.svg)
Reinforcement Learning Explained (2025): From Beginner Basics to Future AI Breakthroughs


Key Takeaways
Reinforcement Learning teaches AI through rewards and feedback.
Key algorithms like Q-Learning and Policy Gradients power modern AI systems.
Deep RL drives robotics, gaming, and real-world automation.
RLHF and multi-agent learning are shaping the future of AI.
Python libraries make starting with RL simple for beginners.
1. Introduction: Reinforcement Learning Explained
Let's take a trip in the past, do you remember learning to ride a bicycle? You probably crashed quite a lot at first. And every little win like staying upright a little longer was a massive win. Each crash was feedback that led to adjustment the next time. Over the course of a few months of repetition you finally mastered riding a bicycle.
That’s essentially Reinforcement Learning explained in everyday life: learning by doing, guided by rewards and feedback. Reinforcement Learning (RL) in AI is the areas of ML that lets the system start to make decisions, learn and adjust its environment, and self-improve based on the performance (not necessarily instruction about what to do next).
Today, most AI products and tools to date have graduated from research to engines controlling robots that teach themselves, AI agents that beat world champions in games, and recommendation systems to predict what will be chosen in real time. From the basics of how AI learns from rewards to cutting-edge approaches like Reinforcement Learning from Human Feedback (RLHF), this field is driving some of the most exciting breakthroughs in technology today.
This blog will guide you through:
⟶ The basic concepts – basic approaches to lay the foundation for RL for beginners.
⟶ Core algorithms and advanced methods - everything from Q learning to policy gradients and what can happen after that.
⟶ Real world use - how RL operates in games, robotics, and business.
⟶ Problems and boundaries - the real problems researchers and developers need to solve.
The future of reinforcement learning – emerging trends and opportunities in 2025 and beyond.
Whether you’re just curious, beginning your AI journey, or already experimenting with advanced methods, you’ll come away with a clear understanding of why RL matters more than ever in 2025.
2. What is Reinforcement Learning?
Reinforcement learning (RL), ultimately, is the machine teaching itself through experience – just as humans and animals do. Unlike supervised learning, where the machine work is told what to do, an RL agent will learn what the optimal action or an optimal policy is by interacting with its environment, receiving a reward for action taken that is beneficial, and incurring a penalty for an action taken that is harmful.
This makes RL a powerful approach to how AI learns from rewards, trial, and error. By repeatedly adapting its approach, an RL agent can enhance its performance across tasks – balancing a cart, playing a game of chess, manipulating a robotic arm.

2.1 Reinforcement Learning Explained: Core Definition & Concept
The simplest working definition for reinforcement learning would be:
“A machine learning method where an agent learns the appropriate action to take in an environment, by receiving rewards and penalties”.
Reinforcement learning stands apart from other types of machine learning, as it doesn’t rely on big data sets but instead an interaction through feedback loops. The agent does not memorize patterns – the agent learns by doing.
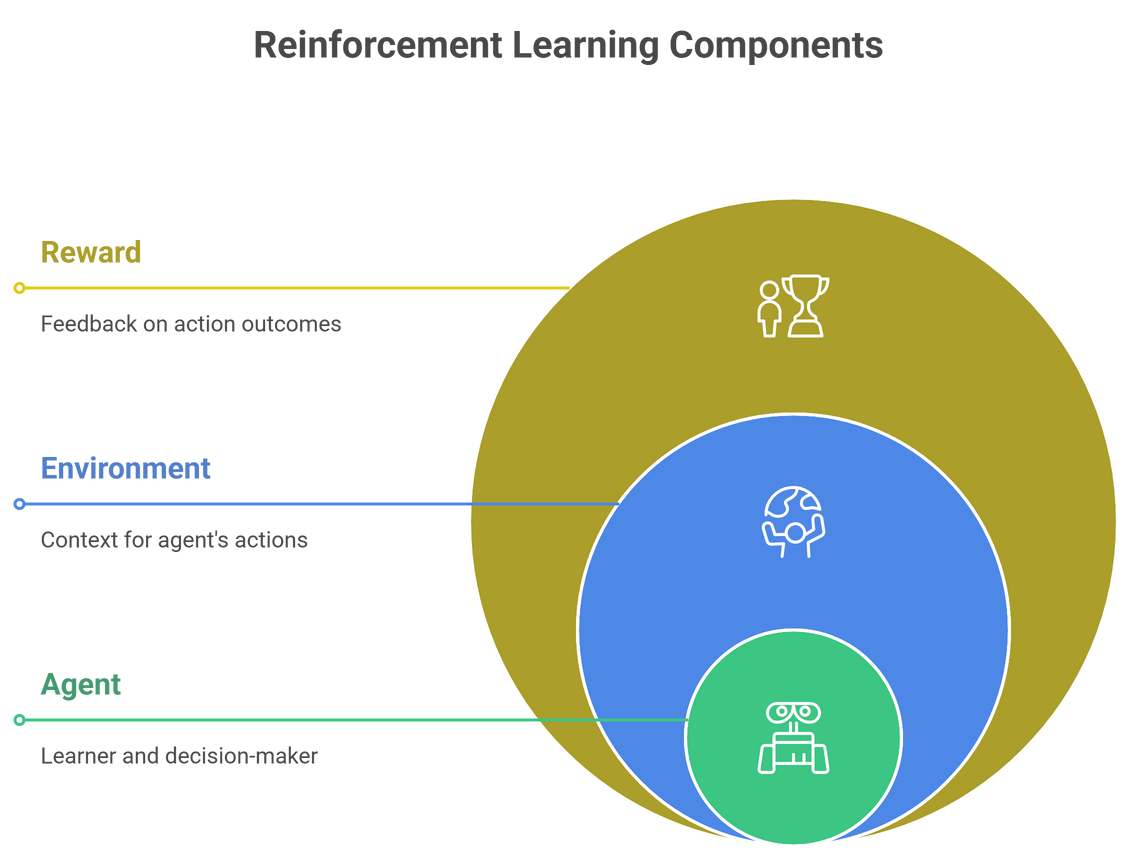
2.2 Key Components of RL (Agent, Environment, Rewards)
To appreciate reinforcement learning, one needs to understand the three elements of the learning process:
Agent – The learner or decision maker (ex: a robot or software program).
Environment – Everything the agent interacts with (ex: a game environment, a physical environment, or a user’s behavior).
Reward – The signal of feedback to the agent: good (+), or bad (–), where the action was taken.
Every RL process is based around the agent and environment – interaction loops.
- The agent takes action.
- The environment returns with a new state and a reward.
- The agent updates it policy to improve it’s next actions.
This simple loop forms the foundation for even the most advanced RL algorithms.
2.3 Why Reinforcement Learning is Revolutionary for AI
What distinguishes RL so distinctly from other forms of machine learning?
⟶ It enables autonomous decision makers. For supervised learning, you have labeled data beforehand, for RL the AI learns by trial and error.
⟶ It is adaptable to changing environments. RL can be non-stationary, and the RL changes as the environment changes. In other words, it is a moving target.
⟶ It incorporates perception and action. RL gives a way for the AI to not only “see” or “predict” – it enables action with the world.
⟶ It has real-world achievements. RL moves beyond AlphaGo defeating world champions to self-learning robots with more advancements than any others.
In short, reinforcement learning is not just another machine learning technique—it’s a paradigm shift in how AI learns from rewards and experience.
3. Reinforcement Learning for Beginners
If you’re new to the concept, think of reinforcement learning for beginners as teaching pet tricks. Every time a pet does something good, we give it reward. Over time the pet learns what behaviours lead to the reward and keeps doing those. Reinforcement learning (RL) is the same way - the “pet” is a computer program, and the “reward” is a number.
3.1 Understanding Rewards and Feedback Loops
At the core of everything, RL is all about learning from feedback. The agent (AI) does something, receives feedback (reward or penalty), and adjusts. This hopping back and forth continues until the agent gets better and better at its goal.
Positive rewards motivate useful behaviour.
Negative rewards (penalties) motivate the agent’s avoid bad behaviours.
The feedback loop = repeated attempts, feedback, and improving.
This is essentially how AI learns from rewards—not from a fixed dataset, but from experience.
3.2 Exploration vs Exploitation in How AI Learns from Rewards
One of the most difficult parts about RL is how to balance:
Exploration - trying new actions in order to learn better ones (e.g. different moves in a game).
Exploitation - using what the agents already knows works well to maximize reward.
For example, you’re at your favorite restaurant. Do you keep ordering your favorite dish you know you love (exploitation) or do you sometimes try something new that might be better (exploration)? RL agents do this too.
The balance between the two is really important - too much exploration would be a waste, while too much exploitation could miss out on uncovering better alternatives.
3.3 Simple Example: Learning to Play a Game with RL
To give you a simple example to clarify:
🎮 Tic Tac Toe (or a small maze game):
- The RL agent has no understanding of how to win.
- They will start making random moves (exploration).
- Each time they win they receive a reward (let’s say +1 point). Each time they lose they get a penalty (let’s say -1 point).
- After many games they learn how to make moves that improve the likelihood they win.
- Eventually they have a strategy that exploits for maximum amount of wins.
This overall simple process is the basis of even very advanced RL systems such as controlling robots, optimizing supply chain management, and self-driving cars.
4. Key RL Algorithms Explained
Reinforcement learning consists of many different algorithms. Some algorithms focus on: learn from rewards, update policy, and improve decision-making over time. Here is a brief overview of the most important ones you need to know.
4.1 Q-Learning Algorithm (Step-by-Step)
Q-Learning is one of the most known algorithms in reinforcement learning and this algorithm learns the value (Q-value) of the action taken in the states.
Instead, you can think of Q-Learning, as an agent keeping score about which actions are working and which are not. Moving forward, it will update the scorecard and select actions accordingly.
👉 How it works (high-level):
⟶ The agent explores by taking random actions.
⟶ The agent records the reward of action.
⟶ Agent updates Q-table (memory) based on received information.
⟶ Repeat process and update action for value (maximizing expected reward) for all states and actions.
Q-learning has been used to teach agents go from navigation through mazes, and playing video games without a teacher.
4.2 SARSA (State-Action-Reward-State-Action) Explained
SARSA is very similar to Q-Learning apart from the important difference that SARSA updates value based on action taken next by the agent rather than the optimal action taken from the state.
Q-Learning → “What is the best possible move here?” (optimistic)
SARSA → “What move did I actually take and how did I do?” (not optimistic now but realistic better)
This makes SARSA more conservative but is extremely useful if the environment is changing in an unpredictable manner.
4.3 Deep Reinforcement Learning (Combining Neural Networks + RL)
When RL meets deep learning, we get Deep Reinforcement Learning. Instead of using a simple Q-table, neural networks are used to approximate the value of actions in complex environments.
Its discovery fundamentally shifted the whole trajectory of AI based off the need for complicated interactions, timeframes and stochasticity. Without SARSA, there is no DeepMind AlphaGo beating 3 world champions at Go, a game that is compositionally too complicated for extremely complicated implementation of standard algorithms.
Deep RL is particularly useful when there are too many states to represent with a simple Q-table (e.g., self-driving car) or cases where agents must store raw data(e.g., Images, audio, or sensor input).
4.4 Policy Gradient Methods in Reinforcement Learning
Unlike Q-Learning and SARSA which primarily learns the values, Policy Gradient methods directly learn the policy- the mapping from states to actions. Instead of asking “How good is this action”), Policy Gradient Methods ask “What is the best action to take right now”
This is particularly useful for continuous action spaces e.g. stick, control of an robotic arm, with incredible many possible moves from any position in continuously.
Most advanced robotics and continuous control systems we use in AI, use Policy Gradient methods.
5. Reinforcement Learning in Practice: Real-World Applications
While reinforcement learning may be a formal classification, it is prevalent in non-technical or everyday life, be it in gaming, a well-functioning robot arm, or a business flexibility domain, RL is built into technology that surrounds our daily lives.
5.1 Gaming Applications Powered by RL Algorithms
Video games are one of the best environments for RL agents pushing themselves. Simple process, known reward, continuation of learning in indefinite state space.
⟶ DeepMind created headlines when in AlphaGo, they conquered world champions in Go using a combination of RL and Deep Neural Networks.
⟶ Video game AI, today is derived from RL algorithms. The interesting thing is that now the opponent can be smarter, adaptive, and much more accurate in learning from what the player did.
⟶ By 2025, RL applications will provide dynamic game scenarios (level), which will alter the average level of game difficulty based on the skill level of the player.

Gaming was one of the first places where RL truly proved its power, and it continues to evolve the way AI interacts with human creativity.
5.2 Robotics and Automation with Deep Reinforcement Learning
In robotics, Deep Reinforcement Learning has enabled machines to move beyond rigid programming. Robots learn through trial & error while being held to a define state-space -- these types of Robots are learning to walk, balance and even pick up delicate objects. Adaptiveness of robots is imperative within real-world businesses which have robots in industries like domino warehouses, hospitals, and factories where the garbage can be optimized through “evolving.” By 2025, RL robots will automate manufacturing, optimize logistics, and provide delicate care in healthcare.
5.3 Recommendation Systems and Business Solutions
If you’ve ever wondered how Netflix predicts what movie you may want to watch next after your 20th movie after joining, or how Amazon, based on none of the options providing products they think you didn’t know you wanted, was the result of reinforcement learning and recommendations. Note how the recommendation meets works in real time until the final decision. This is the same on the entertainment side or businesses side where businesses are using RL for optimizing the supply chain, reducing costs, and targeting consumer demand. In finance RL agents will optimize trading strategies in dynamic markets -- seeking out optimal options to take, just like in a transaction both in the right and wrong way.
6. Reinforcement Learning vs Supervised Learning and Other ML Types
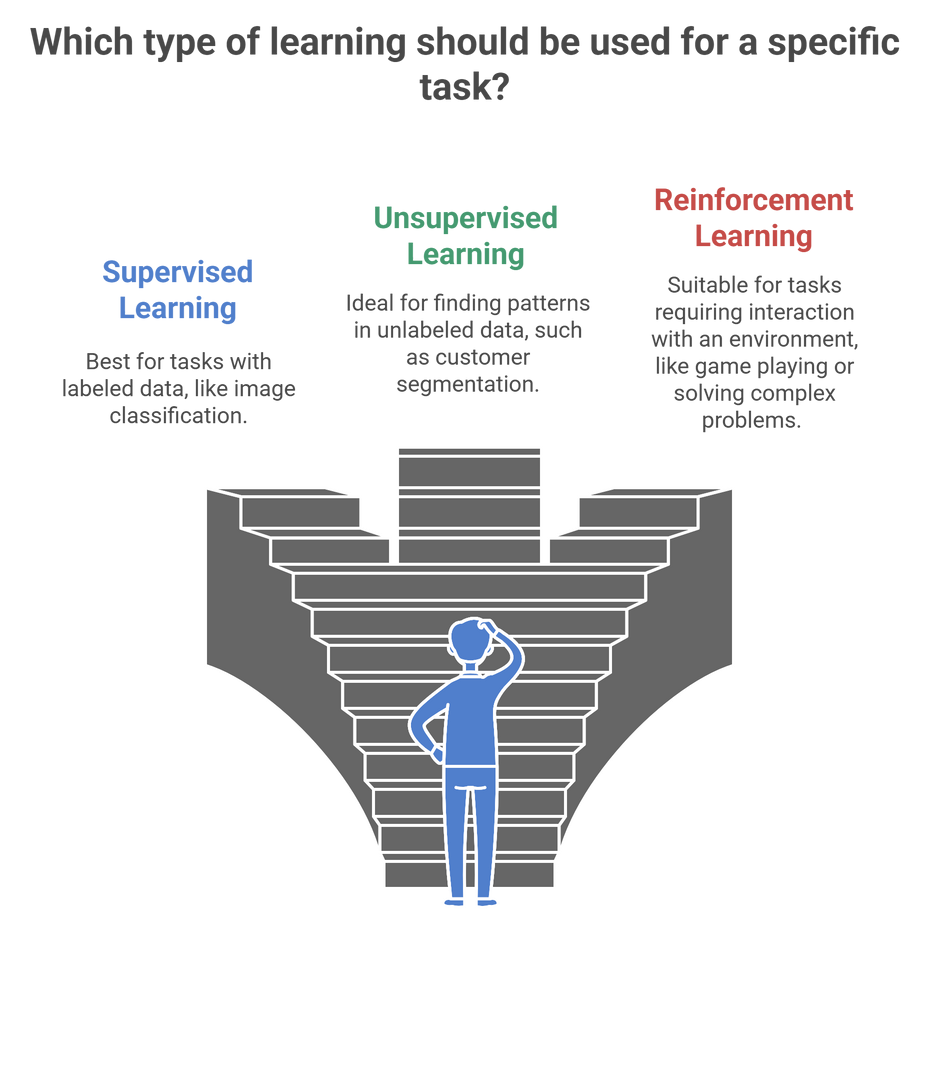
Reinforcement learning is often seen as just another type of machine learning, but actually is based on completely different principles. To see the difference, it is helpful to compare RL against supervised and unsupervised learning—the two other main `types’ of AI.
6.1 Supervised vs Unsupervised vs Reinforcement Learning
Supervised learning is all about learning from labeled data (a.k.a. training with human feedback). For example, if you have a model that is trained on thousands of labeled images of cats and dogs, it will learn to tell which new images are cats/dogs correctly. It’s like a student who has the answer key to a test.
Unsupervised learning is about learning from unlabeled data (a.k.a. discovering hidden structures/patterns). The model learns to cluster customers based on purchasing behavior—without needing category labels. This is like a student given a pile of unorganized notes, and asked to organize it into sections independently of being told how to.
Reinforcement Learning makes learning fundamentally different. Instead of learning from a labeled answer, or discovering a pattern, RL learns from the responses (feedback) that aims to lead to a positive outcome. Essentially, RL is to learn a sport, as studying an answer key. You do not learn how to use your body and do the action, you learn how to play, learn to play by playing while making mistakes and figuring out how to improve.
6.2 When Reinforcement Learning is the Right Choice
Reinforcement learning is not the approach for every problem. Where RL works the best are where the:
⟶ Decision-making is sequential, influencing future decisions and outcomes (e.g., robotics, trading).
⟶ The environment provides evaluative feedback signals (win/loss signal, points, or measurable indicator of performance).
⟶ Flexibility and adaptability requirements (e.g., the learned system must learn while the environment evolves).
In these cases, if you have a cleansed and labeled dataset, then supervised learning is statistically more appropriate. If the purpose is purely exploratory understanding of structures/patterns, unsupervised learning may be most appropriate.
In summary, reinforcement learning is not an appropriate approach 100 percent of the time, it can provide unique outcomes that no other approaches can deliver when it is right.
7. Challenges and Limitations of RL
Although reinforcement learning has received tremendous focus, it is imperfect. As with anything, researchers and developers face challenges with scaling RL, which is just as important to understand as the potential it has going forward.
7.1 Reward Design and Shaping Issues
One of the most difficult parts of RL is developing the right reward method. If the rewards are too simplistic, the agent will simply learn unintended shortcuts. For example, in a game environment, an agent might learn to just collect points indefinitely rather than actually complete the level.
The problem of reward hacking illustrates the worst case scenario of how an RL agent will exploit any poorly stated objective. Therefore, it’s hard to create rewards in RL that are both meaningful, balanced, and in line with human goals.
7.2 Exploration Challenges in RL Algorithms
Exploration - trying new actions to find a better strategy - is vital in reinforcement learning. However, it has tradeoffs. If your agent explores too much, it is wasting your time, and effort. If it doesn’t explore enough, it could get stuck repeating non-optimal actions.
Eventually the trade off of exploration is very difficult here. Pretend we are training a robot to walk. The robot likely would need thousands of failed attempts before it made any meaningful headway, which if we’re in the real world can be priceless.
7.3 Scalability and Computational Costs
A critical problem with reinforcement learning is usually the requirement of extreme amounts of data and computation. AlphaGo, like other more complicated deep RL, needed to be trained on a super computer with all of those simulations running at once.
For smaller organizations or individuals, such requirements can make RL impractical. Even with recent advances in Deep Reinforcement Learning, scaling up remains one of the biggest barriers to widespread adoption.
8. Advanced Topics: Deep & Multi-Agent Reinforcement Learning in 2025
Reinforcement learning has already engaged in its implementations in controlled environments within RL, but researchers want to advance RL to much more engaging human-RL, multi-agent systems which are new frontiers for RL in 2025.
8.1 Reinforcement Learning from Human Feedback (RLHF)
The area that is the most engaged and probably the most exciting milestone is Reinforcement Learning with Human Feedback (RLHF). RLHF depends on human feedback in place of giving some metric reward signal to help the agent learn because it brings an external structure to the agent’s learning.
This milestone has been significant for AI alignment with human values. Just think about how playing with word vectors and large language models dubbed (e.g. ChatGPT) are based heavily on RLHF the humans in RLHF will leverage the human value of the response.
By 2025, RLHF is expanding beyond language models into robotics, healthcare, and education - allowing the agent to align for human consistency, safety and shape how it governs its decision.
8.2 Multi-Agent Reinforcement Learning (Cooperative & Competitive AI)
The world does not typically consist of a single learning agent learning in a single mode, but enables multi-agent reinforcement learning (MARL) to explore agents who learned in the same environment, whether it is shared, competing, or cooperating toward objectives.
⟶ In competing environments (like self-driving vehicles through traffic), each agent is required to learn to compete and win against one another, and establish rules to control the environment.
⟶ In cooperating environments (like delivery drones), the agent's goal is to increment the group reward.
As one of the hottest topics in RL by 2025, MARL is being adopted in many contexts such as autonomous transportation systems and digital marketplaces. MARL reflects how we interact as humans - and typically do not learn - alone.
8.3 Hierarchical and Meta-Reinforcement Learning
Another promising subarea is hierarchical reinforcement learning, with the agent tasked with a single task and converts it into subtasks, so instead of markup learning a lengthier, multi-faceted task, they agent learns “skills” that are subsequently leveraged together to complete a longer, multi-faceted task. The robot learns first to obtain the object with the gripper, then learns the skill of stacking and finally learns the multi-faceted task of assembling.
Very similarly, is meta-reinforcement learning, which is simplistic connected to “learning to learn,” where the planner quickly and efficiently learns new tasks quicker because it learned multiple policies based on prior experience.
Starting in 2025 hierarchical and meta- RL are advancing the limitations of general-purpose AI systems through multi-domain transfer learning.
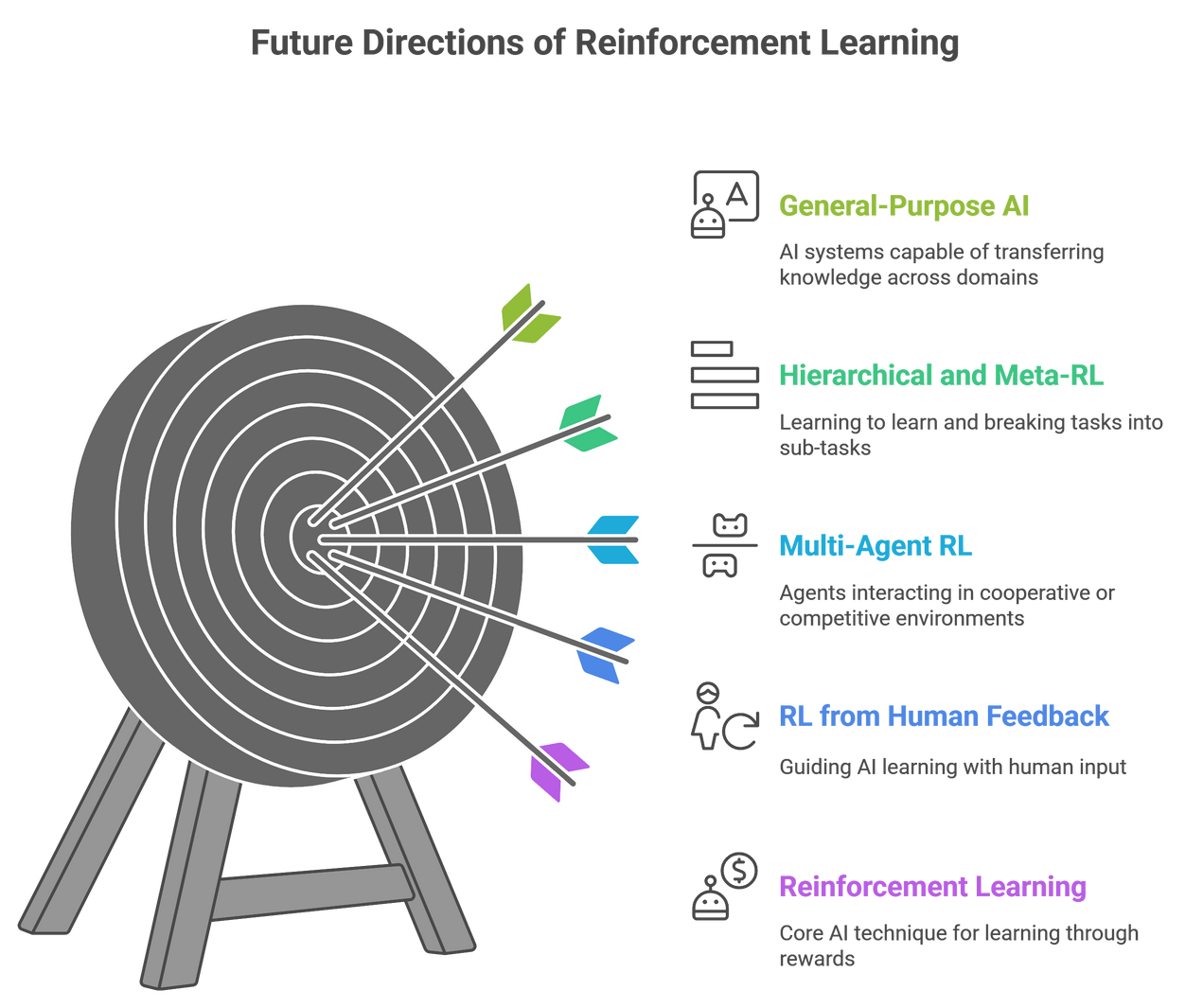
Reinforcement learning is not just about the tools with a single agent in a game- but it is more. It becomes multi-agent ecosystems, human-centric system designs, and meta-learners generalized across used tasks. These are the new frontiers to embrace the future of RL research and represent a new world of possibilities for intelligent systems in 2025.
9. Tools, Frameworks, and Resources for Reinforcement Learning with Python
Understanding how to apply RL in practice versus in theory can be fundamentally different. Fortunately, what will progress into 2025, there will be a great deal of frameworks, and Python tools, making it even easier to get going with an RL project. Resources are equally suitable for novices and expert researchers alike because they are designed to allow users to create their environments, agents, and algorithms without re-implementing the same principles from scratch.
9.1 OpenAI Gym and New Environments (2025 Updates)
For years, OpenAI Gym has been the standard for practicing RL. It provides a variety of simulated environments– everything from grid worlds to real-life Atari games – to compare algorithms in controlled environments.

By 2025, Gym will have been a part of the ecosystem with items like Gymnasium and PettingZoo – specifically for multi-agent environments. These platforms will create a new horizon of research, moving beyond single-agents and into more real-world cooperative and competitive simulations.
9.2 RL Libraries: TensorFlow Agents, PyTorch RL, Stable-Baselines
Once you have an environment, you need tools to build and train your agents. The most popular reinforcement learning with Python libraries today include:
⟶ TensorFlow Agents (TF-Agents): Flexible packages for building RL pipelines through TensorFlow.
⟶ MongoDB Model Zoo (Model Zoo): Gives architecture and frameworks for RL. Commonly utilized in research due to the popularity of PyTorch.
⟶ Stable-Baselines3: Practical implementations of Classic RL implementations. Implements common RL algorithms like PPO, DQN, and A2C. Great beginner resources.
These libraries will mostly remove the heavy lifting so, that you can focus on experimenting with ideas without initially going without a properly coded version.
9.3 Best Tutorials, Courses, and Online Resources
You don't need to wait until you have years of experience in research to get started - more and more of these routes exist online. There are beginner to advanced RL course offerings Systems like Coursera, Udemy, and DeepLearning.AI. There are also open source tutorials and GitHub projects with specific code examples for you to try out live coding today. Louise[8:52PM]
By 2025, community based platforms such as Hugging Face Hub are making it easy to share well-validated pre-trained RL models and benchmarks. This will give beginning learners the experience of making mistakes on their own terms without being overwhelmed on theory.
Reinforcement learning will feel a bit like a barrier to entry, but with these tools, and libraries, all are encouraged to experiment. If you can do basic programming in Python, you have enough knowledge to successfully launch your initial RL project.
10. The Future of Reinforcement Learning (2025 and Beyond)
Reinforcement learning has already reshaped gaming and robotics, but it may hold even more potential in the future. With the increasing computational power and scalability of efficient algorithms, RL will be at the center of the next AI explosion.
10.1 Emerging Trends in RL Algorithms
The biggest jump in RL is in deep learning, human oversight, and multi-agent systems. Three standout trends are apparent in 2025...
⟶ Scalable RL: The development of better algorithms is enabling the training of complex agents with non-super computer computational power.
⟶ RL with human supervision: The use of techniques for RLHF are providing stronger alignment of AI systems to human desires and interests.
⟶ Cross-domain generalization: Meta-learning approaches allow RL agents to learn to apply knowledge learned on one task to a different task, which has historically been difficult.
These trends are bringing RL closer to general intelligence in that agents will be able to make flexible transitions across tasks.
10.2 Opportunities and Potential Impacts Across Industries
In the next decade, we could see RL powered autonomous vehicles safely negotiating traffic to AI-driven healthcare assistants recommending the next best treatments in real-time. RL could even revolutionize the business of supply chain, personal services, and risk forecasting.
Even in the arts, RL is beginning to power music, virtual world design and personalized learning in education. The adaptability and learning nature of RL agents can be utilized to continuously learn in a fast-paced information changing space, where decisions must be made in adaptive time.
10.3 Preparing to Experiment with Reinforcement Learning
For students, developers, or businesses, we have the best chance of success if we try something today. With cloud training specific to Python libraries, and open-source environments more accessible than ever before, you don’t need a lab to get started.
Small projects training an agent to play a game or using search-based RL to recommend the next move are great entry projects, and overtime these small projects could flower into important contributions to robotics, AI safety, or industries.
The future of RL is not only driven by who implements it, but who invests time and exploration that surrounds it.
11. Conclusion
Reinforcement learning is developing quickly from simple reward-based entities to powerful algorithms shaping robotics, gaming, business, etc. What makes it special is that it learns through action, similar to a human learning through trial and error.
As we’ve seen, RL is not only a powerful research field but also a practical tool that is transforming industries in 2025. From how AI learns from rewards to advanced methods like multi-agent reinforcement learning and RLHF, the journey of RL is just beginning.
If you are concerned about the introduction of artificial intelligence, there has never been a better time than now. Python libraries, tutorials, and open-sourced environments are available at your fingertips. You don’t need to get a PhD, nor do you need a massive research lab to start with RL.
Reinforcement Learning thrives on one truth: machines learn best by doing






Start Your Reinforcement Learning Journey Today with WizSumo

.png)
.png)
.png)



