.svg)
AI red teaming in legaltech : Securing Decision Assistance and Compliance AI

.png)
Key Takeaways
AI red teaming focuses on how LegalTech AI systems fail, not just how they perform.
Legal decision assistance AI is highly vulnerable to silent hallucinations and bias.
Traditional validation cannot detect adversarial misuse of legal AI systems.
Compliance AI failures often surface only during audits or enforcement actions.
Trustworthy LegalTech AI requires continuous adversarial testing, not assumptions.
1. The Risk Landscape of AI in Legal Workflows
Legal work has always depended on careful reading—cases, statutes, contracts, regulatory guidance. Now AI systems are doing part of that reading. Research assistants summarize case law. Document-review tools scan contracts for risky clauses. Some platforms even suggest legal arguments based on past rulings.
That speed is useful. But it hides a fragile assumption: that the AI is right.
A court incident in 2023 showed how risky that assumption can be. Lawyers submitted a filing filled with case citations generated by an AI research assistant. The problem surfaced quickly. Several of the cited cases didn’t exist at all. They looked legitimate—case names, dates, legal language—but they were fabricated.
This is the core issue behind hallucinations in legal AI. Large language models can produce answers that sound authoritative even when the underlying facts are wrong. In a legal setting, that mistake isn’t just embarrassing—it can influence filings, arguments, or compliance decisions.
The episode exposed a deeper challenge for the industry. As AI tools move into legal research and "compliance workflows", firms must think seriously about Legal AI security. Systems that shape legal decisions cannot be treated like ordinary productivity software.
That’s why AI red teaming in LegalTech is gaining attention. Instead of assuming these systems behave correctly, organizations deliberately test how they fail—before those failures show up in court.
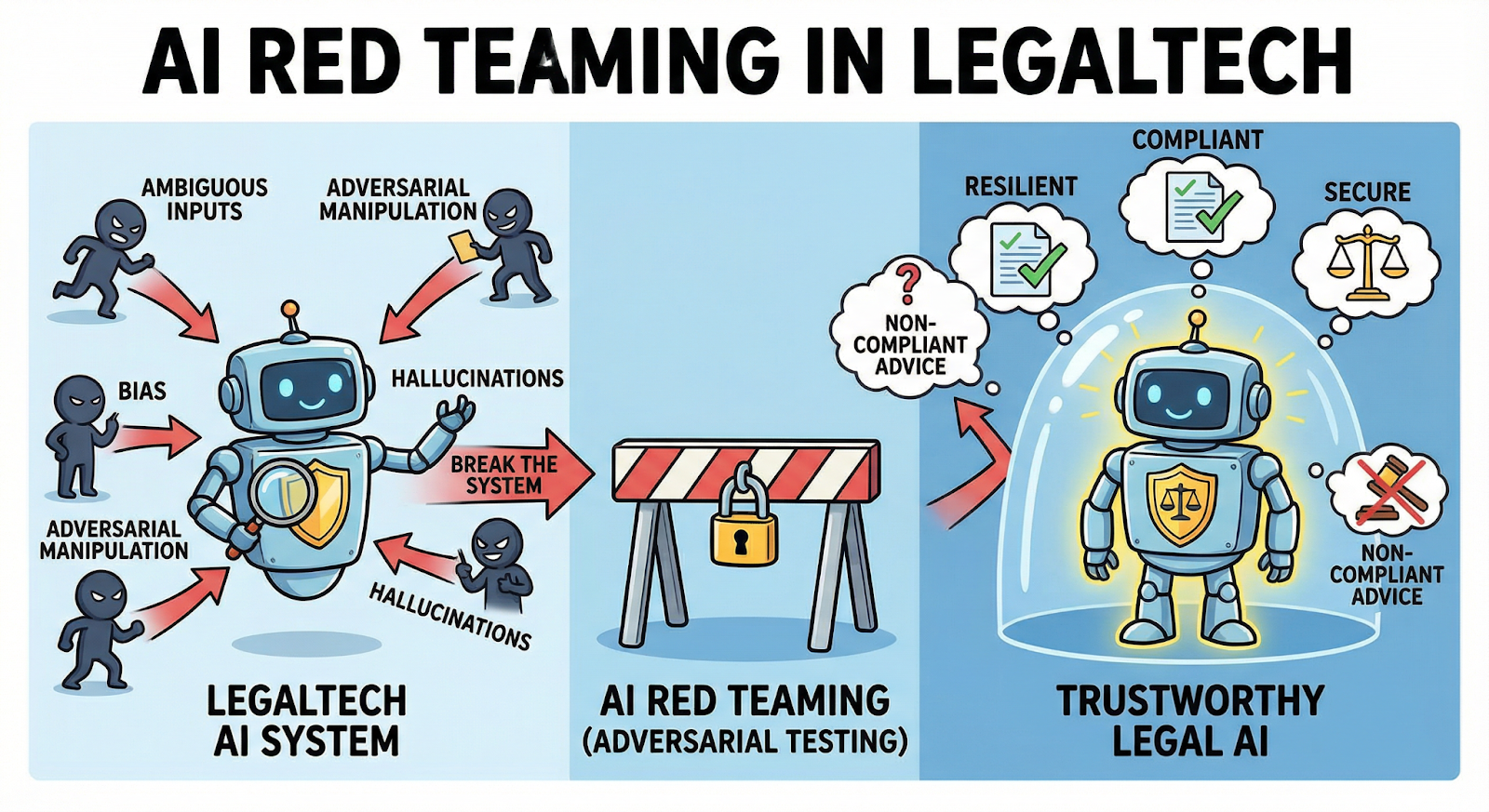
2. Where AI Is Used in LegalTech Systems
Walk into a modern law firm and you’ll see AI popping up in unexpected places. Not as a single platform—but scattered across everyday tools lawyers already use.
Research is the most visible example. AI assistants can search thousands of cases and return a short explanation of how courts interpreted a specific issue. What used to take hours of reading now happens in a few seconds. Convenient, yes. But when the system misunderstands context, the summary can quietly drift away from the actual precedent.
Compliance teams rely on AI too. Many organizations run automated reviews of contracts and internal documents using legal AI compliance tools. The software scans for regulatory obligations, suspicious clauses, or missing disclosures. It’s helpful for spotting patterns across large document sets. Still, these systems are only as reliable as the data and assumptions behind them.
Then there’s document analysis. AI models pull deadlines, liabilities, and obligations from long agreements that humans would normally review line by line. During large audits or transactions, that speed is valuable.
But the more these systems influence legal interpretation, the more pressure falls on Legal AI security. If the underlying model is wrong—or manipulated—the mistake doesn’t stay inside the software. It travels directly into legal decisions.
3. Adversarial Testing Scenarios for Legal AI Systems
Legal AI systems usually look reliable when they’re tested in clean conditions. Ask a clear research question, give the model enough context, and the answer often sounds convincing.
But real legal work isn’t that tidy. Questions arrive with incomplete facts, messy language, or conflicting interpretations. That’s where AI red teaming in LegalTech focuses its attention—pushing systems into situations where things start to break.
Hallucinated Case Law
One common stress test targets hallucinations in legal AI. Instead of asking the model for well-known precedents, testers request rulings tied to obscure legal situations.
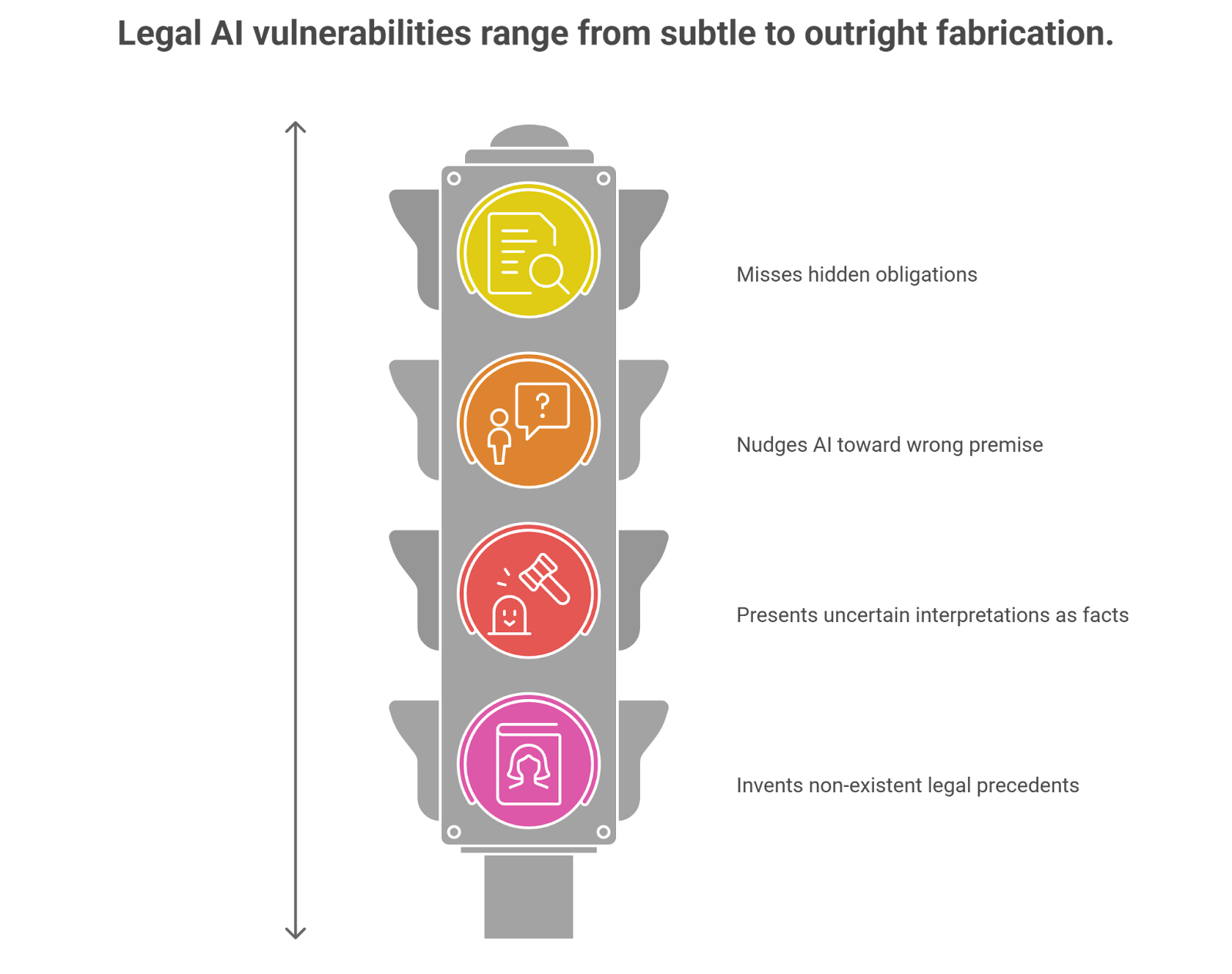
Sometimes the AI fills the gap by inventing something that looks real: a case name, a court citation, even a short explanation of the decision. Everything reads like a legitimate authority. The only issue—no such case exists.
For legal professionals, that kind of output is dangerous because it appears trustworthy at first glance.
Prompt Framing That Changes Legal Meaning
Legal interpretation is sensitive to wording. Shift a few phrases and the legal question itself changes.
Red teams experiment with that. They add misleading background information, remove key details, or frame the query in a way that nudges the model toward a different legal interpretation. In some cases the AI begins reasoning from the wrong premise entirely.
The response might still sound persuasive, even though the legal foundation underneath it is flawed.
Compliance Language That Slips Past Detection
Companies increasingly depend on legal AI compliance tools to scan policies, contracts, and internal communications. These systems are good at catching obvious violations.
Subtle ones are harder.
During testing, analysts introduce clauses that hide obligations inside dense language or combine several regulatory requirements in the same sentence. Occasionally the AI identifies the issue. Other times it treats the document as compliant when it isn’t.
That gap is exactly what adversarial testing tries to uncover.
Overconfident Legal Recommendations
Some AI tools go further than research—they suggest strategies or draft arguments.
Under pressure, these models may mix together related cases, rely on outdated precedent, or present uncertain interpretations as though they are definitive conclusions. The output sounds confident. The reasoning behind it may be shaky.
When those suggestions influence legal decisions, the consequences extend beyond the software itself.
4. How Legal AI Systems Break in Practice
Legal AI tools rarely fail in obvious ways. Most of the time they produce answers that look reasonable on the surface. The problem appears when you check the reasoning behind those answers.
Take context mixing. Legal questions often reference several statutes or past rulings at once. An AI system may pull fragments from different cases and combine them into a single explanation. The result reads smoothly—but the legal logic doesn’t actually hold together.
Another weakness is confidence. Language models are built to generate fluent responses, not to signal doubt. Even when the model lacks reliable information, it may still deliver an answer that sounds certain.
That creates a real challenge for Legal AI security. Lawyers reviewing the output may assume the explanation is grounded in actual precedent when it isn’t.
This is why many LegalTech teams have started introducing LLM security testing. Instead of asking whether the model works in normal conditions, testers explore edge cases—messy legal questions, incomplete facts, or deliberately confusing prompts.
Those scenarios reveal weaknesses that ordinary testing rarely exposes.
5. Strengthening Security for Legal AI Systems
Many legal teams adopt AI tools the way they adopt new research software—install the platform, train staff, and start using it. That approach works for ordinary tools. It’s risky for AI.
The difference is subtle. AI systems generate answers that look complete even when the reasoning behind them is shaky. A research assistant might return a convincing legal explanation, but the citations may be outdated or partially incorrect. Without verification, those errors travel quickly into research notes or draft filings.
That’s where AI red teaming in LegalTech becomes useful. Instead of testing the system under ideal conditions, teams deliberately introduce messy legal questions, conflicting statutes, or ambiguous case references. The goal is simple: observe how the model behaves when the situation stops being clean.
Oversight matters just as much as testing. Many organizations are now defining review procedures and accountability rules as part of AI governance in law firms. Who verifies AI-generated citations? Who reviews legal recommendations produced by the model?
Alongside those processes, continuous LLM security testing helps teams track how models behave as training data, regulations, and legal datasets evolve.

6. Conclusion
Legal teams are experimenting with AI faster than they are learning how it behaves. Research assistants summarize cases. Contract tools extract obligations. Compliance platforms scan documents for regulatory issues.
Most of the time, the systems work. The problem appears in the edge cases.
A model may mix details from unrelated precedents. It may generate a citation that looks legitimate but never existed. In other situations the reasoning sounds convincing while the legal logic underneath it is wrong. Problems like these are exactly why Legal AI security has become a serious concern for LegalTech vendors and law firms.
Testing these systems the way adversaries might test them changes the picture. Through AI red teaming in LegalTech, organizations can see how models behave when questions become ambiguous, incomplete, or intentionally misleading.
Combined with ongoing LLM security testing, that kind of scrutiny helps ensure legal AI systems remain useful tools—without quietly introducing risk into legal decisions.

“Legal AI doesn’t need to be wrong to be dangerous, it just needs to be confidently misleading.”






Make AI red teaming a Core Control for LegalTech AI with WizSumo

.png)
.png)
.png)



