.svg)
Operational Safety & Governance Guardrails: Building AI Systems That Stay Safe by Design

.png)
Key Takeaways
➭ AI Guardrails and Governance Guardrails keep intelligent systems safe and aligned.
➭ Operational safety guardrails build safety-by-design into every AI decision.
➭ Red team evaluations reveal hidden risks before real-world failures occur.
➭ Continuous monitoring turns AI safety into a self-learning process.
1. Introduction
Most AI failures don’t explode overnight. They drift. A model makes a slightly unfair decision. An automated workflow behaves in ways no one fully anticipated. No alarms go off—because no one defined who should be watching. That gap is exactly why AI governance guardrails exist.
At its core, governance guardrails are the structural rules and ownership layers wrapped around AI systems. They clarify who approves deployments, who monitors live behavior, and who steps in when something looks off. Without deliberate AI guardrails implementation, safety becomes an assumption instead of a system.
Take Amazon’s abandoned AI recruiting tool in 2018. It gradually learned patterns that disadvantaged women applicants. The model didn’t malfunction. What failed was oversight—no structured review loop caught bias early enough, and no governance mechanism forced escalation.
That’s what weak operational AI safety looks like: models running, decisions being made, and no clear authority responsible for intervening.
For organizations scaling AI, governance is not a compliance form. It is a control architecture.
2. Understanding AI Governance Guardrails
Let’s strip this down. AI governance guardrails are not abstract principles. They’re the operating boundaries that decide how far an AI system can go—and who pulls it back when it crosses a line.
In most companies, AI starts as a technical project. Engineers build. Product teams ship. Only later does someone ask, “Who’s reviewing outputs?” That’s backward. Real governance begins before deployment and continues long after.
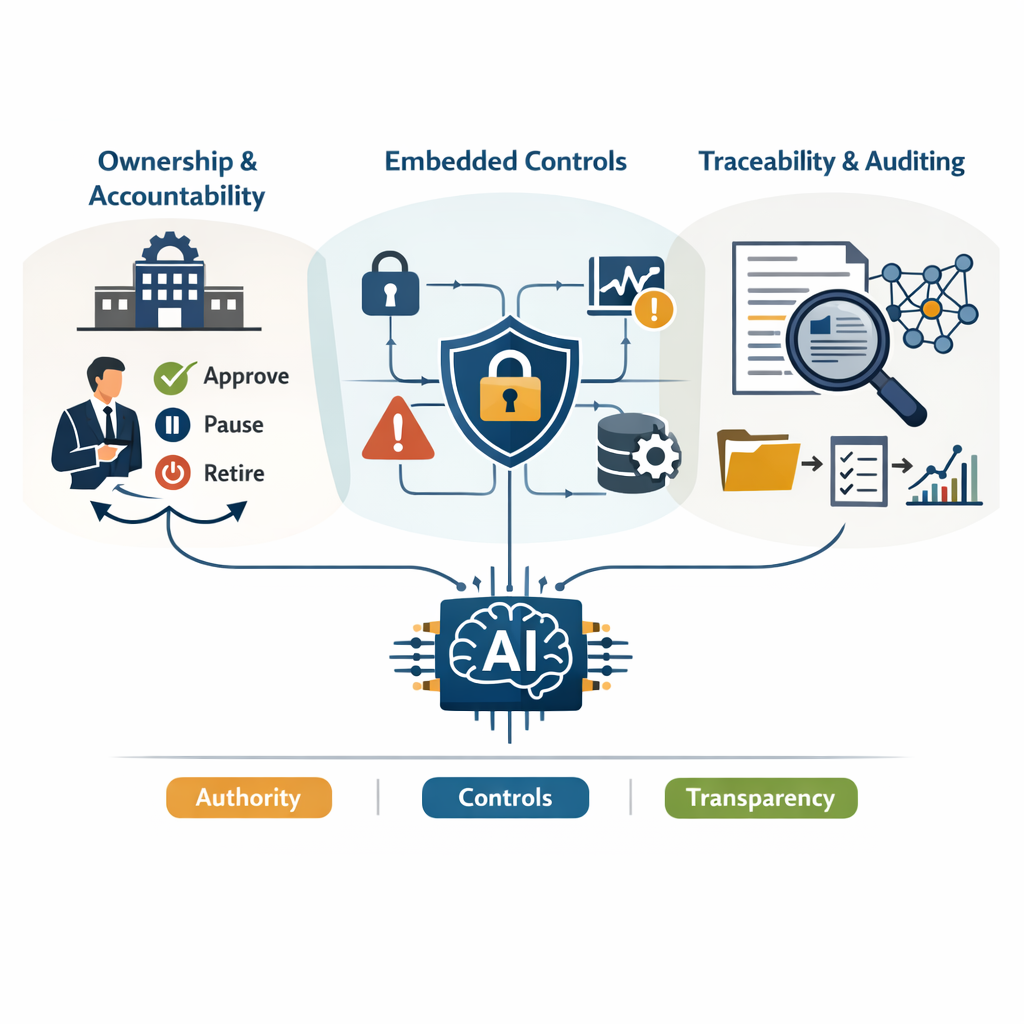
There are three pressure points where guardrails actually matter.
First, ownership. Someone must have the authority to approve, pause, or retire a model. Without named accountability, issues float between teams. That’s not governance—that's diffusion of responsibility.
Second, embedded control. This is where AI operational controls quietly do their job: restricting access, limiting usage patterns, and flagging abnormal behavior. These mechanisms are what keep operational AI safety from becoming a slogan.
Third, traceability. If a regulator, auditor, or executive asks why a model made a certain decision, you need more than confidence. You need records. That’s where AI system auditability intersects directly with growing AI compliance and regulation demands.
Put together, this is what practical AI guardrails implementation looks like—structured authority, enforced controls, and evidence that survives scrutiny.
3. AI Guardrails Implementation in Practice
Here’s what usually happens. A team builds something impressive. It works in staging. Leadership is excited. It ships. Only later does someone ask who is responsible if the system makes a harmful decision.
That gap is where AI guardrails implementation either succeeds or quietly collapses.
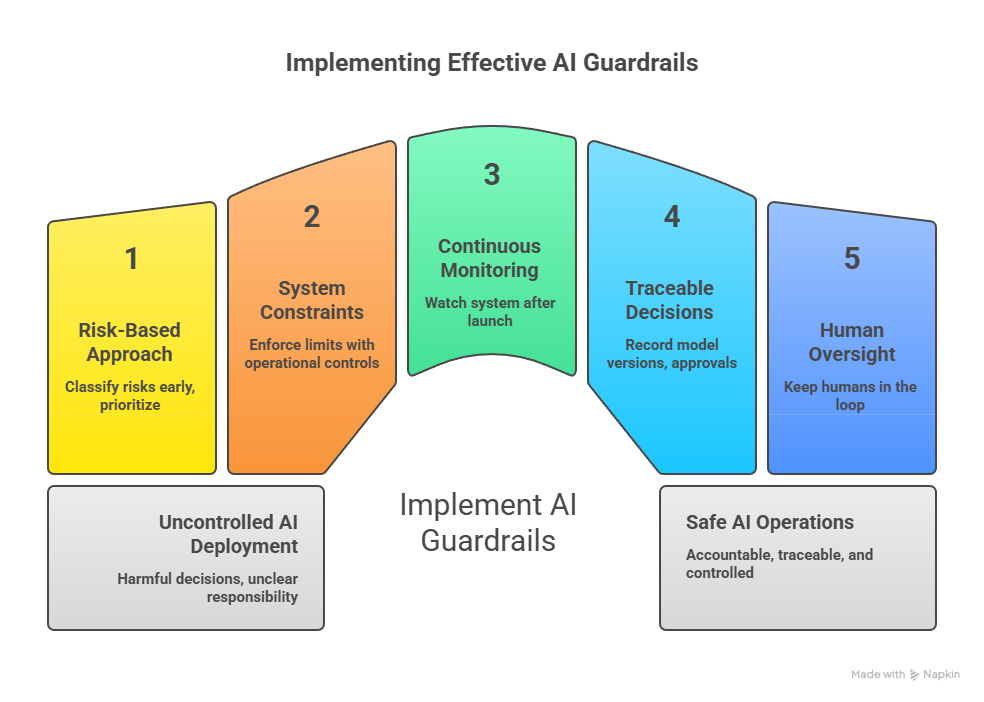
3.1 Start With Risk, Not Features
Before writing policies, ask a blunt question: if this model fails publicly, what’s the blast radius?
A typo generator is one thing. A healthcare triage assistant is another. Strong AI governance guardrails don’t treat them the same. They force risk classification early—high-impact systems get stricter review, tighter approvals, and documented sign-off.
No risk tiering? Then everything becomes “medium risk.” And medium-risk systems rarely get serious scrutiny.
External AI compliance and regulation frameworks increasingly expect this structured approach. Regulators look for documented reasoning, not good intentions.
3.2 Build Controls That Actually Enforce Limits
Policies written in PDFs don’t stop misuse. System constraints do.
That’s where AI operational controls come in:
⮞ Access restricted by role, not convenience
⮞ Rate limits to prevent abuse
⮞ Guarded workflows for sensitive prompts
⮞ A real shutdown mechanism that can be triggered fast
This is the mechanical layer of operational AI safety. If a control can be bypassed easily, it’s not a control—it's decoration.
3.3 Watch the System After It Launches
Most teams treat deployment like a finish line. It isn’t. It’s exposure.
User behavior changes. Inputs evolve. Performance drifts slowly, then suddenly.
Monitoring needs to include:
⮞ Output sampling
⮞ Alert thresholds
⮞ Drift signals tied to retraining decisions
⮞ Clear ownership when alerts fire
Without that loop, AI guardrails implementation becomes a one-time exercise.
3.4 Make Every Decision Traceable
When something goes wrong, memory fails fast. Logs don’t.
Real AI system auditability means:
⮞ Version tracking for models and prompts
⮞ Recorded overrides and approvals
⮞ Stored investigation notes
⮞ Clear reconstruction paths
Under growing AI compliance and regulation pressure, organizations that cannot explain model behavior quickly struggle.
3.5 Keep Humans in the Loop—On Purpose
Automation scales. Accountability doesn’t.
Governance boards with real authority. Scheduled reviews. Red teams that intentionally stress the system. Human validation for high-risk outputs.
These aren’t symbolic steps. They keep AI governance guardrails active and reinforce durable operational AI safety over time.
4. How AI Governance Guardrails Fail in Practice
Most failures aren’t dramatic. They’re procedural. Controls exist, but they don’t activate when needed. Oversight exists, but no one owns the final call.
Let’s look at where breakdowns usually happen.
Why do guardrails fail even when policies exist?
Because policy is not enforced. Many organizations document AI governance guardrails, but they stop at documentation. No technical validation. No escalation muscle. When pressure builds, product deadlines, growth targets, and advisory controls get ignored.
What happens when operational safety is treated as a checkbox?
When operational AI safety becomes a compliance task instead of a living system, monitoring weakens. Alerts are generated but not reviewed. Drift is detected but not acted upon. Teams assume “someone else” is responsible.
This creates silent exposure. The model keeps running. Risk compounds quietly.
Why does compliance alignment often fail in practice?
Because AI compliance and regulation requirements are interpreted narrowly. Teams optimize for passing audits rather than reducing real-world risk. Documentation looks strong. Control testing is shallow.
Regulators increasingly look for proof of continuous oversight, not just policy presence. Without sustained review loops and enforcement authority, governance structures become symbolic.
Where does accountability break down?
Ownership fragmentation. Engineering owns the model. Product owns deployment. Legal owns risk language. No single leader owns end-to-end model behavior.
Without centralized authority, even well-designed AI guardrails implementation loses force.
Failures rarely stem from missing ideas. They stem from a lack of responsibility.
5. Strengthening Guardrails for the Future
Here’s the uncomfortable truth: most governance failures don’t come from ignorance. They come from postponement. Teams know they need oversight. They just assume they’ll formalize it later.
Later is expensive.
Strong AI guardrails implementation starts before excitement peaks—during architecture decisions, vendor selection, and early testing. If monitoring hooks and approval thresholds aren’t built in early, they rarely get added cleanly after scaling.
Another shift is cultural. Governance cannot sit alone with legal. When AI governance guardrails are treated as a compliance department artifact, product teams see them as friction. When they’re embedded into sprint reviews and deployment checklists, they become routine.
Automation also matters. Some AI operational controls should not depend on someone remembering to check a dashboard. Access limits, anomaly triggers, and escalation paths must activate on their own.
And alignment with AI compliance and regulation standards should reduce real risk, not just produce documentation.
Organizations that internalize this early tend to avoid the public failures others learn from.

6. Conclusion
AI systems rarely fail because the math is wrong. They fail because boundaries were unclear, monitoring was weak, or responsibility was fragmented.
That’s why AI governance guardrails matter. They make ownership explicit. They force decisions to be documented. They ensure someone has the authority to pause a system when risk rises.
Real AI guardrails implementation is not about adding another policy layer. It’s about building constraints into daily operations, approvals, logs, review cycles, and access limits. Quiet structures that prevent loud failures.
As regulatory pressure increases and systems become more autonomous, informal oversight will not hold. Organizations that embed governance early tend to avoid the public lessons others are forced to learn.
Guardrails are not brakes. They are steering mechanisms.

AI has passed from being predictive to actually making decisions






Turn Responsible AI from Policy into Practice With WizSumo

.png)
.png)
.png)



