.svg)
AI Red Teaming in Automotive & Autonomous Systems : Testing Safety-Critical AI

.png)
Key Takeaways
AI red teaming exposes how autonomous vehicle AI fails in real-world conditions.
Self-driving car security risks stem from confident AI decisions, not crashes.
AI security testing in automotive must test model behavior, not just software.
AI hallucinations in autonomous systems are silent risks without adversarial testing.
Continuous AI red teaming is key to safe and trusted autonomous mobility.
1. Introduction
Stand next to a modern vehicle with advanced driver assistance, and you’re really standing next to a rolling perception system. Cameras scan lane markings. Radar tracks moving objects. Some prototypes add LiDAR to build a rough 3-D view of the street. Behind the scenes, machine-learning models try to answer dozens of questions every second: Is that a pedestrian stepping off the curb? Is the vehicle ahead slowing down? Should the car brake or steer?
Usually, the system gets it right, and the driver never notices. But when the AI misinterprets something on the road, the error isn’t abstract. It shows up as a missed obstacle, a delayed brake, or a confused steering decision. That’s exactly why engineers have begun to treat AI safety testing for autonomous vehicles as a safety discipline rather than a purely technical exercise.
A case that shook the industry happened in 2018 in Tempe, Arizona. An autonomous test vehicle from Uber struck a pedestrian walking a bicycle across the road at night. According to investigators, the system detected an object but kept changing its classification—first a vehicle, then something else—before impact. The vehicle never triggered emergency braking in time.
Incidents like this pushed many researchers to rethink how these systems are evaluated. Traditional validation assumes the model behaves correctly under normal conditions. AI red teaming in automotive flips that assumption. Instead of proving the system works, testers try to break it—by introducing unusual inputs, unusual traffic patterns, and edge cases that might expose weaknesses in perception or decision models.
For companies developing autonomous driving systems, strengthening autonomous-vehicle AI security is quickly becoming as important as performance or comfort features.
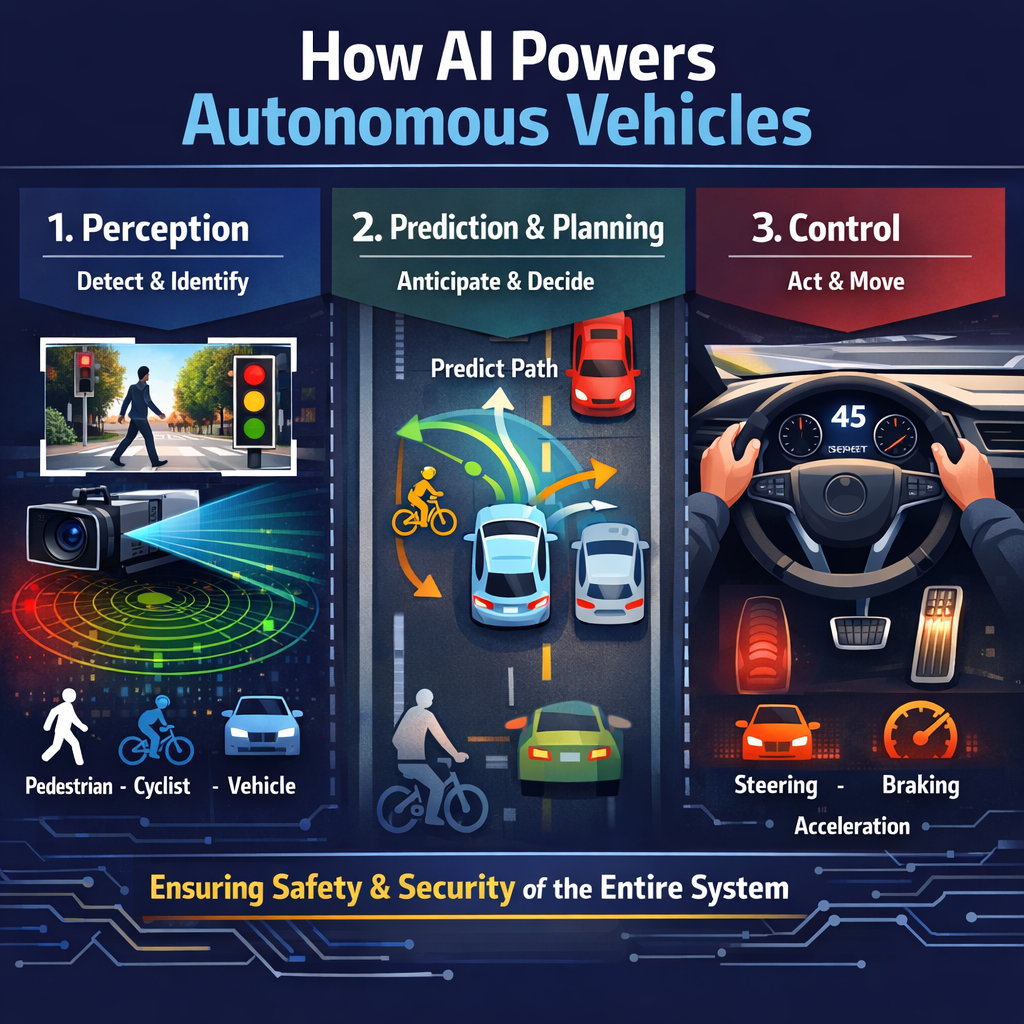
2. How AI Powers Autonomous Vehicles
Ask someone how a self-driving car works, and you’ll usually hear something like, “AI drives the car.” That’s partly true—but the reality is a lot messier. The intelligence inside these systems is spread across several layers of software, each responsible for a different job. Think of it less like one brain and more like a chain of specialists passing information along.
The process usually starts with perception. This is where the vehicle tries to figure out what’s happening around it. Cameras read road signs and lane markings. Radar keeps track of how close other vehicles are. Some platforms add LiDAR, which helps build a three-dimensional picture of the street. Machine-learning models combine those inputs and label objects: pedestrian, bicycle, truck, and traffic signal.
Once the system has a rough understanding of the environment, another layer kicks in—the prediction and planning stage. Here, the software tries to anticipate what nearby road users might do next. A car ahead might slow down. Someone standing on the curb might step into the road. Based on those possibilities, the system calculates a safe path forward.
Finally, the control layer turns that decision into action. Steering adjustments, braking, and acceleration happen in small continuous updates.
When everything works, the transition between these layers feels seamless. But if an early step misreads the environment, the rest of the pipeline can react to the wrong information. That’s why engineers increasingly emphasize automotive AI security testing as part of vehicle development. Protecting autonomous vehicle AI security means examining the entire chain of decisions, not just individual components.
3. AI Red Teaming Use Cases in Automotive
When people imagine testing an autonomous vehicle, they usually picture controlled tracks and carefully designed driving scenarios. Clean lanes. Predictable traffic. Perfect visibility.
Reality is messier.
Road signs get scratched. Rain covers the cameras. Drivers behave in ways that no dataset designer expected. That’s the kind of environment red teams try to recreate when they run AI red teaming in automotive programs. The goal isn’t simply to confirm the system works. It’s to discover the situations where it doesn’t.
And sometimes the failures show up in places nobody initially expected.
3.1 Manipulated Road Signs
A stop sign should be the easiest thing for a perception system to recognize.
Bright red. Distinct shape. Clear meaning.
But research groups have shown that tiny visual changes can confuse computer vision models. A few stickers placed in strategic locations were enough in some experiments to alter how the model interpreted the sign. To a human driver, it still looked obvious. To the model, the pattern had shifted just enough to cause uncertainty.
That kind of result made many engineers rethink how perception models are evaluated. Clean training data isn’t enough. Real streets are full of imperfect signals, which is why AI safety testing for autonomous vehicles often includes deliberately altered visual inputs.
3.2 Sensor Spoofing Experiments
Vision models are only part of the picture. Autonomous vehicles also rely on radar and sometimes LiDAR to measure distance and movement.
Researchers started asking a simple question: What happens if those signals are manipulated?
In controlled experiments, spoofed reflections have been used to create objects that appear real to the perception pipeline. Not easy to do outside research environments—but still revealing. If a sensor reports something that isn’t there, the rest of the system has to decide whether to trust it.
Those experiments pushed the conversation around autonomous vehicle AI security far beyond traditional software vulnerabilities.
3.3 Rare Driving Situations
Some failures aren’t attacks at all.
They’re just weird moments.
A pedestrian is walking diagonally across an intersection while looking at their phone. A truck stopped halfway into a lane while unloading. Temporary construction barriers redirecting traffic in ways the map never predicted.
Humans improvise. Machine learning systems rely on patterns they’ve seen before. When a situation falls outside those patterns, hesitation can appear in the decision pipeline.
That’s exactly the type of scenario red teams like to explore.
3.4 Safety System Stress Tests
Most autonomous driving stacks include backup safety layers. These systems monitor the primary driving model and intervene if something looks wrong.
At least, that’s the idea.
Red teams often trigger unusual perception outputs just to see how the safety layer reacts. Does it slow the vehicle? Hand control back to a human driver? Ignore the anomaly?
The timing matters. If the response comes a few seconds too late, a small upstream error can cascade into something much more serious.
3.5 Training Data Integrity Testing
Another place problems can hide is the training data itself.
Machine learning models inherit the biases and blind spots of their datasets. If certain environments are underrepresented—night driving, unusual weather, rare road layouts—the system may struggle when it encounters them later.
Security teams increasingly audit datasets for exactly this reason. Evaluating training pipelines has become a core piece of automotive AI security testing.
3.6 Simulation-Based Adversarial Testing
There’s also a practical constraint. Some dangerous scenarios simply cannot be recreated safely on public roads.
Simulation environments fill that gap.
Engineers can generate thousands of unusual driving situations—heavy rain, sudden pedestrian movement, and unpredictable traffic flows. Most of these cases are rare. Some may occur only once in millions of miles of driving.
But when they do appear, the vehicle still needs to respond correctly.
Simulation makes it possible to test those moments before they happen in the real world.
4. How Autonomous Vehicle AI Fails Under Adversarial Pressure
Most failures in autonomous driving systems don’t appear during routine testing. They show up when something unusual happens—a confusing visual pattern, a misleading sensor signal, or a training bias the model quietly inherited months earlier. Engineers studying autonomous vehicle AI security tend to see the same categories of weaknesses surface again and again.
Adversarial Sign Manipulation
One of the earliest demonstrations involved traffic sign recognition. Vision models are trained to recognize shapes and color patterns that correspond to specific signs. But those models do not interpret images the same way humans do. In several academic experiments, researchers modified stop signs with small stickers or patterns that altered how image features were detected. The sign still looked like a stop sign to people standing nearby. Yet the model sometimes interpreted it differently. The problem wasn’t the sign itself—it was the way the neural network processed visual features.
Sensor Spoofing
Sensors introduce another layer of risk. Cameras can be affected by strong light sources or unusual reflections, while radar and LiDAR rely on signals that can theoretically be manipulated. Researchers have demonstrated that carefully crafted signals can produce phantom objects inside perception pipelines during controlled tests. When that happens, the system may react to something that does not exist or fail to react to something that does. Experiments like these are why discussions about AI safety testing for autonomous vehicles increasingly include sensor robustness.
Data Poisoning and Model Drift
Some vulnerabilities appear much earlier in the development process. Machine learning systems learn from enormous datasets collected over months or years. If a portion of that data is mislabeled or manipulated, the model can inherit subtle errors that only appear under specific conditions. Over time, models may also drift as road environments change or new edge cases appear. That’s one reason teams conducting AI red teaming in automotive environments often evaluate training pipelines in addition to deployed systems.
Failures rarely come from a single source. More often, they appear when multiple weaknesses intersect—perception uncertainty, unusual sensor readings, and a planning system forced to react with incomplete information.

5. Why Traditional Testing Misses These Vulnerabilities
For decades, “automotive testing” followed a fairly predictable formula. Engineers defined scenarios, ran vehicles through those scenarios repeatedly, and verified that the software behaved as expected. That method works well when systems follow fixed rules. Autonomous driving software doesn’t always behave that way.
Machine-learning models respond to patterns in data rather than explicit instructions. A perception system might correctly identify a pedestrian thousands of times and still hesitate when the lighting changes or the angle looks unusual. From a traditional testing perspective, the system passed. From a safety perspective, that single edge case matters.
Another complication is the sheer variety of real roads. Weather shifts. Road markings fade. Drivers make unpredictable decisions. No validation program can realistically cover every possible situation a vehicle might encounter over the years of driving. Many of the most interesting failures appear only when the environment looks slightly different from the training data.
There is also a mindset issue. Conventional validation assumes the environment behaves normally. It checks whether the system works when everything is functioning the way designers expect. Adversarial conditions rarely enter the picture. That gap is one reason development teams now add continuous automotive AI security testing alongside traditional validation. It forces the system to face unusual inputs long before it encounters them outside the lab.

6. Conclusion
When engineers first began experimenting with autonomous driving systems, most attention went to performance. Could the vehicle recognize pedestrians? Could it stay within lane boundaries? Could it navigate busy streets without human help?
Those questions were important. But over time another question started appearing in safety discussions.
What happens when the system is wrong?
Machine-learning models are excellent at recognizing patterns they have seen before. The challenge appears when the road looks slightly different from those patterns—a damaged sign, a confusing intersection, or an unusual combination of weather and traffic. Those situations are not common, yet they matter the most.
This is where AI red teaming in automotive changes the testing mindset. Instead of assuming the environment behaves normally, engineers begin asking uncomfortable questions. What if the sensor data is misleading? What if the perception model hesitates? What if several small errors appear at the same moment?
Answering those questions is part of the broader effort around AI safety testing for autonomous vehicles. The objective isn’t to prove the system works perfectly. It’s to understand where the edges are—the points where the system needs stronger safeguards before it shares the road with millions of people.

“Autonomous AI doesn’t fail loudly, it makes confident decisions that go wrong.”






Build Safer Autonomous Vehicles Through AI Red Teaming with WizSumo

.png)
.png)
.png)



