.svg)
AI red teaming in healthcare : Safeguarding Patient-Critical AI Systems

.png)
Key Takeaways
AI red teaming focuses on how healthcare AI systems fail, not just how they perform.
Traditional AI security testing in healthcare cannot detect adversarial misuse and silent clinical risks.
High-impact healthcare AI systems must be tested under real-world misuse scenarios, not ideal conditions.
Healthcare AI security depends on continuous adversarial testing, not one-time validation.
Secure and trustworthy healthcare AI is achieved through evidence of resilience, not assumptions of safety.
1. Introduction
AI is no longer sitting in the background of healthcare systems. It’s reading scans before radiologists do. It’s flagging sepsis risk in ICU dashboards. It’s guiding patients through symptom checkers at 2 a.m. when no clinician is immediately available.
That sounds efficient. Sometimes it is. Until it isn’t.
In February 2026, researchers evaluated an AI-powered health guidance system known as ChatGPT Health in a controlled study published in Nature Medicine. They ran 60 urgent clinical scenarios through it — respiratory distress, suicidal ideation, escalating infection. In more than half of the emergency cases, the system failed to recommend immediate care. In some self-harm simulations, adding additional clinical details caused previously triggered safety guidance to disappear.
Nothing crashed. No alarms went off. The responses looked calm. Reasonable. Confident.
And wrong.
This wasn’t about hackers breaking into hospital networks. It was about subtle failure under pressure — context shifts, edge cases, layered information. Exactly the kind of stress real-world systems face every day.
That’s where AI red teaming in healthcare becomes essential. Because gaps in AI security in healthcare don’t always show up during routine validation. They surface in ambiguity, under load, in moments that directly affect patient safety AI systems.
If AI influences care decisions, it must be tested the way real adversaries — and real patients — will test it.
2. How AI Powers Healthcare
Walk into a modern hospital and AI is already there — just not always visible.
Radiology teams use models that pre-screen scans before a human reviews them. Pathology labs rely on image classifiers to flag suspicious tissue regions. Even dermatology apps now suggest whether a mole “looks concerning” before a specialist ever sees it.
These systems are fast. Sometimes faster than staffing allows.
Then there are the predictive engines running in the background. Sepsis alerts. Readmission risk scores. ICU deterioration models that update every few hours as lab values shift. They ingest streams of “EHR data” and output probabilities that shape escalation decisions. When they’re accurate, they help. When they drift, they mislead quietly.
And drift happens more often than vendors admit.
Change the patient population. Introduce a new device. Alter documentation patterns. A model trained in one hospital doesn’t always behave the same in another. That’s where medical AI vulnerabilities start to surface — not as dramatic failures, but as subtle degradation.
Now layer in clinical decision support tools powered by large language models. They summarize charts, draft notes, and suggest next steps. Useful, yes. But also sensitive to ambiguous inputs and incomplete context.
Most organizations test for performance. Fewer test for stress. Even fewer probe for failure under manipulation.
That’s the gap between deployment and true AI security in healthcare.

3. AI Red Teaming Use Cases in Healthcare
Most hospitals test whether a model meets accuracy benchmarks. Fair enough. But accuracy under normal conditions doesn’t tell you how a system behaves when something shifts — or when someone pushes it.
That’s where AI red teaming in healthcare comes in. It’s less about scoring performance and more about deliberately creating stress.
Let’s look at how that plays out in practice.
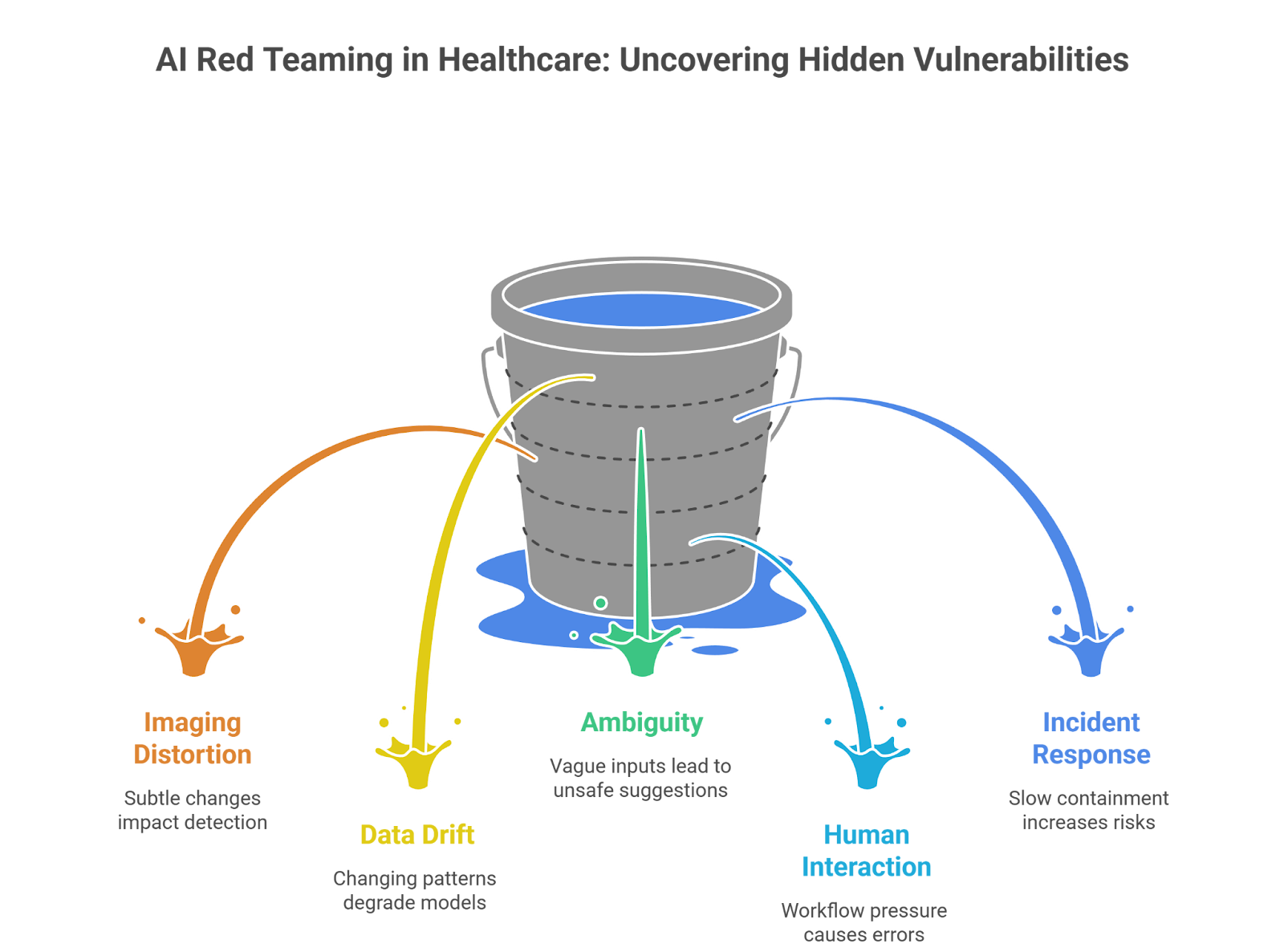
3.1 Imaging Models Under Subtle Distortion
Take a radiology classifier. In validation, it performs beautifully. Then the hospital upgrades imaging hardware. Or compression settings change. Or a scan is slightly underexposed.
Red teams recreate those small distortions on purpose:
⮞ Add minimal pixel perturbations to CT or MRI images
⮞ Simulate file compression artifacts during transfer
⮞ Insert synthetic but clinically plausible anomalies
⮞ Adjust image contrast to test sensitivity boundaries
No dramatic hacks. Just controlled friction.
The question isn’t “Can it detect cancer?”
It’s “When does it quietly stop detecting cancer?”
Those edges reveal real medical AI vulnerabilities — the kind that don’t show up in polished vendor reports.
3.2 Predictive Models Under Data Drift
Predictive models are fragile in a different way. They rely on patterns in historical data. Change the population, and the math shifts.
Red teams simulate:
⮞ Missing lab values
⮞ Delayed chart entries
⮞ New demographic distributions
⮞ Rare comorbidity clusters
Why do models fail in live hospitals?
Because the environment isn’t static. A model trained on last year’s data may behave very differently during a new outbreak or after a documentation policy change.
And when it degrades, it doesn’t announce it. It just becomes slightly less reliable — enough to influence triage decisions in subtle ways.
3.3 Clinical Decision Support Under Ambiguity
Now consider LLM-assisted documentation or treatment suggestion tools.
Red teams push them with:
⮞ Contradictory symptom descriptions
⮞ Vague phrasing that invites assumption
⮞ Layered patient histories that introduce cognitive overload
⮞ Prompt manipulation attempts inside clinical notes
Medicine is messy. Inputs aren’t clean bullet points. They’re fragmented narratives.
If a system produces confident but unsafe suggestions under ambiguity, that’s not a minor glitch. It’s a governance problem tied directly to AI security in healthcare.
3.4 Human–AI Interaction Failures
Some of the most serious risks aren’t technical exploits at all.
Red teams recreate workflow pressure:
⮞ Flood dashboards with alerts to observe fatigue
⮞ Measure how often clinicians override or blindly accept outputs
⮞ Test escalation paths when AI flags are missed
⮞ Simulate high-load emergency department conditions
How do failures impact patient safety AI systems?
Through behavior. Through trust. Through shortcuts taken during long shifts.
The technology might be statistically sound — yet still dangerous in context.
3.5 Incident Simulation and Containment
Then there’s the part most organizations skip: response.
Red teams run drills:
⮞ Simulate a sudden spike in anomalous outputs
⮞ Force a controlled model rollback
⮞ Test logging transparency and traceability
⮞ Exercise AI incident response healthcare playbooks under time pressure
Finding weaknesses is useful. Knowing how fast you can contain them is more important.
That’s the difference between theoretical safeguards and operational AI security in healthcare.
4. The Testing Gap: Why Healthcare AI Breaks in Production
On paper, most clinical AI systems look solid. There’s a validation report. A performance score. Sometimes even peer-reviewed backing.
So why do issues surface later?
Because controlled validation isn’t the same as live deployment.
Internal testing usually happens in stable conditions. Clean datasets. Expected inputs. Limited variability. Teams confirm accuracy against historical data and move forward. But hospitals are noisy environments. Records are incomplete. Devices change. Staff rotate. Workflows evolve. None of that appears in a neat test set.
Another problem: overreliance on vendor metrics. A model that performs well in one institution may behave differently in another. Subtle differences in documentation practices or patient demographics can alter outputs. Performance numbers don’t always travel well.
Then there’s compliance comfort. Passing internal governance reviews or meeting documentation standards creates reassurance. Yet regulatory alignment doesn’t automatically stress the model under drift, ambiguity, or manipulation. It confirms controls exist — not that they hold.
What’s missing is intentional pressure.
Traditional testing verifies that a system functions. It rarely investigates how it behaves when pushed off balance.
And that’s where gaps in AI security in healthcare begin to widen — not with dramatic failure, but with small degradations that accumulate until someone notices.
5. From Awareness to Action
At some point, the conversation has to move beyond “AI is powerful” and into “Who’s responsible when it fails?”
Hospitals don’t need dramatic cyber scenarios to justify action. The quieter risks are enough. A deterioration model drifting slightly off baseline. A triage system becoming overconfident. A documentation assistant nudging clinicians toward shortcuts. These are slow-burn problems.
So what changes?
Start by making adversarial testing routine, not reactive. AI red teaming in healthcare shouldn’t only happen after a public incident. It should be part of the lifecycle — especially when models are updated, retrained, or transferred between sites.
Then look at response muscle. If an AI output suddenly deviates from expected behavior, how fast would anyone notice? Who has the authority to disable it? Is there a clear escalation path that includes clinical leadership? A real AI incident response healthcare process means practicing these decisions before they’re needed.
Compliance also needs reframing. Meeting HIPAA compliance AI requirements protects data confidentiality. It doesn’t guarantee robustness under stress. Privacy is one layer. Safety is another.
And finally, governance cannot sit only with IT. If a system influences diagnosis or triage, oversight belongs in patient safety conversations. Review it like any other clinical tool. Audit it. Question it. Track near-misses.
AI isn’t experimental anymore. In many hospitals, it’s infrastructure.
Infrastructure demands discipline.
6. Conclusion
Healthcare AI is no longer experimental. It reads scans, ranks risk, drafts notes, and influences who gets attention first. That makes it part of the care pathway — whether organizations label it that way or not.
The recent safety failures in AI-driven medical guidance weren’t dramatic breaches. They were quieter. Misjudged urgency. Context shifts the system didn’t handle well. Confident answers that shouldn’t have been confident.
That pattern matters.
The real risk isn’t that AI occasionally makes mistakes. Clinicians do too. The risk is deploying systems at scale without deliberately testing how they behave under stress, drift, ambiguity, or pressure.
That’s the role of AI red teaming in healthcare — not as a compliance formality, but as a discipline. One that treats AI systems like clinical infrastructure.
Because once AI influences care decisions, safety isn’t optional. It’s operational.

“Healthcare AI doesn’t fail like software, it fails like a decision, often silently, and sometimes irreversibly.”






Make AI red teaming a Core Healthcare Risk Control With WizSumo

.png)
.png)
.png)



