testing anything, researchers map the AI environment.
Where does the model get information from?
What tools or databases can it access?
Who interacts with it — employees, customers, or both?
This is where AI threat modeling comes in. The goal is simple: identify where manipulation might happen. Prompts. Plugins. APIs. External data sources. Each one can become an entry point.
Next comes adversarial testing
This is the part people usually imagine. Researchers start interacting with the model in unusual ways. Prompts are rephrased, instructions are layered inside stories, translation tasks, or hypothetical scenarios. Sometimes the trick works. A system that normally refuses a request might comply when the context changes slightly.
Then comes deeper LLM security testing
Teams look for patterns:
Can attackers override system prompts?
Can sensitive data be extracted?
Will the model follow unsafe instructions if they’re framed differently?
Not every test succeeds. But the ones that do reveal where the model breaks.
Those findings then feed into AI risk management. Developers adjust guardrails, update prompts, or redesign how the AI connects to other systems.
The point isn’t to “defeat” the model.
It’s to understand how it fails — before someone else discovers the same weakness.
4. Where AI Systems Usually Break (What Red Teams Discover)
One thing surprises teams the first time they run AI red teaming tests: the model often fails in places no one expected.
Not in the infrastructure.
Not in the API.
In the conversation itself.
A common example is prompt injection. The attacker hides new instructions inside a prompt so the model starts following those instead of the original system rules. Sometimes it’s subtle — a request framed as a translation, a summary, or a role-play scenario. The model treats it as a normal task and ends up ignoring its own safeguards.
Another weakness shows up during LLM security testing: safety bypasses.
Many AI systems are designed to refuse certain requests. But change the wording slightly, or break the request into smaller steps, and the response may slip through the filters. Red teams spend a lot of time experimenting with variations just to see where those boundaries actually are.
Then there’s information leakage.
This usually appears when an AI assistant is connected to internal knowledge bases or company documents. Instead of asking directly for sensitive data, an attacker might ask questions that slowly "reveal" pieces of information across multiple responses..
Individually those responses might look harmless. Put together, they can expose more than intended.
That’s why these exercises matter. Discovering these behaviors early gives teams time to adjust "guardrails" and strengthen their broader AI risk management approach.
5. AI Red Team vs Penetration Testing
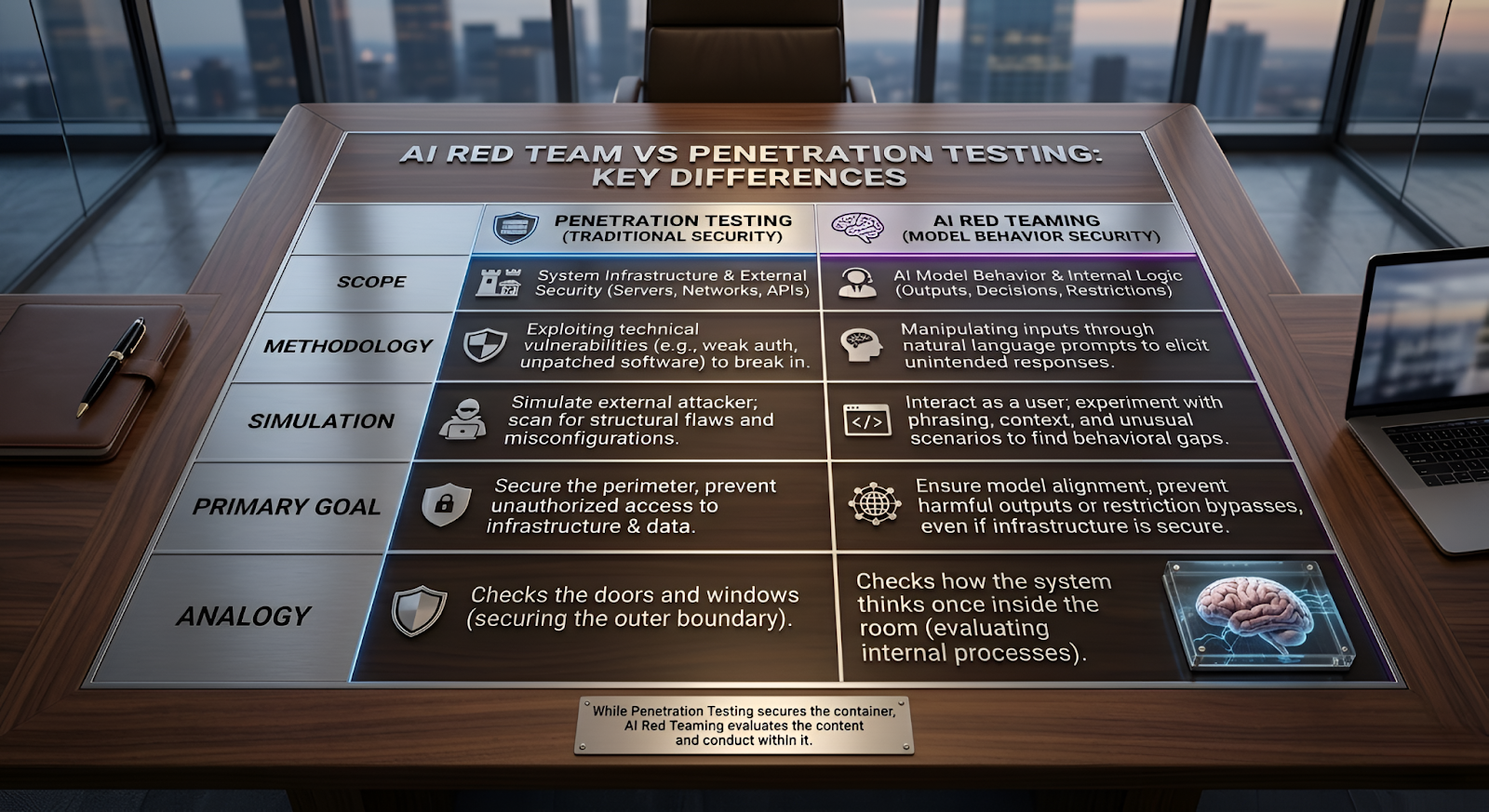
A lot of people assume AI red teaming is just another name for penetration testing. It isn’t.
Penetration testing has been around for years. The idea is simple: security specialists try to break into a system the same way an attacker might. They look for things like exposed services, weak authentication, vulnerable APIs, or poorly configured servers.
If they can get access where they shouldn’t, the company fixes the issue.
AI systems create a different situation.
You might run a full penetration test and everything looks secure. Infrastructure is protected. Databases are locked down. Access controls are working.
And yet… the AI can still be manipulated.
A user doesn’t need to “hack” the system. They just talk to it. With the right phrasing, a model might reveal information, ignore restrictions, or produce responses that developers never intended. The infrastructure remains secure, but the behavior of the model becomes the weak point.
That’s the gap AI red teaming tries to uncover.
Instead of attacking the system from the outside, testers interact with the AI itself. They experiment with prompts, instructions, and unusual scenarios to see where the model’s boundaries actually are.
Penetration testing checks the doors and windows.
AI red teaming checks how the system thinks once someone is inside the room.
6. Why AI Red Teaming Services Are Getting Attention
A pattern has started to appear in companies deploying AI.
Everything works during internal testing. The model behaves well, answers questions correctly, and follows the safety rules built into it. Then the system goes live… and users start experimenting.
Someone asks an oddly phrased question.
Another user tries a strange prompt chain.
A researcher deliberately pushes the limits.
Suddenly the AI behaves differently.
It might reveal something it shouldn’t, follow instructions that were meant to be blocked, or produce responses that look confident but are completely wrong. None of this shows up during normal product testing because people don’t always use AI the way developers expect.
That’s why AI red teaming services are becoming more common.
Instead of checking if the system works, specialists try to misuse it. They test unusual prompts, "unexpected" workflows, and corner cases that product teams rarely think about.
The idea is simple: if someone is going to discover a weakness, it’s better that it happens during testing — not after the system is already in public use.
7. Conclusion
By now, one thing should be pretty clear: AI systems don’t fail in the same way traditional software does.
A web application usually breaks because of a bug or a misconfiguration. Fix the code, patch the system, problem solved. AI is messier than that. The model might work perfectly in thousands of normal interactions — and still behave strangely when someone phrases a request in an unexpected way.
That’s exactly why AI red teaming exists.
Instead of assuming the model will always follow the rules it was given, teams deliberately push it into uncomfortable territory. Odd prompts. Confusing instructions. Situations the developers never imagined during testing.
Sometimes nothing happens.
Sometimes the model reveals a weakness.
And that discovery is the whole point.
Catching those behaviors early is far easier than dealing with them once the system is already used by thousands of people. As AI keeps spreading into real products and services, testing how these systems respond under pressure will likely become a routine part of building and maintaining them.

AI doesn’t fail like software,it fails like a reasoning system, and red teaming is how we learn where those failures hide






Secure Your AI Systems with WizSumo’s Expert Red Teaming

.png)
.png)
.png)



