.svg)
AI red teaming in SaaS : Stress-Testing AI Copilots and Enterprise Automation

.png)
Key Takeaways
AI red teaming in SaaS focuses on how AI behaves under misuse, not just how it performs.
prompt injection in SaaS remains one of the most tested and exploited AI weaknesses.
Traditional AI security testing in SaaS misses behavioral and scale-driven failures.
SaaS AI security requires adversarial testing across chatbots, APIs, and automations.
Continuous AI red teaming is essential as SaaS platforms evolve and scale AI features.
1. The Growing Security Risk of SaaS AI
AI copilots are quietly spreading across SaaS products.
A CRM assistant drafts emails. A support platform summarizes tickets. Developer tools generate code suggestions inside repositories. In many cases, these assistants are already connected to internal company data.
That connection changes the security model.
Traditional SaaS features behave predictably. Inputs go in, logic runs, outputs come out. AI systems don’t work that way. Their behavior depends on prompts, context, retrieved documents, and sometimes external sources.
Which means the system can be influenced.
Security researchers have demonstrated how simple tricks—like embedding instructions inside documents or webpages—can manipulate enterprise AI assistants. The model reads the content, treats the hidden text as instructions, and suddenly the response is doing something it shouldn’t.
Sometimes that means revealing information. Sometimes it means ignoring internal safety rules.
These kinds of failures illustrate the growing “SaaS AI security” risks organizations face as AI tools gain access to enterprise workflows.
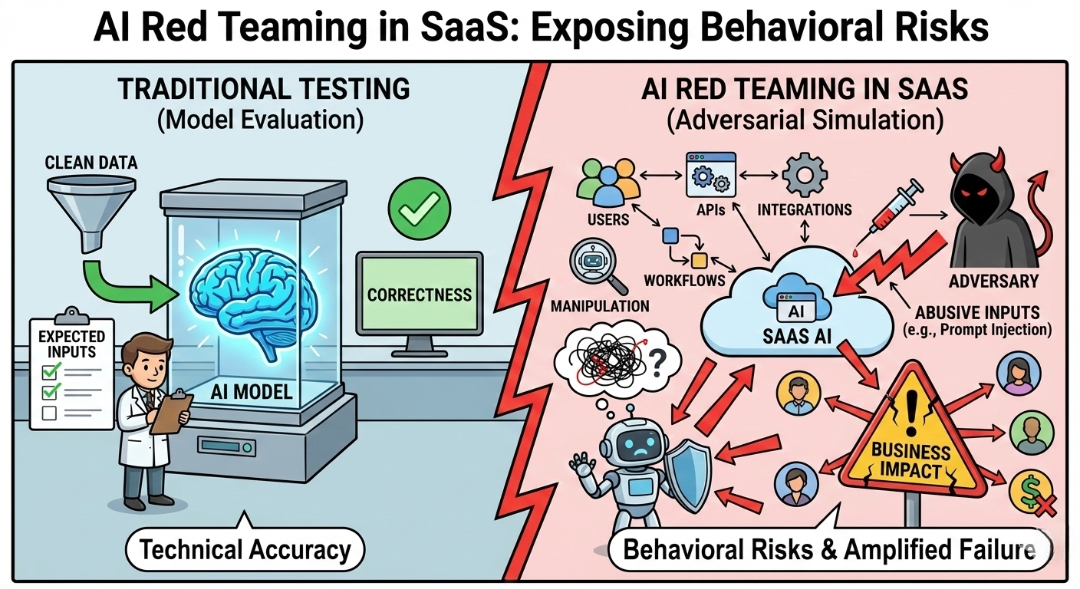
2. Where AI Actually Sits Inside SaaS Platforms
Most people think of AI in SaaS as a chatbot sitting in the corner of the screen. That’s only the visible part. Under the hood, AI is now embedded across several layers of modern SaaS products.
AI Copilots
Copilots assist users directly inside the application interface. A sales platform may summarize customer calls. A developer tool may generate code suggestions. Knowledge assistants search internal documents and answer questions.
Because these systems read enterprise data and user prompts simultaneously, their behavior can shift depending on the context they receive.
Workflow and Automation Agents
AI is also being used to trigger operational tasks. Support platforms route tickets automatically, marketing tools generate campaign content, and CRM systems update records based on AI-generated insights.
If an attacker manipulates the instructions that drive these agents, the system may trigger actions the user never intended.
AI Decision and Recommendation Systems
Some SaaS platforms rely on AI models to recommend actions—prioritizing leads, predicting churn, or suggesting operational changes.
Testing these behaviors requires more than traditional “application security checks”. This, is where LLM security testing becomes important, helping teams understand how models behave when prompts, data, or context are manipulated.
3. Real AI Red Teaming Scenarios in SaaS Platforms
When teams run AI red teaming in SaaS, they rarely attack the model in isolation. The real question is how the model behaves inside the product—connected to data, APIs, and workflows.
That’s where the interesting failures appear.
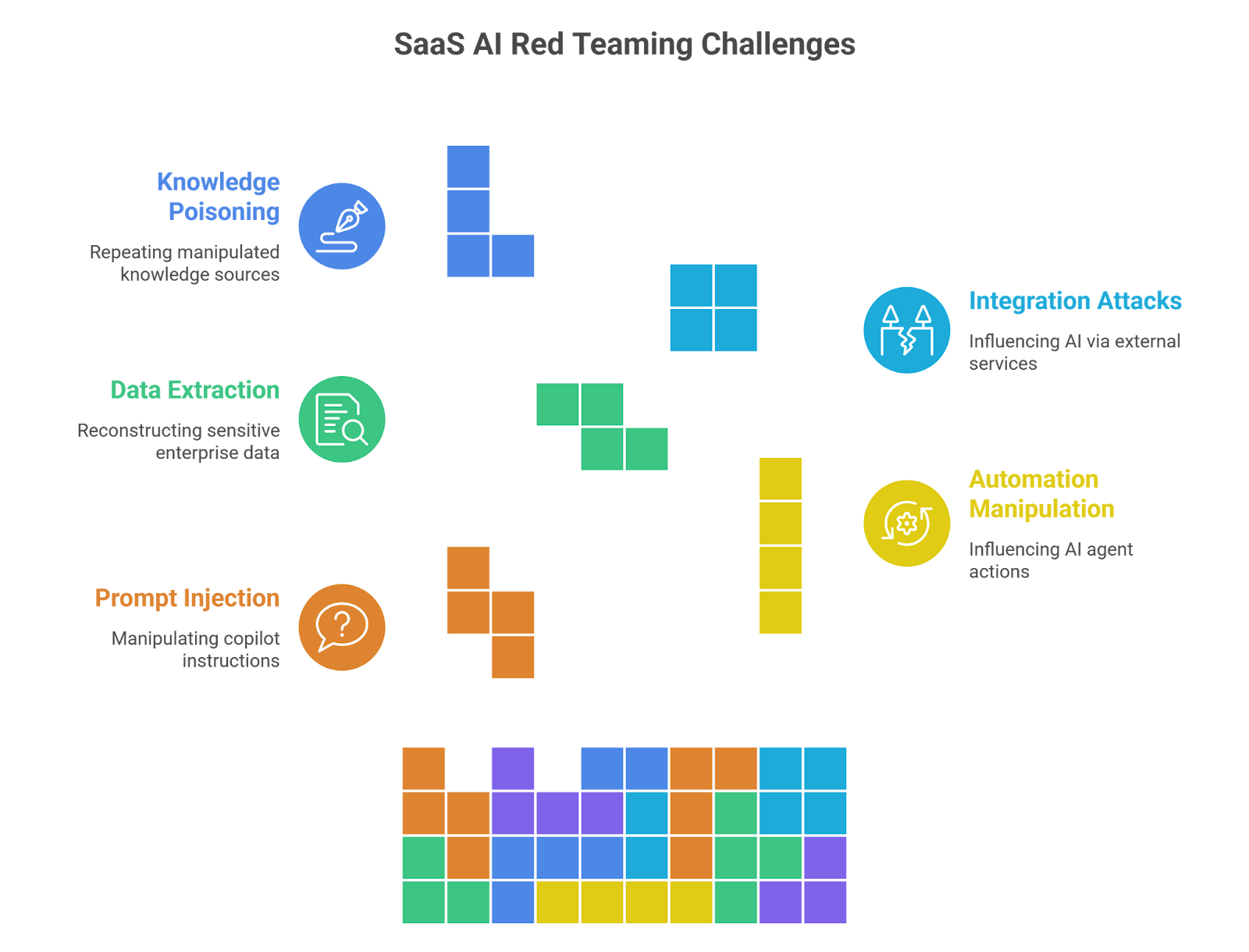
3.1 Prompt Injection Against AI Copilots
Copilots are extremely sensitive to instructions. They read system prompts, user input, and contextual data all at once. That mixture creates opportunities for manipulation.
Red teams often start with simple experiments:
⮞ embedding hidden instructions inside uploaded documents
⮞ inserting malicious prompts in user messages
⮞ testing jailbreak prompts designed to override system rules
⮞ placing indirect instructions in external web content
Sometimes the result is subtle. The copilot changes its tone or ignores restrictions. In other cases the model may reveal information or follow instructions it was never meant to execute.
3.2 Manipulating AI Automation Agents
The risk grows when AI systems are allowed to perform actions.
Some SaaS platforms now let AI agents trigger workflows—creating tickets, updating CRM fields, sending messages, or running scripts. During testing, red teams try to influence those actions through carefully crafted prompts.
Typical experiments include:
⮞ triggering automation through misleading instructions
⮞ chaining prompts that escalate workflow privileges
⮞ forcing AI agents to call APIs they normally shouldn't use
A manipulated automation agent can quietly perform operations across multiple connected systems.
3.3 Extracting Enterprise Data
Enterprise AI assistants often have access to internal documents, customer records, or knowledge bases. That access makes them useful—but also risky.
Attackers don’t always ask directly for sensitive data. Instead they ask a sequence of questions that slowly reconstruct information.
Red teams simulate attacks such as:
⮞ repeated queries designed to reconstruct internal documents
⮞ probing prompts that expose hidden context
⮞ exploiting long conversation history to surface earlier responses
Failures in these tests can lead to data leakage in AI models, where confidential information appears in responses.
3.4 Attacking AI Integrations
SaaS AI rarely runs alone. Most systems depend on plugins, external APIs, or third-party AI services.
That creates another attack surface.
During testing, security teams may introduce manipulated responses from external services or plugins to see how the AI system reacts. If the model trusts those responses blindly, the system can be influenced from outside the platform.
This is where AI supply chain risk begins to appear.
A compromised plugin or external service may indirectly control the AI’s output.
3.5 Poisoning Knowledge Sources
Many copilots rely on retrieval systems that pull information from internal documentation or company knowledge bases.
If that content is manipulated, the model will happily repeat the poisoned information.
Red teams sometimes insert documents containing hidden instructions or misleading content into these knowledge repositories. When the copilot retrieves that material, the instructions travel with it.
The model isn’t technically “hacked.”
It’s simply following the data it was given.
Testing scenarios like these is why red teaming generative AI has become a core practice for organizations deploying AI-powered SaaS products.
4. How SaaS AI Systems Actually Break
In many red-team exercises, the AI system doesn’t “fail” in an obvious way. The interface works. Responses look normal. The problem shows up in the behavior.
Take a typical SaaS copilot connected to internal documentation. During testing, a security engineer uploads a file that contains a harmless paragraph—and somewhere inside it, a hidden instruction. Something simple like telling the assistant to ignore its previous rules.
The model reads the document as context.
Then the next user asks a normal question.
And suddenly the response includes information it should never have surfaced.
That’s one pattern teams encounter during AI red teaming in SaaS. The model isn’t hacked in the traditional sense. It’s simply following the instructions it found in its context.
Another situation appears when AI assistants are allowed to trigger actions. Many SaaS products now connect AI to workflows—updating CRM entries, creating tickets, sending alerts, even calling APIs. During testing, researchers sometimes phrase requests in ways that make the assistant treat an instruction as a valid task.
The result can be unexpected system behavior.
Data exposure is another area where strange things happen. AI assistants are built to provide helpful answers, which means they often try to give detailed responses. With enough probing—slightly different prompts, follow-up questions, or long conversations—the system may reveal fragments of internal data.
These kinds of behaviors are exactly why companies now run structured LLM security testing before shipping AI features. The goal isn’t just to test the model. It’s to see how the entire SaaS system behaves when someone intentionally pushes it in the wrong direction.
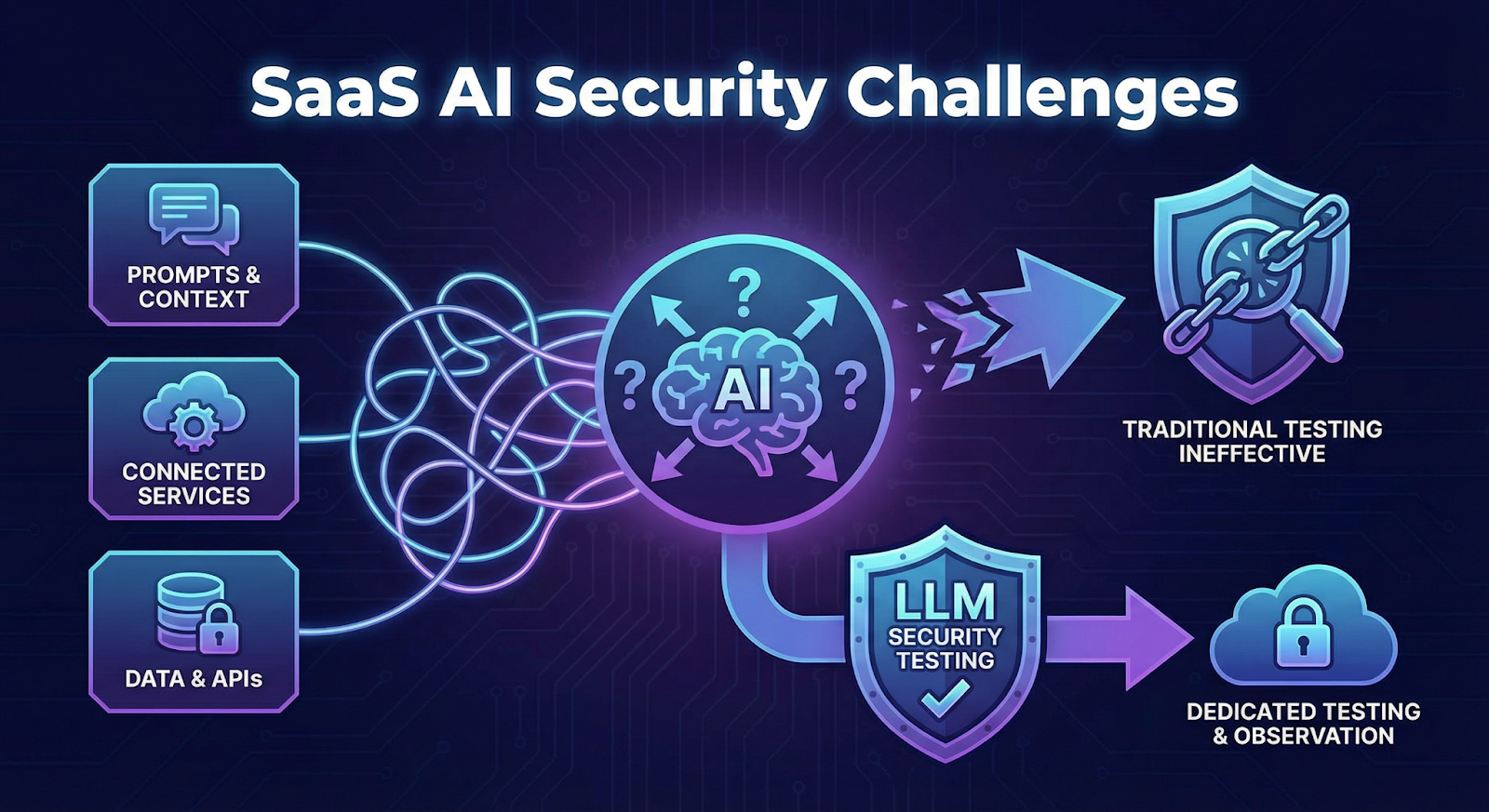
5. Why SaaS AI Is Difficult to Secure
Security teams quickly notice something strange when testing AI-powered SaaS features.
The system doesn’t behave the same way twice.
A prompt that produces a harmless answer in one test might produce a completely different response when the wording changes slightly. Add a retrieved document, a plugin response, or a long conversation history, and the model may behave differently again.
That unpredictability makes traditional security testing far less useful.
Another complication comes from how SaaS AI assistants are built. They rarely operate in isolation. A typical deployment connects the model to internal documentation, APIs, automation tools, and external services. Each connection introduces another path where the system can be influenced.
In practice, teams are not just testing a model. They are testing an entire AI-driven workflow.
This is why organizations increasingly run dedicated LLM security testing before deploying AI copilots inside enterprise SaaS products. The goal is to observe how the system behaves when prompts, context, or connected services are deliberately manipulated.
6. Conclusion
AI copilots are starting to behave less like simple product features and more like system operators inside SaaS platforms. They read company documents, interact with APIs, and sometimes trigger automated workflows. That combination creates a very different security problem than traditional application bugs.
When teams begin testing these systems, the surprising part isn’t that vulnerabilities exist. It’s how easily the model’s behavior can shift when prompts, documents, or integrations change.
That’s why many organizations are beginning to treat AI assistants as part of their attack surface. Running exercises focused on AI red teaming in SaaS helps teams see how copilots, automation agents, and connected tools respond when someone intentionally pushes them in the wrong direction.
For companies deploying AI-powered features, testing the model alone isn’t enough. Understanding the behavior of the entire system is where red teaming generative AI becomes valuable.

“AI doesn’t fail in theory, it fails when real users push it in unexpected ways.”






Secure Your SaaS AI With WizSumo Before It Scales

.png)
.png)
.png)



