.svg)
How to Implement AI guardrails in 2026: The Complete Enterprise Guide

.png)
Key Takeaways
AI guardrails are mandatory in 2026 for safety, compliance, and governance.
Guardrails implementation requires layered policies, controls, monitoring, and oversight.
Enterprises must combine model-level and application-level guardrails for full coverage.
Modern guardrail tools and frameworks enable scalable and automated AI safety.
Continuous testing and red teaming are essential to keep guardrails effective.
1. Introduction
A lot of companies rushed into generative AI before they fully understood what they were connecting it to.
Someone plugs an LLM into an internal knowledge base. Another team connects a model to customer support tickets. A developer wires an AI assistant directly into a database query tool. At first, everything looks impressive. The AI answers questions, summarizes documents, and helps employees move faster.
Then the weird things start happening.
A model shares internal documentation in a response. A prompt trick makes the system ignore its instructions. A chatbot generates advice that clearly breaks company policy. None of this usually happens because someone “hacked” the system in the traditional sense. Most of the time the model simply follows instructions too literally or fails to understand context the way humans do.
That’s the uncomfortable truth about deploying AI inside real organizations: models are powerful, but they’re also unpredictable.
This is where AI guardrails enter the picture.
Instead of trusting the model to behave perfectly, guardrails add control layers around it. They inspect incoming prompts, limit what the model can access, evaluate responses before they reach users, and log activity for monitoring. In other words, they act like the safety boundaries of an AI system.
For enterprises rolling out AI tools across departments, AI guardrails implementation quickly becomes part of a larger enterprise AI governance effort. Security teams want visibility. Risk teams want accountability. Product teams want AI that doesn’t suddenly generate something harmful.
When done correctly, guardrails don’t slow innovation — they make it sustainable. They give organizations a practical way to scale AI systems while protecting users, internal data, and overall AI trust and safety.
2. Understanding AI Guardrails
Let’s pause for a second and look at how AI systems actually behave in production. Not the demo version. The messy, real-world version.
Someone asks a chatbot for a summary of an internal document. Another user asks the model to write code that interacts with a database. Meanwhile an automated workflow feeds the model hundreds of prompts every hour. All of these interactions look simple on the surface, but behind the scenes the model is making probabilistic guesses about what the next word should be.
That guessing process is powerful. It’s also the reason models sometimes say things they shouldn’t.
A model might confidently generate incorrect information. It might follow a cleverly written prompt that tells it to ignore previous instructions. Occasionally it even reveals information embedded in context or training data. Situations like these are the reason organizations started building AI guardrails around their systems instead of relying entirely on the model itself.
Think of guardrails less like a filter and more like traffic signals across the AI pipeline. Different checkpoints evaluate different parts of the interaction.
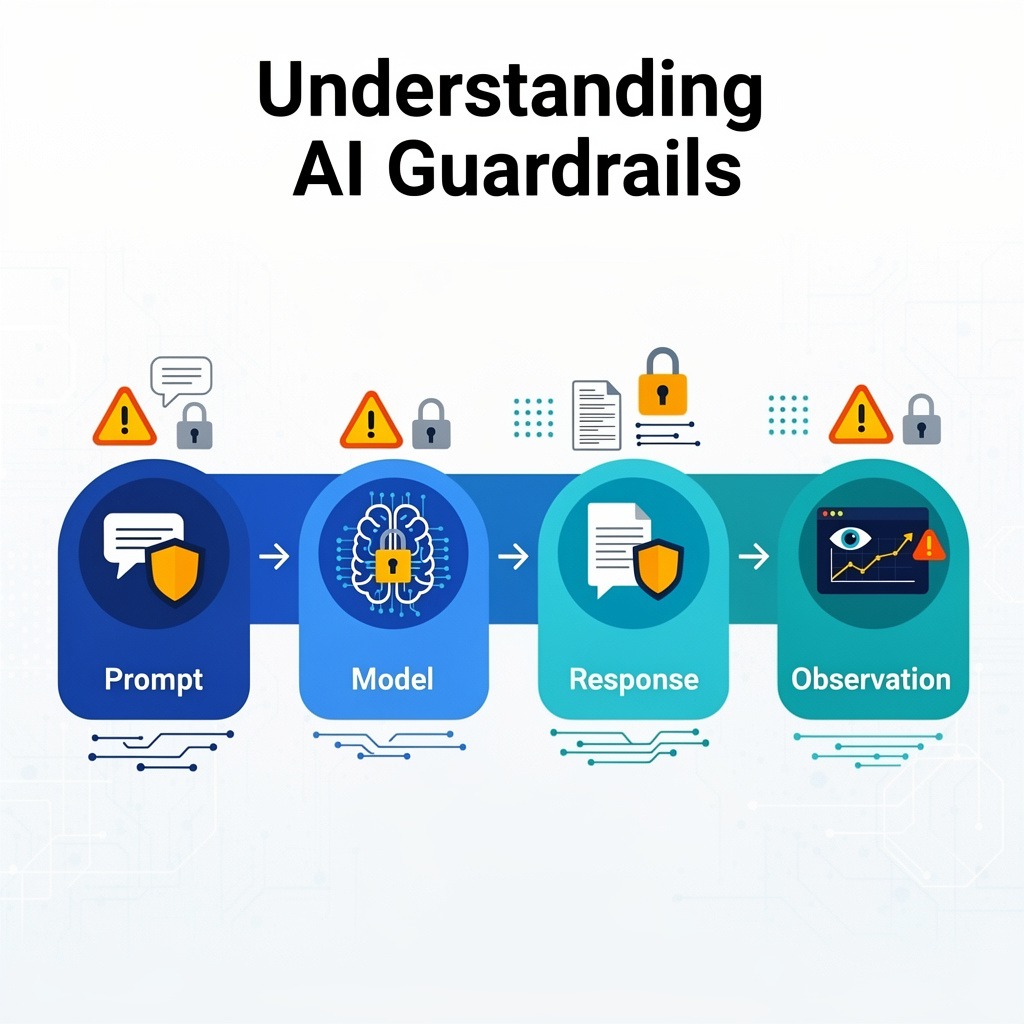
2.1 The Prompt Stage
Before the model even begins generating a response, the system can inspect the incoming prompt.
This is where many manipulation attempts show up. Prompts might try to override safety instructions, inject hidden commands, or trick the model into revealing restricted information. Guardrail systems can flag or block these requests before the model processes them.
Another practical use of this layer is preventing employees from accidentally sending confidential data into AI tools...
2.2 The Model Stage
Once a request reaches the model, "internal controls" guide how the model behaves. These controls might limit what resources the model can access or define the role the model should follow inside the application. For instance, a support assistant might be allowed to explain product features but restricted from giving medical, legal, or financial advice..
These constraints reduce the chance that the model drifts into unsafe territory.
2.3 The Response Stage
After the model generates an answer, the system can still evaluate it before sending it back to the user..
Some organizations run moderation classifiers that detect harmful language or policy violations. Others scan outputs for confidential data patterns such as account numbers or internal identifiers.
This output evaluation step is a central component of AI guardrails implementation, because it directly controls what the end user receives.
2.4 The Observation Stage
And then there’s the part most users never see: monitoring.
Every prompt, response, and policy trigger can be logged and analyzed. Over time, those logs reveal patterns. Maybe certain "prompts consistently attempt" to bypass restrictions. Maybe a particular application generates unusually high error rates.
Signals like these support AI threat detection, helping security teams respond before a small issue grows into a larger incident.
When organizations combine prompt inspection, behavioral controls, response evaluation, and monitoring, AI guardrails implementation becomes a practical system rather than a single tool. That layered approach is what ultimately helps maintain AI trust and safety as AI applications expand across enterprise environments.
3. AI Guardrails Implementation Architecture
Knowing that guardrails are necessary is one thing. Figuring out how to actually build them inside an enterprise AI system is another story.
There’s no single switch you flip to “enable guardrails.” In most organizations the solution ends up looking more like an ecosystem of controls placed around the model. Some run before the model receives a prompt, others examine the output, and a few quietly monitor everything happening in the background.
If you opened the architecture diagram of a mature deployment, you would usually see several layers working together. Not perfectly symmetrical layers — more like overlapping safety nets.
3.1 Watching the Prompt
Every interaction starts with a request. Someone types a prompt, an application sends a query, or an automated workflow calls the model.
Before that request reaches the model, many systems run a quick inspection. The goal is simple: catch suspicious instructions early. Prompt injection attempts often show up here — instructions that try to override the model’s original rules or manipulate its behavior.
Input inspection can also detect when users accidentally paste sensitive information into the prompt. Instead of letting the model process that data, the system can block the request or warn the user.
A surprising number of AI issues disappear when organizations handle this step properly.
3.2 Controlling What the Model Can Reach
Modern AI assistants rarely operate in isolation. They connect to tools.
A model might query a knowledge base, search internal documentation, or call APIs that retrieve live data. Those integrations make AI far more useful — but they also create new risks. If the model can freely access everything, a cleverly written prompt might pull information from places it shouldn’t.
To avoid that scenario, enterprises define strict access boundaries. The model can only retrieve information from approved sources, and only under specific conditions. These limits often align with broader enterprise AI governance rules that control how AI systems interact with company data.
3.3 Checking the Response
Even with input inspection and access controls in place, models sometimes produce responses that cause problems.
Maybe the model generates something inaccurate. Maybe it includes sensitive information. Or maybe it simply produces content that violates company policy.
So before the answer reaches the user, another checkpoint evaluates the output. Systems can scan for policy violations, risky language, or confidential data patterns. If something looks wrong, the response can be blocked or replaced.
This stage is often the most visible part of AI guardrails implementation, because it directly shapes what users see.
3.4 Observing the System
The final layer doesn’t intervene in individual prompts. Instead, it watches the entire environment.
AI applications generate huge volumes of interaction data. Over time, patterns start to appear. Certain prompts may repeatedly trigger blocked responses. Some users may try multiple variations of the same instruction hoping one will bypass the rules.
Monitoring pipelines analyze these patterns and surface unusual activity. This is where AI threat detection becomes valuable. "Security" teams can spot suspicious behavior early instead of discovering problems weeks later.:
When these components work together, AI guardrails implementation becomes less about filtering content, and more about supervising an AI system from multiple angles. That supervision is what ultimately helps organizations maintain consistent AI trust and safety while deploying AI across real products and internal tools.
4. Where AI Guardrails Usually Break Down
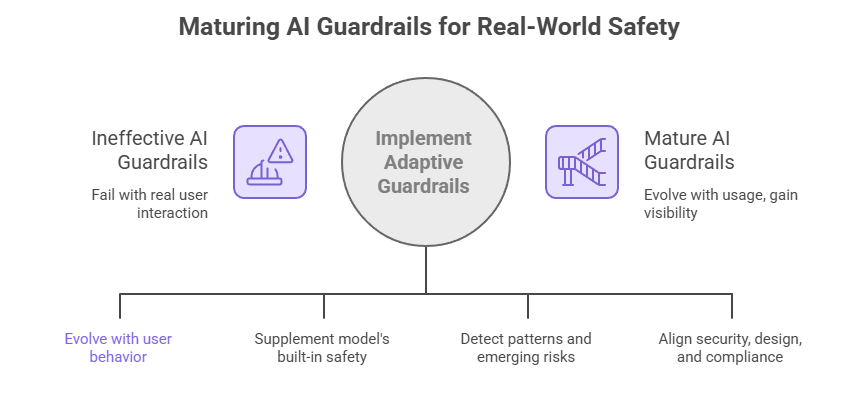
Here’s something many organizations discover only after deployment: adding guardrails doesn’t automatically make an AI system safe. In fact, some companies proudly announce their guardrail framework… and then watch it fail the moment real users start interacting with the system.
Why does that happen?
Because guardrails are often designed in controlled environments. Real users don’t behave the way designers expect.
Let’s look at a few places where things tend to go wrong.
When guardrails rely on rigid rules
Early guardrail systems often depend on simple rule-based filters. For example, block certain phrases, reject certain prompt structures, or stop responses containing specific keywords.
That works for a while.
But users — intentionally or unintentionally — find ways around those rules. Change the wording slightly, hide instructions inside a longer prompt, or ask the same request in multiple steps. Suddenly the filter that looked effective during testing starts missing things.
This is why many security teams now treat guardrails as adaptive systems rather than fixed rule sets.
When companies trust the model too much
Another common mistake: assuming the model’s built-in safety features are enough.
Modern models are trained with alignment techniques to avoid harmful outputs. That’s useful, but it doesn’t solve enterprise risks. A model might still retrieve confidential data from an internal document, summarize something inaccurately, or generate advice that conflicts with company policy.
In other words, model safety is only one layer. Without additional controls around the system, those protections are easy to bypass.
When nobody watches the system after launch
This one happens more often than people admit.
A company deploys an AI tool with some filtering and moderation features. Everything looks good during the first few weeks. Then usage grows. More prompts. More edge cases. More unexpected behavior.
If there’s no monitoring pipeline behind the scenes, these issues quietly accumulate.
That’s where AI threat detection becomes critical. Logs and analytics reveal patterns that individual prompts never show. Maybe users repeatedly try to bypass instructions. Maybe certain prompts always trigger blocked responses. Without visibility, those signals disappear into the noise.
When guardrails become a technical project instead of an organizational one
Guardrails aren’t just a software component.
They sit at the intersection of security, product design, compliance, and infrastructure. When those teams operate independently, guardrails become inconsistent across applications. One system might enforce strict controls, while another barely has any.
This is exactly why many enterprises now treat guardrails as part of enterprise AI governance rather than leaving them entirely to engineering teams.
When organizations address these issues, AI guardrails implementation starts to mature. The system evolves with real usage, security teams gain visibility into emerging risks, and companies maintain stronger AI trust and safety even as AI applications expand across the business.
5. Conclusion
AI systems are spreading through enterprises faster than most governance programs can keep up. Teams deploy copilots, internal assistants, and automated workflows because the productivity gains are obvious. But the moment those systems interact with real data and real users, the risks start appearing.
This is where AI guardrails stop being a theoretical concept and become operational infrastructure.
Guardrails sit around the model and quietly control how it behaves. They limit what information the system can access, examine prompts before they reach the model, and sometimes stop responses before users ever see them. When organizations invest seriously in AI guardrails implementation, the goal isn’t to restrict AI. The goal is to keep the system predictable.
Another reality many companies discover: guardrails only work when they’re tied to policy and oversight. Without alignment with enterprise AI governance, different teams end up building different rules for different AI tools. That fragmentation eventually causes problems.
Strong monitoring also matters. Systems that include continuous logging and AI threat detection give teams visibility into how AI behaves in the real world, not just during testing.
Enterprises that approach AI this way tend to maintain stronger AI trust and safety as their AI ecosystem grows. The models improve, new applications appear, and guardrails evolve along with them.

"AI becomes truly powerful only when it operates within the right guardrails"






Build Safer, Smarter, and Fully Compliant AI With WizSumo

.png)
.png)
.png)



