.svg)
AI red teaming in banking: Critical Use Cases to Prevent High-Impact AI Failures

.png)
Key Takeaways
⮳ AI red teaming in banking focuses on how AI systems fail, not just how they perform.
⮳ Traditional model validation alone cannot detect adversarial AI risks.
⮳ High-impact banking AI systems must be tested under real-world misuse scenarios.
⮳ Adversarial testing helps banks uncover silent failures before regulators do.
⮳ Secure banking AI is the result of continuous red teaming, not assumptions of safety.
1. Introduction
Banks don’t “experiment” with AI anymore. They depend on it. Fraud models decide in milliseconds whether to block a payment. Credit systems determine loan approvals before a human ever reviews the file. Internal risk tools escalate customers based on pattern recognition most executives never see directly.
That works — until it doesn’t.
In 2023, the Dutch Central Bank issued warnings to financial institutions about risks in AI-driven credit models. The concern wasn’t "model accuracy scores". It was something harder to measure: explainability and "potential discrimination" embedded in automated decisioning. At the same time, European regulators were advancing the EU AI Act, making it clear that high-risk systems — including credit scoring — would face stricter oversight.
This changes the pressure on banks.
If a regulator asks why a model denied credit, “the algorithm said so” is not an answer. If a system embeds bias, the exposure isn’t just reputational — it’s supervisory. And if that model can be manipulated or probed, the risk compounds.
That’s why AI red teaming in banking is gaining urgency. It moves beyond validation checklists and actively tests how systems behave under stress — bias scenarios, adversarial inputs, edge cases. Real Banking AI security assumes models will be challenged. The only question is whether the bank finds the weakness first.

2. How AI Actually Runs Inside a Bank
Walk into any large bank and ask where AI is used. You won’t get one answer — you’ll get ten. Different teams. Different models. Different risk owners. But most of it clusters into a few pressure points.
First: fraud
Transaction monitoring models sit in the critical path of payments. Card swipes. Wire transfers. Account logins at 2:13 a.m. from a new device. The model scores it instantly. Approve or block. That speed is the advantage — and the weakness. Attackers don’t need to break the system. They just need to understand its thresholds. That’s where AI fraud detection vulnerabilities start showing up: small behavioral tweaks that slip past risk scoring.
Second: lending
Credit models decide who gets approved and at what rate. On paper, they’re statistical engines. In practice, they shape access to capital. When patterns correlate with protected characteristics — even indirectly — algorithmic bias in lending becomes more than a fairness debate. It becomes supervisory risk.
And then there’s generative AI
Banks are rolling out internal assistants, document summarizers, compliance copilots. Helpful tools. But expose them to the wrong input and prompt injection attacks can override instructions or surface restricted data.
Different systems. Same reality: they all influence financial outcomes. And they all create exposure if not deliberately stress-tested.
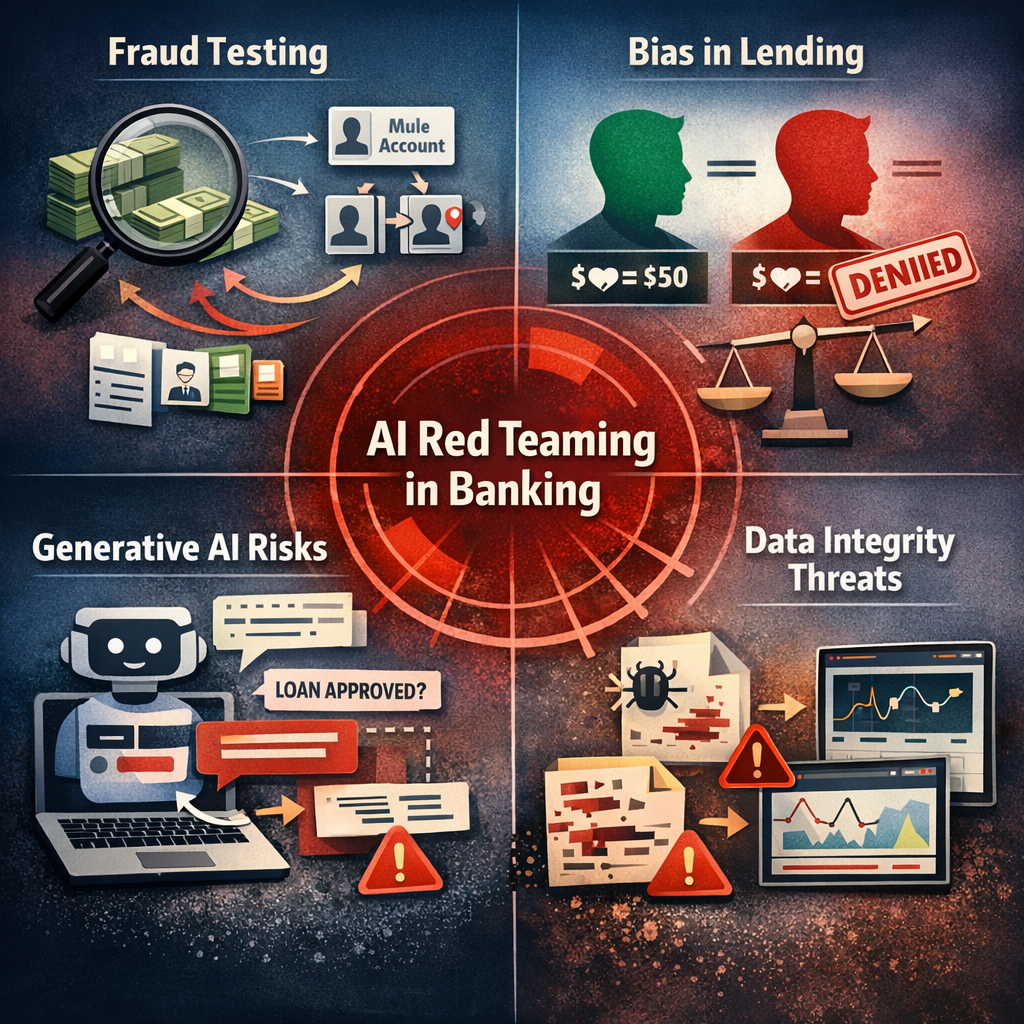
3. AI Red Teaming Use Cases in Banking
When a bank runs an AI red team, it’s not a slide deck exercise. It’s uncomfortable. You’re deliberately trying to make your own systems behave badly.
Start with fraud models.
On paper, they look solid. Accuracy scores are strong. False positives are within tolerance. But red teams don’t look at averages — they look at edges. They simulate slow, coordinated evasion. Small transaction increases. Device changes that mirror normal customer upgrades. Identity stitching across mule accounts. What they’re testing isn’t whether the model works. It’s whether someone patient can learn its rhythm.
That’s usually where AI fraud detection vulnerabilities surface — not in dramatic failures, but in narrow gaps where thresholds are predictable.
Now shift to lending.
Most underwriting teams believe bias is handled during validation. Statistical checks. Fairness metrics. Documentation. Then red teamers introduce counterfactual scenarios. Same income. Same debt. Slight changes in correlated variables. Or they stress profiles that sit just outside majority distributions.
Sometimes nothing happens. Sometimes the output swings more than anyone expected.
That’s when algorithmic bias in lending stops being theoretical. Under targeted stress, patterns emerge that aren’t visible in portfolio-level summaries. This is the moment where AI model governance in banks either holds up — or starts to look procedural rather than operational.
Then there’s generative AI.
Internal copilots, policy assistants, case summarizers. Helpful tools. But language is flexible. Red teams try indirect instructions. Nested prompts. Requests framed as compliance checks. That’s where prompt injection attacks start to show whether guardrails are actually enforced or just assumed.
One more angle that often surprises executives: data integrity.
What happens if training labels are subtly altered? If a pipeline ingests corrupted external data? If monitoring dashboards don’t flag gradual drift? You don’t need a Hollywood-style breach. Slow contamination works fine.
AI red teaming in banking isn’t about chaos. It’s controlled friction. You apply pressure and observe how the system responds. And sometimes, what you learn is uncomfortable.
4. How Banking AI Fails Under Adversarial Pressure
When these systems break, they rarely collapse all at once. They bend first. Quietly.
Model Evasion in Fraud Systems
What does model evasion actually look like in practice?
It’s not a hacker smashing through controls. It’s gradual probing. Attackers test transaction amounts, locations, device combinations. They learn which combinations score lower risk and replicate them at scale.
Fraud models are optimized for balance — stop crime, don’t frustrate customers. That balance creates exploitable margins. Over time, small adjustments by adversaries can consistently fall beneath detection thresholds. That’s how financial losses accumulate without triggering alarms.
Data Poisoning in Lending Models
Can lending models be manipulated before they’re even deployed?
Yes. If training data is biased, incomplete, or intentionally altered, the model internalizes that distortion. Sometimes it’s subtle — mislabeled repayment outcomes, skewed sampling, flawed feature engineering. Sometimes it’s more direct.
The danger isn’t immediate chaos. It’s drift. Outputs shift gradually. Approval rates change in specific segments. And because the model is technically “performing,” the issue hides inside aggregated metrics.
Under regulatory review, that becomes difficult to defend.
Prompt Injection in Banking LLMs
Why are prompt injection attacks different from normal misuse?
Because they exploit the system’s language interface. An internal assistant instructed to follow policy can be tricked through layered instructions, role confusion, or cleverly framed requests. Instead of breaking access controls, the attacker persuades the model to override them.
In a banking environment, that could mean surfacing restricted guidance, internal logic, or confidential snippets.
Automation Bias
There’s another failure pattern that doesn’t require a technical exploit.
When staff over-trust model outputs, manual oversight weakens. Alerts are dismissed because “the system already checked it.” Risk scores are accepted without challenge. Over time, human skepticism fades.
That’s not a coding flaw. It’s operational dependency.
Banking AI security isn’t only about preventing external attacks. It’s about understanding how systems behave under pressure — technical, regulatory, and human.
5. What This Means for Banks
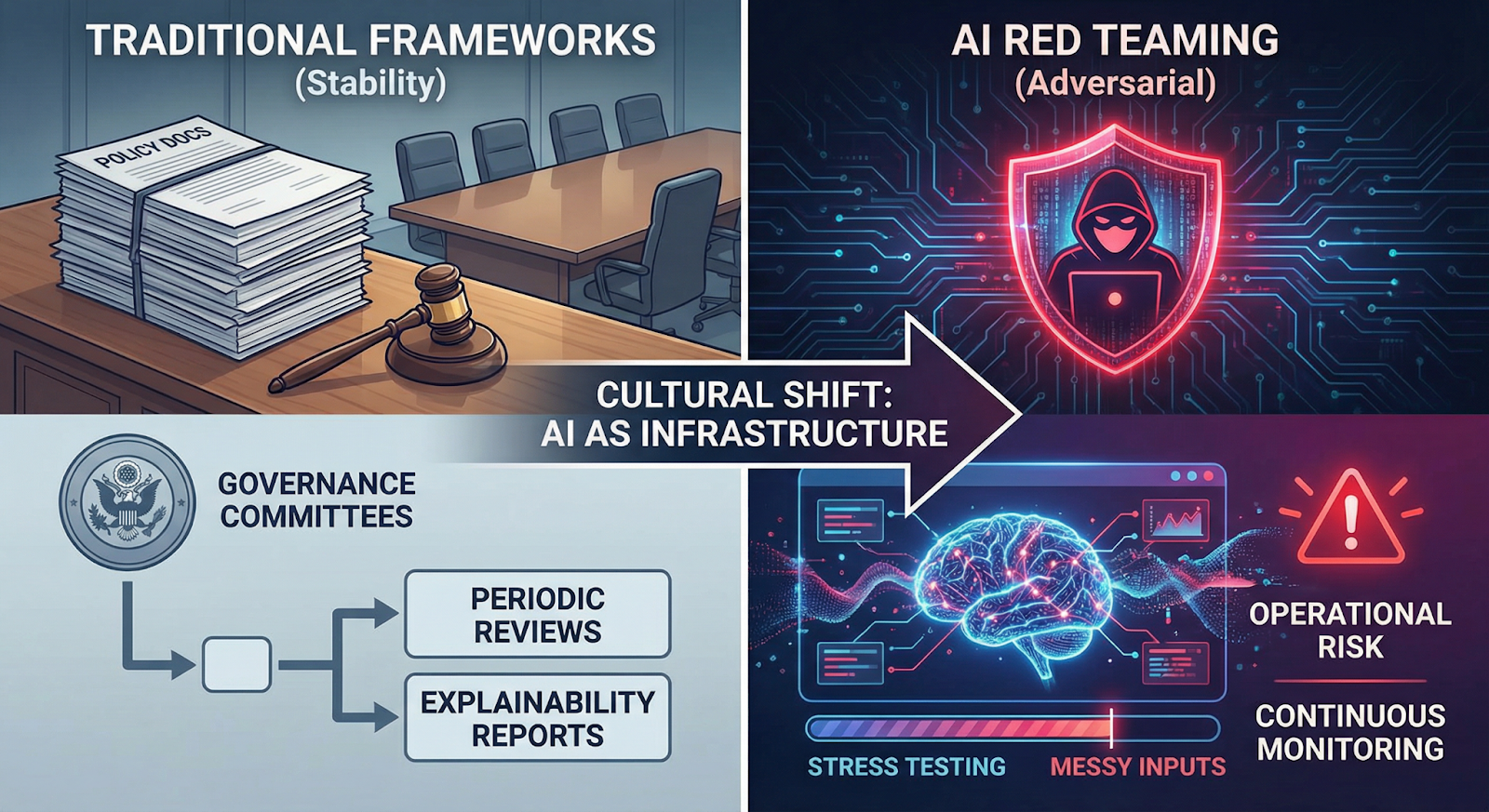
Most banks already have model risk frameworks. Validation teams. Governance committees. Policy documents stacked a foot high.
The problem? Those frameworks were built for stability — not adversaries.
AI red teaming in banking forces a different question: what breaks when someone pushes back? Not in theory. In practice. When thresholds are mapped. When inputs are manipulated. When staff rely too heavily on model outputs.
That’s where things get uncomfortable.
AI model governance in banks often centers on explainability reports and periodic reviews. Useful, yes. But they assume the model behaves consistently. Red teaming doesn’t assume. It tests. It introduces stress, edge cases, and sometimes messy inputs that wouldn’t show up in standard validation.
And the results don’t always fit neatly into governance templates.
Banking AI security also now includes systems that weren’t even on the radar two years ago — internal copilots, document summarizers, AI-driven compliance tools. If those systems can be influenced through crafted language or unexpected prompts, the risk is operational, not experimental.
The larger shift is cultural. AI systems aren’t just tools supporting decisions. In many cases, they are the decision layer. Treating them like infrastructure — tested, pressured, monitored continuously — is no longer optional.
Banks that internalize that shift move faster during supervisory review. The rest react after findings are issued.
6. Conclusion
Banking AI now sits in the path of money, credit, and compliance. It scores transactions before humans see them. It influences approvals before officers intervene. That level of authority changes the risk equation.
Performance metrics are not enough. A model can be accurate and still be exploitable. It can meet validation standards and still behave unpredictably under stress.
AI red teaming in banking closes that gap. It assumes systems will be challenged — by fraud actors, by edge cases, by regulators. The institutions that test under pressure learn early. The ones that don’t usually learn during incidents or supervisory reviews.
Banking AI security is no longer about protecting models in isolation. It’s about protecting decision systems that shape financial outcomes at scale.

“Banking AI doesn’t fail loudly, it fails silently, until the damage is done.”






Make AI red teaming a Core Banking Risk Control

.png)
.png)
.png)



