.svg)
Guarding the Future: Technical Robustness & Security Guardrails for Responsible AI

.png)
Key Takeaways
1. Why Technical Robustness in AI Is No Longer Optional
Technical robustness in AI is not about performance metrics. It’s about survival under pressure. When an AI system faces unexpected input, adversarial manipulation, or abnormal operating conditions, robustness determines whether it degrades safely or collapses unpredictably.
Modern AI systems don’t just process data. They "interact" with users, APIs, databases, and external services. Every connection expands the attack surface. Without strong AI security guardrails, small weaknesses become entry points. And entry points become incidents.
We’ve already seen real AI failure incidents where models were manipulated through "crafted inputs", exposing system behavior that was never meant to be public. These failures weren’t caused by advanced exploits. They were design oversights — missing controls, weak validation, assumptions that the model would “behave.”
2. What Technical Robustness in AI and AI Security Guardrails Really Mean
Ask any engineer what Technical robustness in AI means and you’ll get different answers. Accuracy. Stability. Performance under stress. All true — but incomplete.
Robustness shows up when assumptions fail.
AI systems don’t operate in clean lab conditions. They face strange inputs, repeated queries, edge cases nobody predicted. Some inputs are accidental. Some are intentional. Either way, the system must respond without exposing internal logic or breaking expected behavior. When it can’t, overall AI vulnerability risk rises fast.
There are three practical layers to this.
First, resistance. Can the model handle abnormal or malicious inputs without being steered off course?
Second, containment. If something behaves unexpectedly, does the failure stay local — or ripple outward?
Third, enforcement. This is where AI security guardrails matter. They define boundaries: who can access what, which inputs are accepted, how misuse is detected. Safety guardrails focus on content. Security guardrails focus on control.
Without those layers working together, robustness becomes a marketing term instead of an engineering reality.

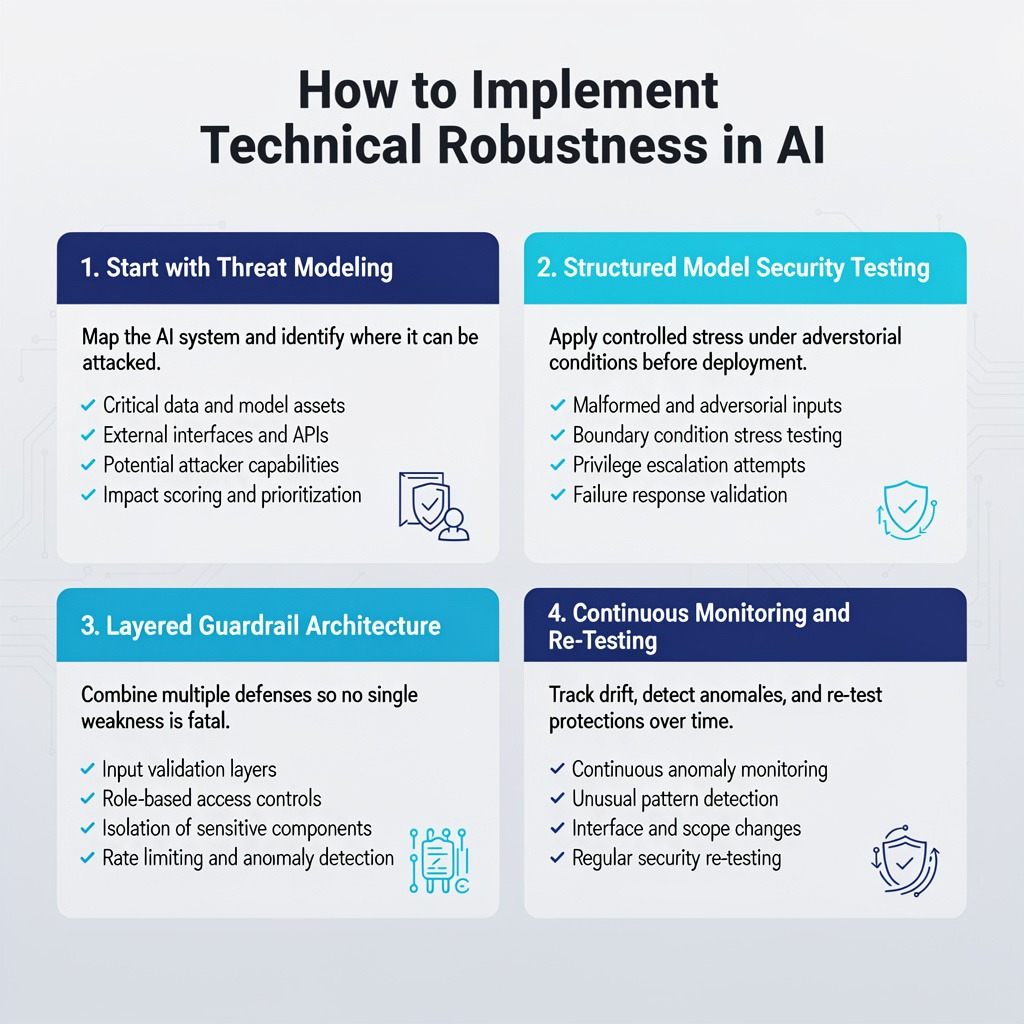
3. How to Implement Technical Robustness in AI
You don’t get Technical robustness in AI by adding a filter at the end. It has to be engineered in.
3.1 Start with Threat Modeling
Before writing more code, map the system. Formal threat modeling for AI forces teams to identify assets, entry points, trust boundaries, and abuse paths.
What this covers:
⮞ Critical data and model assets
⮞ External interfaces and APIs
⮞ Potential attacker capabilities
⮞ Impact scoring and prioritization
Without this step, teams underestimate AI vulnerability risk because they only test what they expect — not what an attacker will try.
3.2 Structured Model Security Testing
What is model security testing in practice? It’s controlled stress under adversarial conditions.
What this covers:
⮞ Malformed and adversarial inputs
⮞ Boundary condition stress testing
⮞ Privilege escalation attempts
⮞ Failure response validation
Why does model security testing matter before deployment? Because once exposed to users, weaknesses are discovered publicly.
3.3 Layered Guardrail Architecture
Strong AI security guardrails don’t rely on one defense.
What this covers:
⮞ Input validation layers
⮞ Role-based access controls
⮞ Isolation of sensitive components
⮞ Rate limiting and anomaly detection
Layering prevents a single weakness from turning into a system-wide compromise.
3.4 Continuous Monitoring and Re-Testing
Robustness erodes. Models drift. Interfaces expand.
Continuous monitoring tracks "unusual" patterns, unexpected behaviors, and emerging gaps.. Regular re-testing ensures today’s protections still work tomorrow..
That’s how Technical robustness in AI moves from theory to operational discipline.
4. Where AI Security Guardrails Break Down
Strong systems rarely fail because of one dramatic flaw. They fail because small gaps align.
Why do AI systems fail under attack?
Because assumptions slip into design. Teams assume users will behave normally. They assume APIs won’t be chained together in unexpected ways. When those assumptions collapse, AI security guardrails reveal whether they were engineered — or improvised.
One common weakness is incomplete threat modeling for AI. If abuse scenarios aren’t explored early, blind spots persist into production. Attackers don’t invent new physics. They exploit overlooked paths.
Why does model security testing often miss critical gaps?
Because it’s treated as a one-time exercise. Real environments evolve. Integrations expand. Permissions shift. Without continuous review, AI vulnerability risk quietly grows.
And then come the public examples, the AI failure incidents where crafted inputs expose hidden behavior or "bypass controls". In most cases, the root cause isn’t advanced exploitation. It’s weak boundary enforcement and fragile assumptions.
Guardrails don’t fail loudly at first. They fail gradually. Until they don’t.
5. Why Current AI Security Guardrails Are Not Enough
Here’s the uncomfortable part.
Most teams think their AI security guardrails are stronger than they actually are.
A few validation layers. Some access controls. Maybe logging. It looks solid in architecture diagrams. But diagrams don’t get attacked — deployed systems do.
The real weakness isn’t missing controls. It’s stagnation.
Controls are implemented once and rarely stressed again. Meanwhile, new APIs get connected. Prompts change. Usage patterns shift. The system evolves. The defenses don’t.
And even when model security testing is performed, it often focuses on known misuse patterns. Known risks are the easy ones. The edge cases — chained interactions, unexpected privilege inheritance, indirect exposure paths — those stay untested.
There’s also a subtle bias at play: if nothing has failed yet, the system must be stable. That assumption hides slow-building exposure.
Strong guardrails aren’t static structures. They’re pressure-tested continuously. Without that pressure, even well-designed protections weaken quietly — until something pushes hard enough.
6. What Organizations Should Do Now
Start earlier than you think.
Formal threat modeling for AI shouldn’t happen after deployment planning. It belongs at design stage — when architecture is still flexible and assumptions can be challenged without costly rework.
Next, make pressure normal. Continuous model security testing must be scheduled, repeated, and expanded. Not once per release. Not only before audits. Regularly. Systems change. Exposure follows.
Treat Technical robustness in AI as a measurable engineering objective. Define acceptable failure boundaries. Track containment effectiveness. Review drift signals.
And finally, embed AI security guardrails directly into system architecture. Don’t bolt them on as reactive controls. Isolation, access restriction, validation layers — these should be structural decisions.
Regulatory expectations around AI accountability are increasing. But external pressure shouldn’t be the motivation. Internal resilience should.
Organizations that operationalize robustness early avoid reactive scrambling later.
7. The Future of Technical Robustness in AI
There’s a shift happening.
Early AI conversations were about capability. Speed. Accuracy. Now the question is simpler: will the system hold up when something unexpected happens?
That’s where Technical robustness in AI earns its place. Not in demos. In production. Under stress.
Weak AI security guardrails rarely collapse on day one. They weaken quietly. A new integration here. A workflow shortcut there. Over time, the boundaries blur.
And then pressure exposes what wasn’t reinforced.
The future of responsible AI won’t be defined by how advanced the model is. It will be defined by how predictably it behaves when assumptions break.
Organizations that invest in structural resilience now avoid public lessons later.
That’s not a dramatic statement. It’s just how systems behave.

“AI doesn’t fail because it’s intelligent — it fails where its boundaries aren’t engineered.”






Secure your models with WizSumo — build AI safety and security guardrails that scale!

.png)
.png)
.png)



