.svg)
Everything You Need To Know About AI Guardrails

.png)
Key Takeaways
AI guardrails keep innovation safe, ethical, and aligned with human intent.
Without guardrails for AI systems, intelligence can quickly become instability.
Real-world AI failures prove that safety must evolve alongside capability.
AI safety frameworks and generative AI guardrails make trust scalable.
The future of AI belongs to those who innovate responsibly, not recklessly.
1. Why AI Guardrails Became Critical Infrastructure
AI systems are being plugged into real business workflows — not demos, not labs, but daily operations. They draft contracts, answer customers, summarize reports, and sometimes even make recommendations that influence decisions. That’s a lot of authority for software that can still get things wrong.
And here’s the thing. Intelligence doesn’t equal reliability.
A model can sound confident while being incorrect. It can follow instructions while exposing sensitive data. It can optimize for helpfulness while ignoring policy boundaries. That gap between capability and control is exactly why AI guardrails matter.
AI safety guardrails exist to enforce limits. They define what the system can do, what it must refuse, and how it behaves under pressure. Not as guidelines. As built-in constraints.
As AI moves deeper into production systems, guardrails aren’t enhancements. They’re the difference between controlled automation and unmanaged risk.
2. What AI Guardrails Actually Mean
Let’s clear something up first.
AI guardrails are not policy PDFs. They’re not ethics statements. And they’re definitely not slide-deck promises about “responsible AI.”
They are technical control mechanisms built into AI systems to enforce behavior.
At a practical level, guardrails sit between the model and the real world. They inspect inputs. They constrain model behavior. They validate outputs. If something violates predefined boundaries — harmful content, sensitive data exposure, "policy conflicts" — the guardrail intervenes.
That’s what separates them from general AI governance. Governance defines principles and accountability structures. "Guardrails" enforce those principles at runtime.
AI safety guardrails are the operational layer that translates policy into action. Without them, governance remains theoretical.
This is also where structured AI risk mitigation begins. Risk mitigation isn’t only about identifying threats. It’s about embedding controls that prevent those threats from materializing in live systems.
In short: governance sets direction. Guardrails enforce boundaries.

3. The Complete Architecture: Types of AI Guardrails
Most teams think about guardrails as a filter sitting at the end of the pipeline. Something that checks the final answer and blocks the obvious bad stuff.
That’s only one piece.
The real types of AI guardrails form a layered system. Each layer handles a different kind of risk. And the layers don’t behave equally — some prevent problems, others contain them.
Let’s break it down properly.
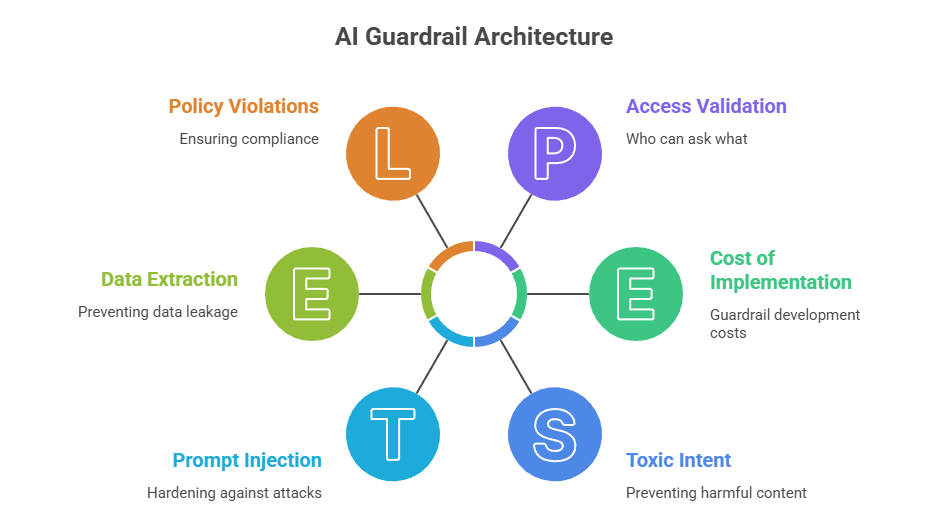
3.1 Input Guardrails
This is the first checkpoint. Before the model even responds.
Input controls examine prompts for injection attempts, data extraction patterns, toxic intent, or role manipulation. If someone tries to override instructions (“ignore previous rules…”), escalate privileges, or force unsafe outputs, this layer catches it early.
It also includes access validation — who is allowed to ask what. That’s often overlooked.
When input guardrails are weak, everything downstream becomes damage control.
3.2 Model-Level Guardrails
Now we’re inside the model.
This is where alignment training, safety conditioning, bias correction, and reinforcement learning influence behavior. These controls don’t block a specific request. They shape how the system interprets and prioritizes instructions.
Done well, they reduce unsafe tendencies before output filtering ever runs.
Done poorly, you rely on post-processing to clean up unstable behavior.
3.3 Output Guardrails
This is the most visible layer — and the one companies overuse.
Output controls review generated content for policy violations, hallucinated facts, restricted topics, or unsafe recommendations. Some systems apply confidence scoring and force a refusal if uncertainty is too high.
Output moderation is important. But on its own? It’s reactive.
You can’t filter your way out of architectural weakness.
3.4 System & Oversight Guardrails
Beyond prompts and outputs, there’s infrastructure.
Logging, monitoring, escalation paths, audit trails — these are operational AI governance controls. They ensure someone can trace what happened, when it happened, and why.
This is also where human review enters the loop. Not for every response, but for high-risk contexts.
Without system-level oversight, guardrails become invisible and unenforceable.
3.5 LLM-Specific Guardrails
Large language models behave differently from rule-based systems.
They predict. They generalize. They improvise.
Strong LLM guardrails address prompt injection hardening, context separation, tool-use restrictions, and sensitive data redaction. They assume the model will be creative — and design constraints accordingly.
Put together, these layers create structured AI risk mitigation. Remove one, and risk shifts rather than disappears.
Guardrails aren’t a single switch. They’re an ecosystem.
4. How to Implement AI Safety Guardrails Properly
There’s a common mistake teams make. They choose a moderation tool, plug it in at the output layer, and call it done. That’s not implementation. That’s containment.
Building AI safety guardrails begins earlier — at system design. Before deployment, teams need to define what the model should never do, what it can do conditionally, and where human escalation is required. Those boundaries must translate into enforceable controls across inputs, model behavior, and outputs.
Testing matters more than documentation. Run adversarial prompts. Try to break the system. Force edge cases. If the guardrail only works under polite usage, it isn’t ready.
Operationally, guardrails need visibility. Logs. Monitoring. Alerting. Someone reviewing patterns, not just single outputs. That’s where strong AI guardrails stay effective over time.
And ownership can’t be vague. If responsibility for safety is scattered, enforcement weakens. A structured AI risk mitigation model clarifies who designs controls, who validates them, and who responds when they fail.
Implementation isn’t about maximum restriction. It’s about controlled behavior under real-world pressure.
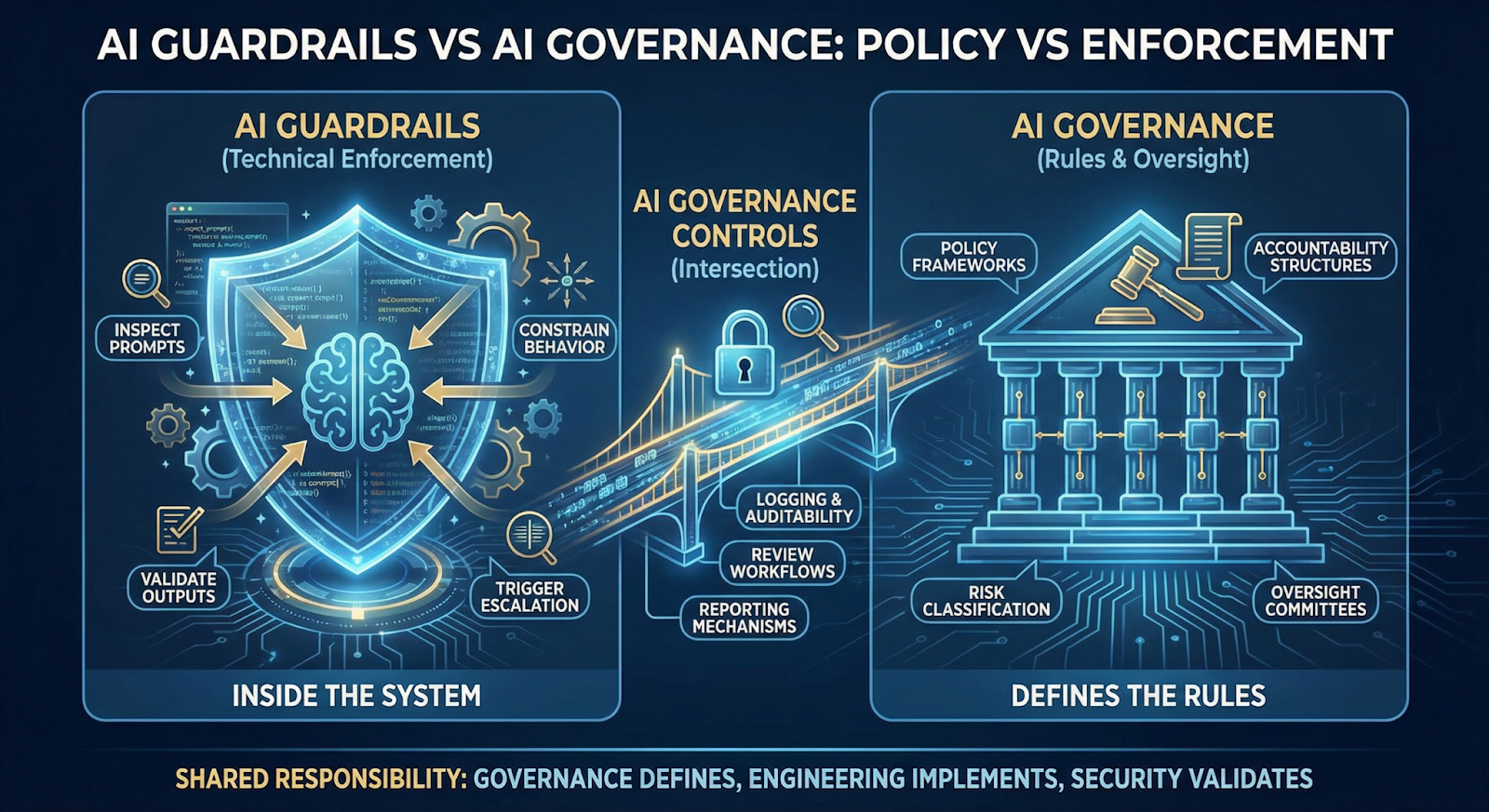
5. AI Guardrails vs AI Governance
These two terms get mixed up constantly. They shouldn’t.
AI guardrails are technical enforcement mechanisms. They live inside the system. They inspect prompts, constrain behavior, validate outputs, and trigger escalation when boundaries are crossed.
Governance, on the other hand, defines the rules of the game. It includes policy frameworks, accountability structures, risk classification models, and oversight committees. Governance answers what should happen. Guardrails enforce what actually happens.
Here’s the practical difference:
If a policy says the system must not disclose sensitive data, governance defines that rule. Guardrails detect and block the disclosure in real time.
This is also where AI governance controls intersect with engineering. Logging, auditability, review workflows, and reporting mechanisms connect policy intent with technical enforcement.
Who owns this? Governance leaders define standards. Engineering teams implement AI safety guardrails. Security and compliance validate them. Responsibility is shared — but enforcement must be explicit.
Confusion between policy and enforcement is where most safety gaps begin.
6. The Future of AI Safety Guardrails
AI systems aren’t staying still. They’re being connected to tools, databases, workflows, even financial systems. The more access they get, the more their decisions carry weight.
That changes the job of AI safety guardrails.
It’s no longer enough to block toxic outputs. Guardrails will need to evaluate "behavior" across sessions, monitor tool usage, and detect subtle misuse patterns. Some controls will become dynamic — adjusting based on "context" rather than relying on fixed rules.
At the same time, regulators are asking harder questions. Can you prove your safeguards work? Can you trace a decision? Can you intervene quickly? That pressure makes AI guardrails part of operational readiness, not just technical hygiene.
The future isn’t about tighter restrictions. It’s about smarter enforcement.
Systems that are powerful but loosely controlled will struggle. Systems designed with disciplined boundaries will scale more safely — and more sustainably.

Let’s work together to turn your AI vision into a system the world can trust






Start Your AI Guardrails Journey with WizSumo

.png)
.png)
.png)



