.svg)
AI red teaming in retail: Securing Pricing, Demand, and Personalization AI

.png)
Key Takeaways
AI red teaming focuses on how retail AI systems fail, not just how they perform.
Traditional validation cannot detect silent risks like pricing algorithm manipulation.
AI security testing in retail must assume adversarial customer and competitor behavior.
Continuous red teaming is essential for maintaining strong retail AI security at scale.
Secure retail AI is built through evidence of resilience, not assumptions of correctness.
1. When Retail AI Goes Wrong
Retailers now rely on AI for everyday decisions. Pricing models adjust product prices. Forecasting systems estimate demand. Recommendation engines decide which products appear first.
Most of the time, customers never notice.
But these systems depend heavily on data signals. If those signals change—even slightly—the model reacts.
Sometimes in strange ways.
A well-known case involved automated pricing bots on an online marketplace. Two sellers used algorithms that monitored competitor prices. Each system kept increasing its price in response to the other. Eventually, a single book listing climbed above $20 million.
No hacker was involved. The algorithms simply followed the signals they received.
This is the real risk. Retail AI systems respond to inputs without understanding intent. Manipulated data, fake demand signals, or unusual behavior can expose serious retail AI model vulnerabilities.
Testing these scenarios before they happen is the purpose of AI red teaming in retail—an increasingly important part of modern retail AI security.
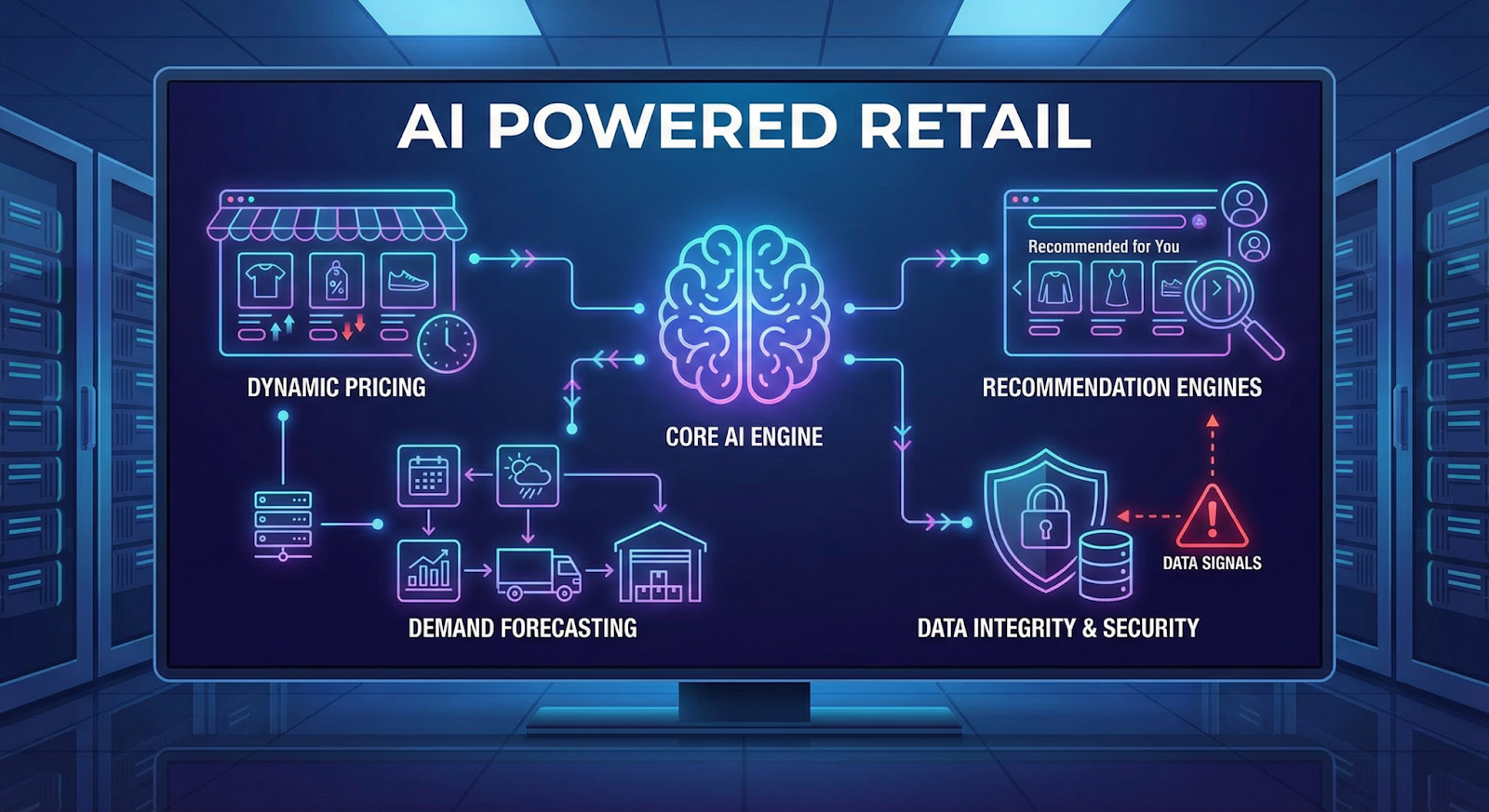
2. Where Retail AI Is Used
Retail AI quietly runs many everyday decisions.
Take pricing. In large e-commerce stores, prices rarely stay fixed. Algorithms monitor competitor listings, product demand, inventory levels, and sometimes even browsing activity. The model reacts quickly. A price that appears in the morning may already be different by the evening.
Demand forecasting is another major system. Retailers train models on years of sales data, seasonal trends, promotions, and external signals such as holidays or weather patterns. Those predictions determine inventory orders and warehouse distribution.
Then there are recommendation engines. These systems watch how customers browse, what they click, and what they eventually buy. The model ranks products and decides what appears on a homepage or product page.
All of these systems rely heavily on data signals. When those signals are manipulated, the models may respond incorrectly. Scenarios like AI pricing algorithm manipulation or corrupted training data can expose deeper retail AI model vulnerabilities.
Understanding how these systems behave under unusual inputs is exactly why organizations are starting to test them more aggressively.
3. How Retail AI Is Actually Tested
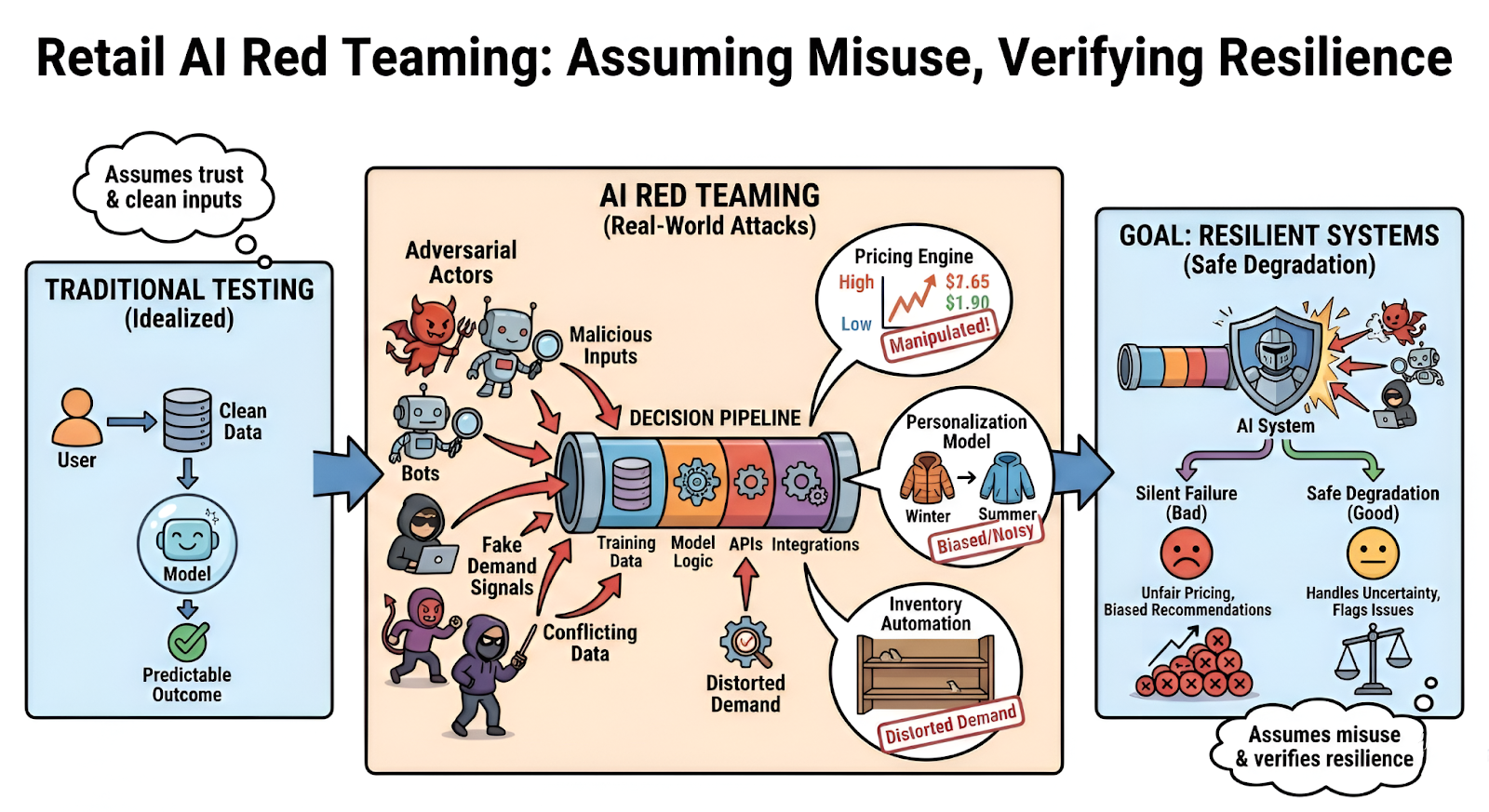
Traditional testing checks whether a model works. Red teaming asks a different question: what happens if someone tries to break it?
Retail AI is particularly sensitive to signals coming from outside the system. Competitor prices. Customer behavior. Historical sales data. If those inputs change in unusual ways, the model may react in ways designers never expected.
Pricing systems are often the first target. Dynamic pricing models constantly watch competitor listings and demand signals. A red team might simulate abnormal demand spikes or manipulated price feeds to see how the model reacts. In some cases the system starts adjusting prices aggressively, revealing potential AI pricing algorithm manipulation risks.
Forecasting models introduce a different weakness. They rely on long histories of training data. When that data is subtly altered, predictions may drift. Red teams sometimes inject small anomalies into historical sales or seasonal patterns to see whether the system detects them. If it doesn’t, the model becomes vulnerable to data poisoning retail AI.
Recommendation systems behave differently. They learn from user behavior—clicks, searches, purchases. Flood those signals with automated activity and rankings may shift. Certain products suddenly appear everywhere.
And then there’s pricing fairness. Testing occasionally uncovers AI bias in retail pricing, where similar customers receive different prices based on indirect signals such as location or browsing history.
None of these issues appear during normal testing. They surface only when someone deliberately pushes the system into uncomfortable territory.
4. How Retail AI Systems Actually Break
Retail AI rarely fails in dramatic ways. More often, the model simply starts making strange decisions.
Pricing systems are a good example.
Dynamic pricing models react to signals from the market—competitor listings, demand changes, inventory levels. That sounds reasonable. Until the signals themselves are wrong.
Imagine a competitor price feed suddenly dropping. Or automated traffic creating artificial demand for a product. The pricing model reacts immediately. Prices shift. Sometimes aggressively. Situations like this open the door to AI pricing algorithm manipulation, where the system responds to signals that were never real.
Forecasting models fail more quietly.
They learn from historical sales data. If small distortions enter that dataset—incorrect sales records, unusual demand spikes, corrupted trends—the model absorbs them during training. Over time the forecasts drift away from reality.
Nothing breaks. The system still produces predictions. They’re just unreliable. That’s the basic mechanism behind data poisoning retail AI.
Recommendation systems behave differently again. They watch user behavior constantly. Clicks. Views. Purchases.
Automated activity can imitate those signals surprisingly well. Enough artificial engagement and the ranking logic changes. Products start appearing where they normally wouldn’t.
These situations expose deeper retail AI model vulnerabilities, especially in systems designed to react quickly to incoming data.
5. Why Traditional Testing Misses These Problems
Most retail security testing focuses on infrastructure. Servers, authentication systems, APIs.
AI systems are different.
They fail because of inputs, not access.
A forecasting model can behave perfectly in testing environments but react unpredictably once real-world signals start flowing in. Slightly unusual data patterns may push the model into decisions nobody anticipated.
Another issue is how models interpret data. Machine learning systems don’t understand context—they detect patterns. If those patterns change, the output changes too. Traditional QA rarely explores those edge cases.
There’s also the attacker mindset.
Quality assurance teams test whether a system works correctly. Adversaries test how a system behaves when signals are deliberately manipulated. That difference is why many retail AI model vulnerabilities remain invisible during normal testing.
This gap is exactly why organizations are adopting AI red teaming in retail. Instead of validating accuracy alone, red teams intentionally stress systems with abnormal signals to reveal weaknesses that standard testing misses.
6. What Retailers Should Do Next
Retail companies don’t need to abandon AI. But they do need to start treating these systems differently.
First, AI models should be included in threat models. Pricing engines, forecasting models, and recommendation systems influence revenue directly. If those systems can be manipulated, they belong in the same risk discussions as payment infrastructure or customer data systems.
Second, the data pipeline deserves more attention. Many failures begin there. Training datasets, market signals, and behavioral logs should be monitored for anomalies. Even small distortions can lead to problems like data poisoning retail AI.
Regular adversarial testing also matters. Running controlled exercises helps teams uncover retail AI model vulnerabilities before they affect production systems. This is where AI red teaming in retail becomes valuable—testing models the way attackers might probe them.
And one more thing often gets overlooked: pricing fairness.
Retailers increasingly audit models to detect AI bias in retail pricing, especially when algorithms use location or behavioral signals that could unintentionally affect certain customer groups.
None of these steps eliminate risk entirely. But they make AI systems far more resilient.
7. Final Thoughts
Retail AI systems move fast. Faster than most teams realize.
Prices adjust automatically. Forecasts update quietly in the background. Recommendation engines reshuffle what customers see every few minutes. Most of the time it works well enough that nobody questions it.
Until something odd happens.
A sudden price swing. Inventory forecasts that don’t make sense. A product appearing everywhere in recommendations for no clear reason. Often the model is simply reacting to signals it shouldn’t trust.
That’s the uncomfortable part of machine learning in retail. The system is doing exactly what it was trained to do.
Which is why more companies are experimenting with AI red teaming in retail. Instead of assuming models behave correctly, they deliberately try to confuse them. Strange inputs. Distorted signals. Edge cases.
Because strengthening retail AI security now means understanding how these systems behave when the data itself becomes unreliable.

“Retail AI rarely fails loudly, it leaks revenue quietly, one decision at a time.”






Make AI red teaming a Core Retail Risk Control With WizSumo

.png)
.png)
.png)



