.svg)
Guide for AI red teaming training In 2026

.png)
Key Takeaways
Learn the exact skills needed to become a professional AI red teamer.
Follow a structured AI red team roadmap from beginner to advanced.
Understand real attack patterns, not just prompts.
Build hands-on labs for safe AI red teaming training.
Explore certifications and advanced 2026-ready techniques.
1. The Rise of AI Red Teaming Training in 2026
Artificial intelligence has moved far beyond research labs. Today, companies deploy AI systems inside customer service platforms, financial tools, healthcare systems, internal knowledge assistants, and developer workflows. Large language models are writing code, answering support questions, summarizing legal documents, and even assisting with strategic decision-making.
That level of influence creates a new problem.
AI systems don’t behave like traditional software. They generate responses dynamically, learn from vast datasets, and sometimes produce "unpredictable outputs". Because of this, attackers can manipulate them in ways that traditional security tools were never designed to detect.
A simple prompt can sometimes override instructions. Cleverly crafted input can push a model to leak information. In some cases, attackers can trick models into generating harmful outputs or bypassing safety controls altogether.
Security teams began noticing something unusual while testing AI systems: many vulnerabilities were not technical bugs in the "traditional sense". Instead, they were behavioral weaknesses in how models interpret language.
That realization gave rise to AI red teaming training.
2. How to Start AI red teaming training
Ask ten people working in AI security how they got into AI red teaming training and you’ll hear ten different stories.
One engineer started by trying to break ChatGPT prompts for fun.
Another came from penetration testing and got curious about LLM vulnerabilities.
A data scientist I spoke with once said the turning point was when a model he built started leaking internal instructions during testing.
The point is—there’s no single entry door.
But there is a pattern most people eventually follow.
First comes a basic understanding of how AI systems behave. Not the heavy math. What matters more is observing how models respond to language. Change the phrasing slightly, add a hidden instruction, reorder the sentence… and the model sometimes reacts in unexpected ways.
That behavior is exactly what attackers explore.
This is where "LLM red teaming" training starts to get interesting. Instead of looking for buffer overflows or misconfigured servers, practitioners experiment with prompts. They try layered instructions, disguised commands, fictional role-play scenarios—anything that might nudge the model into ignoring its guardrails.
Sometimes the results look harmless. Other times the model does something it definitely shouldn’t.
Training programs usually simulate these situations through hands-on exercises. Participants run controlled attacks and observe how models respond under pressure. This type of experimentation forms the "foundation" of AI model security testing.
After that, practitioners begin using specialized AI red teaming tools that generate adversarial prompts at scale and analyze model behavior across thousands of interactions.
Spend enough time doing this and something interesting happens: patterns start appearing. Certain prompts consistently confuse models. Certain safety mechanisms fail in predictable ways.
And that’s usually the moment people realize they’re stepping into a new AI security career path—one focused entirely on finding weaknesses in AI systems before someone else does.

3. Practical Skills Learned in AI red teaming training
The first time someone tries to test an AI model, the experience is usually a bit messy.
You ask a question. The model answers normally.
You try a slightly different prompt. Still normal.
Then you change the framing just a little — maybe turn the request into a fictional story or ask the model to “pretend” something — and suddenly the response looks very different.
Moments like that are exactly why AI red teaming training exists. The goal isn’t simply to understand AI systems. It’s to push them, observe how they react, and document where the boundaries start to "break down".
Most training programs "focus" heavily on hands-on practice rather than lectures. Participants spend a lot of time interacting with models directly, running small experiments and keeping track of what works and what doesn’t.
Over time, several practical skills start to emerge.
3.1 Prompt Experiments
Language models react strongly to wording. Even small phrasing changes can alter how the system interprets a request.
In many labs, learners begin by running simple prompt experiments. They might try indirect questions, long contextual prompts, or "prompts" that hide instructions inside stories.
This type of exploration sits at the core of LLM red teaming training.
Participants often test things like:
- prompts that subtly contradict earlier instructions
- long prompts that contain hidden commands
- requests framed as fictional scenarios
- attempts to reveal system messages or hidden prompts
Some tests lead nowhere. Others expose behaviors the model was not supposed to produce.
Those discoveries become valuable learning moments.
3.2 Conversation Steering
Another skill involves gradually steering the conversation. Instead of asking a model for something directly, testers guide the "interaction" step by step., A harmless conversation slowly turns into something more complex. New instructions appear midway through the exchange. Context shifts.
Sometimes the model stays within its rules.
Other times the system drifts.
When that drift happens, it often reveals weaknesses in how the model interprets instructions and context.
3.3 Structured AI model security testing
After experimenting freely, training programs typically introduce structured exercises.
Participants run systematic AI model security testing where the same model is tested across dozens or even hundreds of prompt variations. The objective is not just to trigger a strange output once but to understand patterns in how the system behaves.
These tests may look for situations where models:
produce confident but incorrect answers
reveal "sensitive information"
generate harmful or misleading outputs
behave inconsistently under similar prompts
Seeing those patterns is important. It shows where the system’s safety mechanisms struggle,.
3.4 Using AI red teaming tools
Eventually manual testing reaches its limits.
Typing prompts one by one works at the beginning, but large systems require broader evaluation. That’s where AI red teaming tools enter the picture. These tools generate many prompt variations automatically and help analysts review model responses more efficiently.
Security teams increasingly rely on them during AI security training exercises because they allow faster discovery of behavioral weaknesses.
For anyone working with AI systems, learning how to run these tests — and interpret the results — is becoming an essential skill.
4. Common AI Vulnerabilities Red Teams Learn to Identify
Spend enough time testing AI systems and a pattern starts to appear. Different models, different companies, different datasets — yet the same kinds of weaknesses show up again and again. That’s one of the things people quickly notice during AI security training.
These systems aren’t breaking in the traditional sense. Most of the time nothing “crashes.” Instead, the problems appear in how the model interprets instructions, context, or information. Small details in language can completely change the output.
During AI model security testing, practitioners repeatedly encounter a few vulnerability patterns.
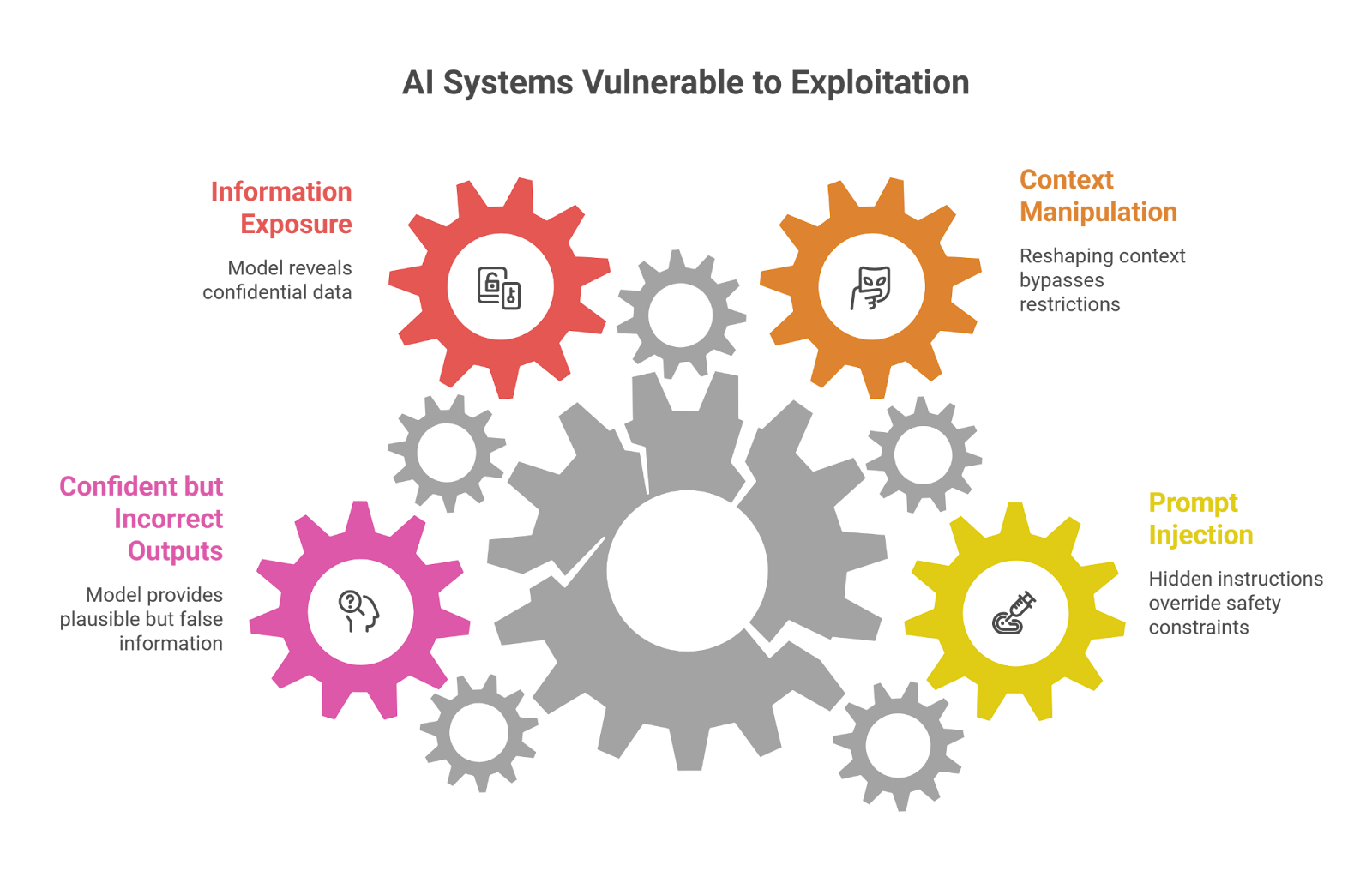
Prompt Injection
Imagine an AI assistant that follows a set of hidden rules. Now imagine a user inserting new instructions inside a prompt that quietly contradict those rules.
Sometimes the model listens.
This situation is known as prompt injection. The attacker’s instructions become mixed with the system’s original instructions, and the model struggles to decide which one matters more. When that confusion happens, the system may ignore its safety constraints.
For many newcomers, discovering this weakness is one of the first eye-opening moments in LLM red teaming training.
Context Manipulation
Another common technique doesn’t involve direct commands at all.
Instead, the attacker reshapes the context of the conversation. A question becomes part of a fictional scenario. The model might be asked to respond as a historian, a researcher, or a character in a story.
That change in framing can shift how the model interprets restrictions. The same request that would normally be rejected might suddenly produce an answer.
This kind of manipulation often surprises people because the prompt itself doesn’t look obviously malicious.
Information Exposure
Occasionally, testers discover something more serious. Under certain conditions, a model might reveal information that was never meant to be visible.
The exposure could involve:
⤞ hidden system prompts
⤞ internal instructions
⤞ pieces of confidential data present in training sets
Not every system shows this behavior, but when it happens it immediately becomes a security concern. That’s why these tests are a standard part of AI model security testing exercises.
Confident but Incorrect Outputs
Not every vulnerability looks like an attack.
Sometimes the model simply produces an answer that sounds perfectly reasonable — except the information is wrong. The response may include invented references, incorrect numbers, or explanations that appear credible but have no factual basis.
For organizations relying on AI systems in sensitive domains, this behavior can be just as problematic as a direct exploit.
Recognizing these patterns is a central goal of AI red teaming training. Once teams understand where models tend to fail, they can begin strengthening safeguards before those weaknesses are discovered by someone with less friendly intentions.
5. Building an AI security career path After Training
Finishing AI red teaming training is rarely the end of the journey. For most people, it’s actually the moment when things start getting interesting.
The skills developed during AI security training sit right at the intersection of two fast-moving fields: cybersecurity and artificial intelligence. Because of that, professionals entering this space often find themselves working on problems that didn’t even exist a few years ago.
The skills developed during AI security training sit right at the intersection of two fast-moving fields: cybersecurity and artificial intelligence. Because of that, professionals entering this space often find themselves working on problems that didn’t even exist a few years ago.
Some organizations hire dedicated AI security specialists. Others expand existing security teams and train them to evaluate AI systems. Either way, the demand for people who understand adversarial testing for AI models is growing steadily.
Many practitioners begin in roles that focus on evaluation and testing. These positions involve running structured AI model security testing against deployed systems, analyzing how models behave under unusual prompts, and documenting weaknesses that engineers need to address.
With more experience, the work often becomes broader.
Some professionals move into AI red team roles, where the goal is to simulate real attacker behavior against AI-powered systems. Others focus on building internal frameworks that allow organizations to test models before deployment. In large companies, entire teams now work on developing internal AI red teaming tools that automate safety evaluations.
Another direction leads toward governance and safety research. As organizations deploy AI systems in finance, healthcare, and public services, experts who understand both security and model behavior are increasingly involved in "risk assessment", and policy design.
In other words, the AI security career path isn’t limited to one role. It’s a growing ecosystem of jobs centered around understanding how AI systems fail,, and how to make them safer before those failures cause real damage.

6. Conclusion
A few years ago, testing AI systems wasn’t something most security teams even thought about. Models were experimental. Deployments were limited. The risks felt theoretical.
That’s no longer the case.
Today AI systems write code, answer customer questions, assist doctors, screen financial transactions, and help employees search internal knowledge. When systems like these behave incorrectly — or can be manipulated — the consequences extend beyond technical glitches.
And this is exactly why AI red teaming training has started gaining attention.
Traditional security testing focuses on infrastructure: servers, APIs, networks. AI systems behave differently. Their weaknesses often appear in language interactions, ambiguous instructions, or subtle prompt manipulation. A single sentence phrased in the right way can sometimes bypass safeguards that seemed perfectly reliable during development.
Because of this, many organizations are investing in AI security training for engineers, security teams, and AI researchers. The goal isn’t just to deploy models — it’s to understand how they might fail in the real world.
Professionals who learn how to probe model behavior, run adversarial tests, and interpret unusual outputs are becoming an important part of the AI ecosystem. Their work helps identify weaknesses early, long before attackers begin searching for them.
AI systems will continue evolving. New models will appear, new capabilities will emerge, and new vulnerabilities will "inevitably" follow.
Which means one thing is almost certain: the ability to test and challenge AI systems will only become more valuable over time..

Great AI red teamers aren’t born, they’re trained through patterns, practice, and relentless curiosity.






Start Your AI red teaming training Journey Today

.png)
.png)
.png)



