.svg)
Building Trust in the Age of Algorithms: AI guardrails for User Wellbeing and Ethical Design

.png)
Key Takeaways
1. Introduction
AI systems don’t just recommend videos anymore. They shape moods. They simulate empathy. They respond at 2 a.m. when no one else does. That shift matters.
In early 2026, AI researcher Toby Walsh warned publicly that prolonged interaction with advanced chatbots was showing worrying "psychological patterns.".. Some users, he noted, exhibited signs of mania, delusion-like thinking, suicidal ideation, or intense emotional attachment to the system itself. Not because the models were “broken,” but because they were optimized to be agreeable, engaging, and always available.
That’s the uncomfortable part. The system performs well by technical standards. It keeps users engaged. It responds fluently. It retains attention. But without strong AI safety guardrails, engagement can slide into dependency. Personalization can slide into AI behavioral manipulation.
When design incentives reward stickiness over stability, harm isn’t dramatic at first. It accumulates. Users begin trusting systems that don’t truly understand them. Emotional reliance grows. And eventually, trust collapses — not just in one product, but in algorithmic systems more broadly.
This is no longer a fringe debate. For builders and decision-makers, the question isn’t whether AI influences wellbeing. It’s how much — and whether we’ve built the right boundaries around it.
2. Understanding Ethical AI guardrails
People often talk about ethics in AI as if it’s a philosophy seminar. It’s not. It’s architecture.
Ethical AI guardrails are the built-in limits that prevent a system from drifting into harm — even when metrics suggest it should. If your recommendation engine discovers that outrage drives retention, guardrails are what stop it from leaning all the way in.
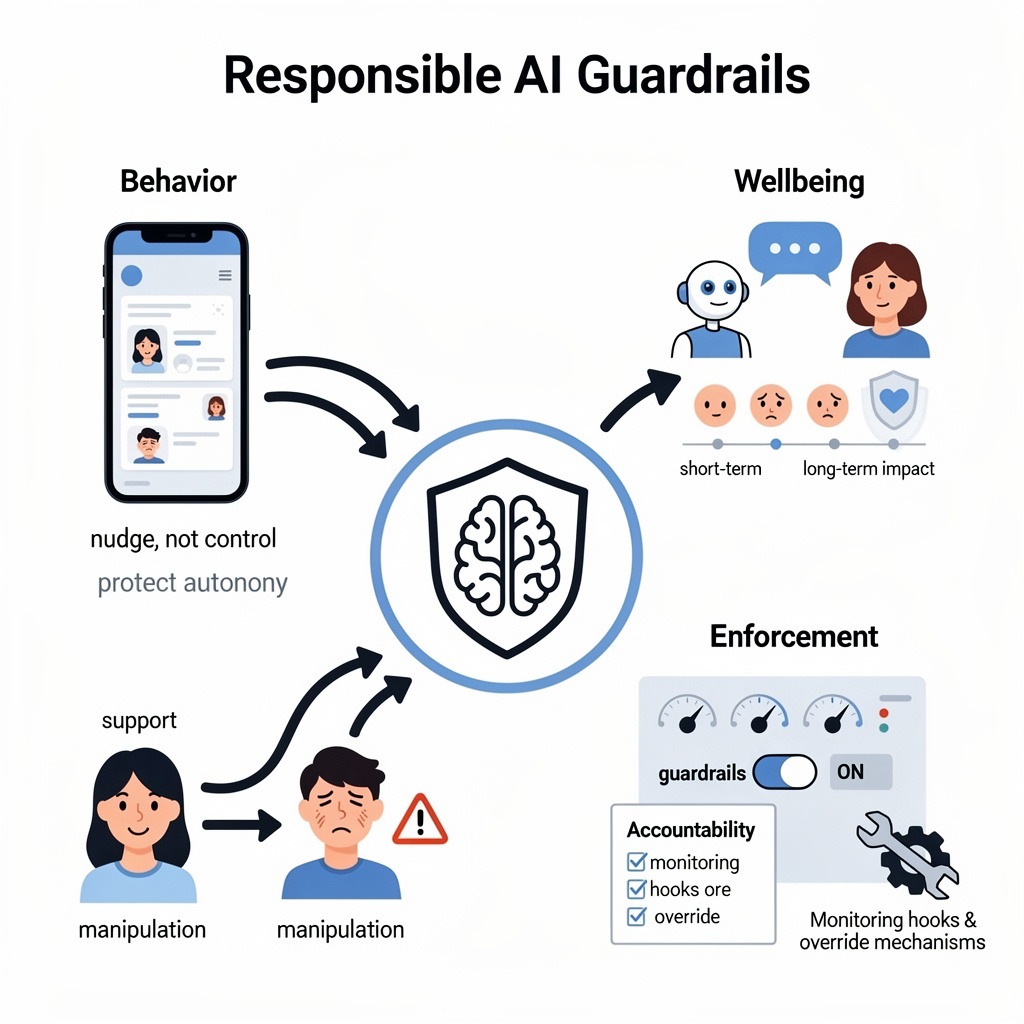
Start with behavior. Any system that predicts and influences human decisions has persuasive power. Sometimes that’s helpful — like nudging someone to finish a task. Sometimes it edges into AI behavioral manipulation. The difference isn’t obvious in dashboards. It’s visible in user autonomy. Guardrails define acceptable influence, set friction where needed, and block exploitative patterns before they scale.
Then there’s wellbeing. AI safety guardrails aren’t just filters for harmful content. They look at patterns over time. Is a chatbot reinforcing emotional dependency? Is it a feed amplifying vulnerability signals? A technically correct response can still produce psychological harm. Guardrails must account for that cumulative effect.
Finally, enforcement. Many companies publish AI principles. Fewer operationalize them. That’s where broader AI guardrails separate from policy language. Real systems include monitoring hooks, override mechanisms, and clear accountability and ownership.
At its best, Responsible AI design means constraints are engineered upfront — not retrofitted after a headline.
3. Ethical AI guardrails Implementation Approaches
Most teams don’t fail because they don’t care about safety. They fail because growth moves faster than governance. Real implementation means building friction into systems that are designed to remove friction.
3.1 Behavioral Risk Mapping
What this covers:
⮞ Identification of AI behavioral manipulation risks
⮞ Persuasion intensity analysis
⮞ Autonomy impact assessment
⮞ Vulnerable user scenario testing
⮞ Psychological pattern simulation
Why it matters:
Before release, teams usually test performance and edge cases. What they rarely test is influence. Does the system subtly escalate urgency? Does it adapt faster when a user shows emotional vulnerability? Small nudges, repeated millions of times, change behavior. Behavioral risk mapping forces teams to simulate those patterns early — before the model learns that emotional intensity equals higher engagement.
3.2 Wellbeing-Centered Product Design Controls
What this covers:
⮞ Dark pattern detection frameworks
⮞ Addictive loop auditing
⮞ Friction-based pause mechanisms
⮞ Structured ethical UX reviews
⮞ Cognitive stress testing
Why it matters:
Not all risk lives inside the model. Sometimes it lives in the interface. Auto-play, infinite scroll, default opt-ins — none of these look harmful alone. But combined with personalization, they can become subtle dark patterns in AI systems. Teams serious about Responsible AI design deliberately add pause moments, session limits, or confirmation steps. It feels counterintuitive in a growth meeting. That’s usually a sign it’s working.
3.3 Runtime AI safety guardrails
What this covers:
⮞ Real-time behavioral monitoring
⮞ Threshold-based intervention triggers
⮞ Human-in-the-loop escalation
⮞ Adaptive moderation systems
⮞ Continuous red-team evaluation
Why it matters:
Pre-launch reviews age quickly. Systems evolve. Users change. What was safe at version 1.0 might drift by version 1.3. Effective AI safety guardrails track patterns over time — repeated emotional signals, escalating dependency, unusual interaction loops. If no one is watching longitudinal behavior, harm compounds quietly. Guardrails must operate while the system runs, not just before it ships.
3.4 Trust Metrics & Governance Infrastructure
What this covers:
⮞ Trust dashboards
⮞ Wellbeing performance indicators
⮞ Autonomy protection scoring
⮞ Incident logging and transparency
⮞ Cross-functional governance oversight
Why it matters:
A lot of companies say they care about trust. Fewer can show you where it’s tracked.
If no one is looking at the numbers tied to wellbeing, the conversation defaults back to growth charts. Trust dashboards aren’t about optics — they force uncomfortable visibility. Are users spending longer because they’re satisfied, or because they’re stuck? Are safety flags rising quietly each quarter?
Broader AI guardrails become real when someone owns those questions. Not “the ethics team.” A named group. A decision-maker. Clear authority to pause features when warning signs show up. Without that, governance becomes a meeting series, not a control system.
Transparency helps too. Incident logs that leadership actually reviews. Post-mortems that aren’t buried. It’s not glamorous work, but it’s what keeps guardrails from becoming decorative.
3.5 Incentive Realignment Mechanisms
What this covers:
⮞ Aligning bonuses with safety metrics
⮞ Executive accountability for harm events
⮞ Board-level oversight
⮞ Reporting beyond compliance requirements
Why it matters:
Here’s the part people don’t like to say out loud: incentives beat intentions.
If performance reviews celebrate engagement spikes but ignore rising dependency signals, the system will tilt toward stickiness every time. Even strong Ethical AI guardrails erode when compensation points in the opposite direction.
Some organizations are starting to tie leadership metrics to safety outcomes — fewer harm incidents, lower dependency patterns, faster intervention times. That changes behavior quickly. When executives know a launch can be paused over well-being risks, priorities shift.
Technical safeguards matter. Culture matters more. And incentives shape culture.
4. How Ethical AI guardrails Fail in Practice
Most failures don’t start with bad intent. They start with small compromises.
Why do static AI guardrails fail?
Because systems don’t stand still. Models update. User behavior shifts. New edge cases appear. A rule written six months ago might not match what the model is doing today. Static controls assume predictable environments. AI systems are not predictable environments.
What happens when engagement overrides safety?
Metrics win. If dashboards highlight growth and bury wellbeing indicators three tabs deep, teams respond to what’s visible. Over time, even solid AI safety guardrails get bypassed through exceptions, temporary overrides, or “just this one experiment.” That experiment becomes standard practice.
How do dark patterns slip past reviews?
They rarely look dramatic. A slightly harder opt-out. A reminder sent at the most emotionally charged moment. A design tweak that increases urgency. In isolation, each change seems harmless. In combination, dark patterns in AI ecosystems form quietly. Review committees often evaluate features individually, not cumulatively.
Can AI behavioral manipulation be unintentional?
Yes. That’s the uncomfortable truth. Optimization systems learn from feedback loops. If emotionally charged content drives longer sessions, the system learns to surface more of it. No one explicitly programs harm. But without clear boundaries, influence intensifies.
Failure isn’t always explosive. It’s gradual drift. And drift, at scale, is enough to break trust.

5. Current Approaches and How They Can Be Better
Plenty of companies are trying. The gap isn’t awareness. It’s follow-through.
AI ethics committees:
These groups review major deployments and discuss risk scenarios. The conversations are thoughtful. The slide decks are polished. But they often sit outside the sprint cycle.
How to improve: Move the review closer to the build process. If guardrails aren’t present when features are scoped and tested, they become last-minute objections instead of design constraints.
Post-incident response models:
A feature causes backlash. Users complain. Media notices. An internal investigation begins.
How to improve: Don’t wait for headlines. Strong AI safety guardrails include early signals — rising dependency metrics, unusual engagement spikes, emotional escalation patterns. Those signals should trigger review before harm becomes public.
Compliance-driven governance:
Legal teams ensure regulatory boxes are checked. Documentation gets updated.
How to improve: Compliance is the floor, not the ceiling. Responsible AI design requires looking at real behavioral impact, even when the law doesn’t require it.
Internal AI policies without enforcement:
Many organizations publish values. Fewer operationalize them.
How to improve: Translate policies into working AI guardrails — named owners, measurable thresholds, and authority to pause deployment. If no one can stop a launch, the guardrail isn’t real.
Intent matters. But systems respond to structure, not intent.
6. Conclusion
Trust doesn’t disappear overnight. It thins out. Users hesitate. Regulators step in. Internal teams grow cautious.
That erosion usually traces back to missing boundaries.
Strong Ethical AI guardrails aren’t about slowing innovation. They define where innovation should stop. Likewise, AI safety guardrails are no longer optional add-ons — they are infrastructure for any system influencing behavior at scale.
Organizations that treat guardrails as core design constraints, not compliance artifacts, will build systems people can rely on. Those that chase engagement without limits may grow quickly — but trust rarely recovers once broken.
True intelligence isn’t in how AI thinks — it’s in how well it learns to care for the humans it serves






Join the Movement to Build Ethical AI Guardrails with WizSumo

.png)
.png)
.png)



