.svg)
AI red teaming in Education : Testing Assessment, Learning, and Proctoring AI

.png)
Key Takeaways
AI red teaming focuses on how education AI systems fail, not just how they perform.
Traditional AI security testing in education cannot detect adversarial misuse or silent failure modes.
High-impact education AI systems must be tested under real-world misuse scenarios.
Strong Educational AI security requires continuous adversarial evaluation, not one-time validation.
Embedding AI safety in education early prevents student harm, trust erosion, and regulatory risk.
1. Introduction
AI is already inside the classroom, not as a chatbot on the side, but in grading systems, exam monitoring tools, and adaptive platforms that decide what a student sees next. Some universities use automated systems to score written answers. Others rely on remote proctoring software to flag suspicious behavior during online exams. These tools influence grades and, sometimes, disciplinary action.
When online exams surged in 2020, problems surfaced quickly. Students at multiple universities pushed back against remote proctoring tools, including ProctorTrack. There were reports of false cheating flags. Some students struggled with facial recognition failures. Others described technical disruptions during live exams. Civil rights and privacy advocates questioned accessibility and fairness.
The issue wasn’t simply that the software had bugs. Most large systems do. The concern was different: these tools had been tested to function—not to resist pressure, edge cases, or intentional misuse. Accuracy was measured. Adversarial behavior wasn’t.
Education systems now depend on algorithmic decisions that affect transcripts, scholarships, and progression. If those systems can be manipulated, biased, or bypassed, the consequences extend beyond one failed exam.
That’s why AI red teaming in education is becoming less optional and more structural. Institutions need to test how these systems break—before someone else does.
Who this affects: CIOs, edtech product leaders, compliance teams, and academic administrators responsible for academic integrity.
2. How AI Powers Modern Education
In most institutions, AI didn’t arrive as a grand rollout. It slipped in tool by tool.
An essay grader here. A plagiarism checker is there. A system that predicts which students might fall behind. Over time, those tools started carrying real weight.
Automated grading is one of the most common uses. A model reviews written answers before an instructor even sees them. It compares patterns against previous responses and assigns a score. Fast. Scalable. But not always intuitive. Small wording differences can shift scores. That’s where concerns around AI bias in grading systems begin to surface—especially when writing style, dialect, or structure falls outside the model’s training patterns.
Remote exam monitoring is another layer. During online tests, software watches the webcam feed and logs browser activity. Some tools attempt to track eye movement or flag background noise. The promise is integrity. The harder question is AI assessment security. Can the system tell the difference between cheating and normal behavior? What if the lighting changes? What if a student looks away to think?
And then there are adaptive platforms. They recommend lessons based on performance data. They influence pacing. Students rarely see the logic behind those recommendations.
None of these systems operates in isolation anymore. Together, they shape outcomes—quietly.

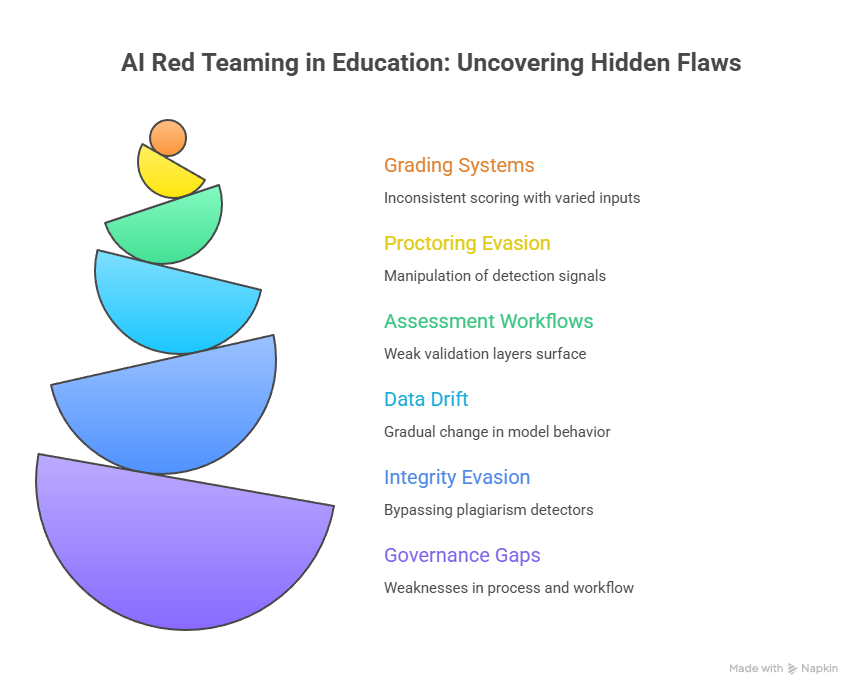
3. AI Red Teaming Use Cases in Education
Most education teams test whether their AI works. Red teaming asks a different question: how does it break?
The difference matters.
3.1 Grading Systems Under Pressure
Automated grading looks stable in controlled testing. It often isn’t when inputs vary.
Red teams will rewrite the same essay three or four ways—formal tone, conversational tone, dialect variation, and altered sentence order—and compare scoring drift. They’ll introduce odd formatting. They’ll embed irrelevant instructions inside answers to see if the model reacts.
Sometimes the scores swing more than expected. That’s where early signs of AI bias in grading systems appear. Not as obvious discrimination. More like a subtle inconsistency that compounds at scale.
3.2 Remote Proctoring Evasion
Proctoring systems rely on pattern detection. Eye direction. Background movement. Browser focus.
Red teams test what happens when those signals are nudged. Not extreme cheating. Small manipulations. Looking slightly off-screen for longer than average. Introducing low-level background noise. Using lighting that affects facial detection confidence.
Results vary. Some systems over-flag. Others miss obvious manipulation. That tension is usually invisible until someone actively tests for it.
3.3 Breaking Assessment Workflows
Assessment platforms don’t just run models. They accept uploads, pass data to scoring engines, and return results.
Red teams submit malformed files. Unexpected encoding formats. Inputs that resemble instructions rather than answers. Sometimes they stress submission endpoints repeatedly to observe failure behavior.
Weak validation layers surface quickly. That’s where AI assessment security stops being theoretical.
3.4 Long-Term Data Drift
Adaptive systems retrain. That’s the selling point.
Red teams simulate slow corruption—slightly altered feedback signals over time, inverted labels in small batches, and manipulated performance indicators. Nothing dramatic. Just a gradual change.
Months later, the model behaves differently. And no one notices why.
3.5 Integrity Tool Evasion
AI-based plagiarism and content detectors get tested, too.
Paraphrased outputs. Hybrid human-AI writing. Code with renamed variables but identical logic. Sometimes the system flags legitimate work. Sometimes it misses obvious reuse.
Threshold tuning becomes a policy issue, not just a technical one.
3.6 Governance Gaps
The final surface isn’t the model. It’s the process around it.
Who can retrain it? Who approves dataset changes? Who audits false positives?
Red teams attempt role escalation in admin panels. They test whether logs can be altered. They review whether oversight is documented or assumed.
That’s where weaknesses in AI governance in education usually sit—not in code, but in workflow.
4. How Education AI Fails Under Adversarial Pressure
AI systems in education rarely collapse all at once. They fail in small, specific ways.
Prompt-style manipulation is one example. When grading models rely on large language models or instruction-following architectures, students can experiment with embedding meta-instructions inside answers. Not obvious ones. Subtle phrasing that influences how the model interprets scoring criteria. In controlled testing, the model behaves. Under crafted inputs, scoring logic can shift.
Where do proctoring systems struggle? Often at the edge of normal behavior. Lighting changes. Camera angles. Assistive technologies. A student is thinking while looking away from the screen. These conditions aren’t malicious, but anomaly-based systems may treat them as risk signals. Under adversarial pressure—intentional signal shaping—detection confidence can degrade further.
Another failure mode is feedback amplification. If a grading or adaptive system retrains using prior outputs as part of its dataset, small distortions can compound. A slight scoring skew becomes normalized over time. That’s how bias moves from marginal to structural.
What attack patterns target education AI most frequently? “Input manipulation," “weak validation layers," and “over-trust in automated outputs." Unlike traditional breaches, the goal isn’t data theft. Its influence.
When these systems are treated as productivity tools instead of decision engines, their failure modes remain hidden until challenged directly.
5. Why Traditional Testing Misses These Vulnerabilities
Most institutions already test their systems. The problem isn’t a lack of testing. It’s what gets tested.
Standard QA checks whether outputs match expectations under normal conditions. It measures accuracy, uptime, and response time. It does not examine how the model reacts to crafted inputs, boundary cases, or slow manipulation over time.
Why does this matter? Because model influence doesn’t look like a breach. No firewall trips. No alert fires. Scores shift slightly. Flags increase. Recommendations drift.
Another gap is comparison. Education AI security is often treated like conventional cybersecurity. Secure the infrastructure. Control access. Monitor logs. But models can be nudged without system compromise.
Without structured AI testing in education, institutions depend on vendor validation and compliance checklists. Those processes confirm functionality. They do not test resistance.
That difference is where most blind spots live.

6. Implications for Educational Institutions
If these systems affect grades and exam outcomes, they need more than routine checks.
Start by making AI testing in education recurring. Not annual. Not vendor-led only. Models evolve as data changes. Testing has to keep pace.
Next, connect findings to AI governance in education. If a grading model shows drift, who reviews it? If a proctoring tool over-flags, who adjusts thresholds? Governance isn’t policy on paper. It’s decision ownership.
Independent review also matters. Vendors confirm that systems run as designed. That’s different from asking whether the design resists pressure.
Testing cycles should be shorter for high-stakes tools—grading engines, proctoring systems, and progression models. Waiting a year to reassess is too long.
Educational institutions already treat networks and finance systems as critical infrastructure. AI systems that influence transcripts and academic standing deserve the same posture.
7. Conclusion
AI systems in education now influence grades, exam integrity decisions, and academic progression. They operate quietly, but their impact is structural.
The gap isn’t awareness. Most institutions know these tools carry risk. The gap is in how they’re tested. Functional validation doesn’t expose manipulation paths, drift, or scoring instability. Those weaknesses surface only under pressure.
That’s why AI red teaming in education needs to move from an optional security exercise to operational discipline. Institutions that test for failure—not just performance—protect fairness, credibility, and student trust.
As these systems expand into admissions, scholarship review, and performance prediction, the stakes increase. Treating them as critical infrastructure is no longer an overreaction. It’s overdue.

“Education AI doesn’t fail loudly, it fails quietly, shaping outcomes long before anyone notices.”






Make AI red teaming a Core Control for Education AI with WizSumo

.png)
.png)
.png)



