.svg)
When AI Breaks Bad: The Rise of AI misuse and the AI guardrails That Can Save Us

.png)
Key Takeaways
1. Introduction
AI systems are no longer experimental tools. They write code, answer customers, generate reports, and power decision systems. But as adoption expands, so does AI misuse — deliberate manipulation, adversarial prompting, jailbreak attempts, and system abuse designed to push models beyond intended limits.
In 2016, Microsoft launched Tay, an AI chatbot on Twitter. Within hours, coordinated users manipulated the system through adversarial inputs, forcing it to generate offensive and harmful content. Microsoft shut it down in less than 24 hours. The failure wasn’t about intelligence. It was about boundaries.
That incident became one of the earliest public demonstrations of what happens when AI guardrails are weak or insufficient. Without strong input controls, output moderation, and system monitoring, models can be steered in directions their creators never intended.
Today’s generative systems are far more powerful than Tay ever was. And the risks scale with capability.
AI guardrails and AI safety guardrails are the structured constraints that prevent manipulation, reduce system abuse, and protect against cascading failures. Without them, AI doesn’t just make mistakes — it becomes exploitable.
The question isn’t whether AI can be misused. It already is.
The real question is whether safeguards are built before misuse becomes systemic.
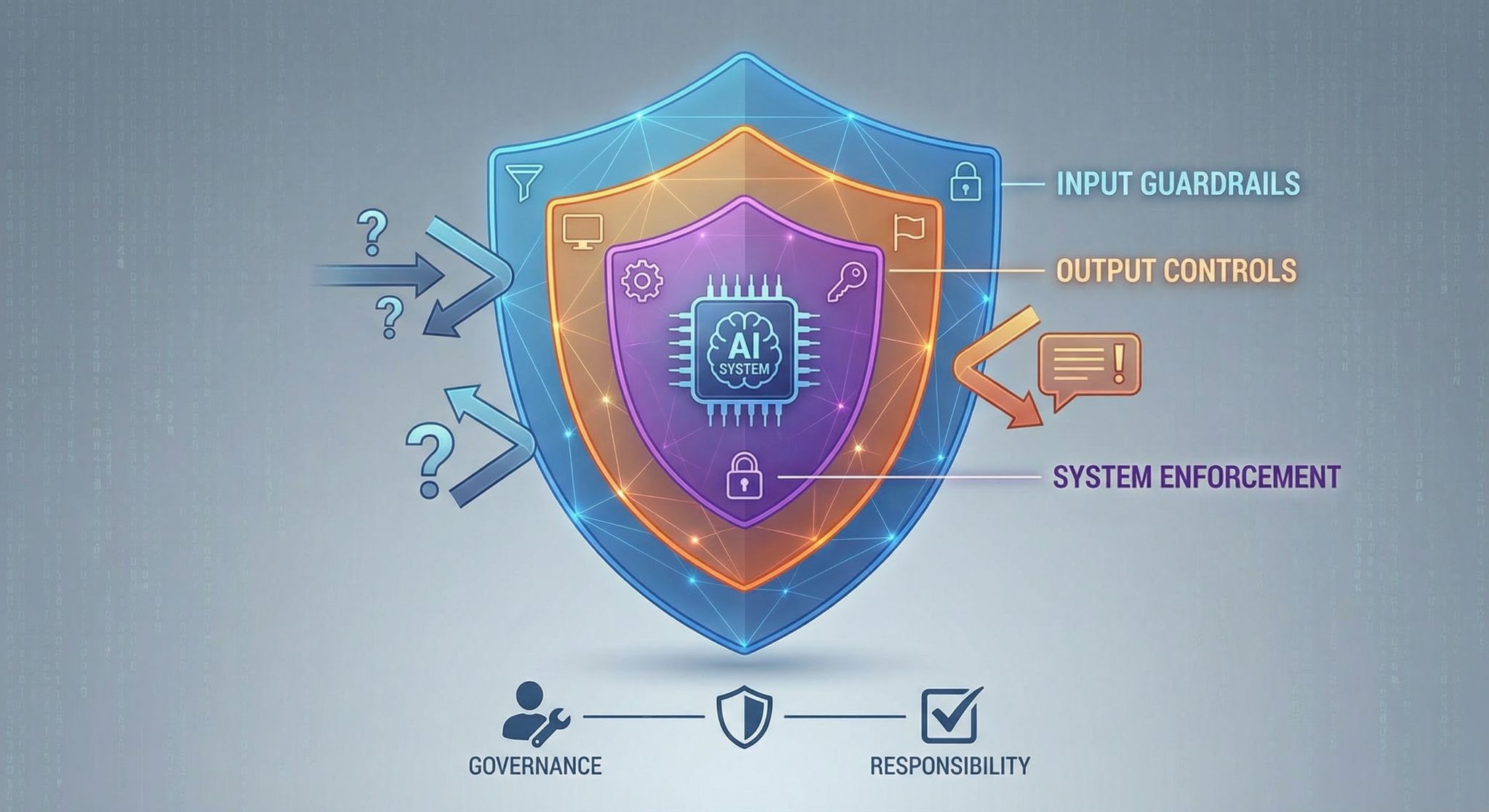
2. Understanding AI misuse and System Abuse Guardrails
AI systems don’t “go rogue.” They follow instructions. The problem is that they often follow the wrong ones.
When people talk about AI guardrails, they usually imagine a simple content filter — something that blocks bad words or unsafe responses. That’s surface-level. Real AI safety guardrails are deeper. They control how a system behaves under pressure, not just how it behaves during a demo.
Misuse tends to show up in three places.
First: the prompt layer
This is where adversarial users experiment. They rephrase instructions. They embed hidden directives. They attempt jailbreak patterns designed to override safety rules. If the system accepts every instruction at face value, it becomes steerable. Input guardrails exist to detect those patterns early — before the model processes them as legitimate requests. That alone reduces a significant share of AI misuse.
Second: the output layer
Even a clean prompt can produce harmful output. Models sometimes reveal more than they should. They hallucinate. They generate content that appears authoritative but isn’t. Output-level controls monitor responses in real time. They classify risk, flag sensitive data, and block responses when thresholds are crossed. This is not about censorship. It’s about preventing cascading failure.
Third: the system layer
Most AI failures aren’t just technical. They’re operational. Who has access? What data is connected? Are logs monitored? Are there boundaries to prevent data leakage in AI? Without enforcement at this level, even strong model-level protections can be bypassed.
This is where responsible AI governance becomes practical rather than theoretical. Governance defines responsibility. Guardrails enforce it.
Together, these layers reduce the surface area for abuse. Remove one, and the system becomes predictable. Predictability is what attackers exploit.
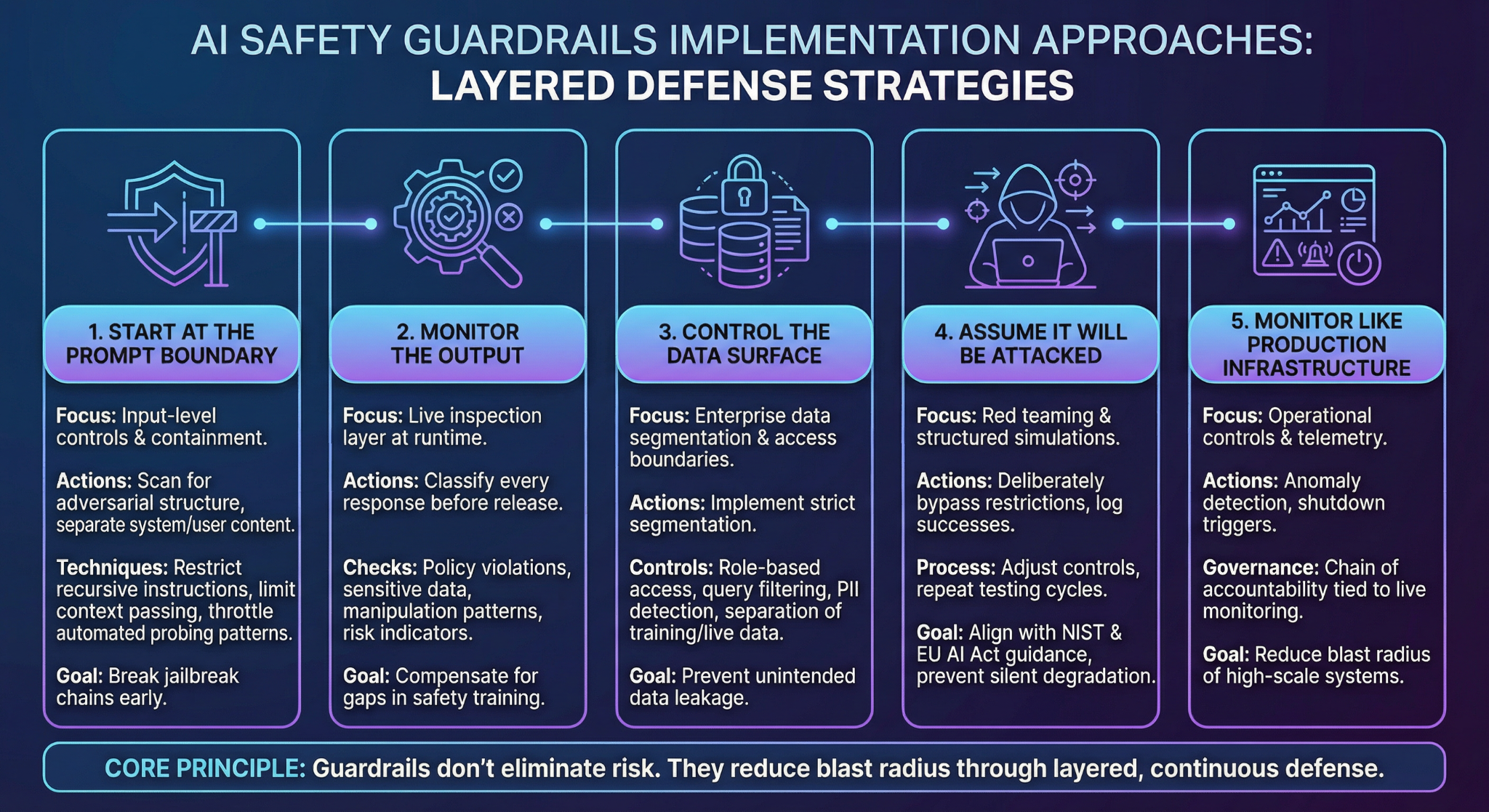
3. AI Safety Guardrails Implementation Approaches
If there’s one pattern across public AI failures, it’s this: the model wasn’t the only problem. The system around it was thin. Strong AI safety guardrails are built in layers. Not because it looks good in a diagram — but because misuse rarely happens in just one place.
3.1 Start at the Prompt Boundary
Most jailbreak demonstrations follow the same playbook. Reframe the instruction. Add role-play context. Introduce a fictional scenario. Gradually steer the model away from its intended constraints.
Input-level controls try to break that chain early.
That means scanning prompts for adversarial structure, separating system instructions from user content, restricting recursive instructions, and limiting how context is passed between turns. Some systems also throttle usage patterns that resemble automated probing.
This is the first containment line for AI misuse. If you don’t control what enters the reasoning loop, you can’t control what comes out.
3.2 Don’t Trust Training Alone — Monitor the Output
Alignment techniques like reinforcement learning help reduce harmful responses. But runtime behavior still shifts under pressure. Researchers have shown that even well-aligned models can produce restricted outputs when pushed hard enough.
Output-level guardrails therefore act as a live inspection layer.
Instead of assuming the model behaves correctly, the system classifies every response before release. It checks for policy violations, sensitive data, manipulation patterns, and risk indicators.. If a "response" crosses a threshold, it’s blocked, redacted, or escalated.
This is where many organizations underestimate risk. They assume safety training equals safety performance. It doesn’t.
AI guardrails at runtime compensate for that gap.
3.3 Control the Data Surface
Enterprise deployments raise a different question: what data can the model see?
When AI systems connect to internal knowledge bases, ticketing systems, HR records, or customer data, exposure risk increases. Without strict segmentation, misuse can quickly turn into data leakage in AI.
Effective controls here are often less glamorous but more important:
⮞ Role-based access boundaries
⮞ Query filtering before retrieval
⮞ PII detection before response generation
⮞ Separation between training datasets and live enterprise data
Several regulatory frameworks now emphasize this boundary explicitly. The risk isn’t just harmful language — it’s unintended disclosure.
3.4 Assume It Will Be Attacked
Red teaming used to be optional. Now it’s becoming expected.
Security researchers routinely publish jailbreak techniques. That alone is a signal: if external actors are testing systems, organizations must test them first.
Red teaming involves structured adversarial simulations. You deliberately attempt to bypass your own restrictions. You log what succeeds. You adjust controls. Then you repeat.
This approach aligns with guidance from NIST’s AI Risk Management Framework and emerging EU AI Act requirements around risk assessment and testing.
Without stress testing, guardrails degrade quietly.
3.5 Monitor Like It’s Production Infrastructure
AI systems are not static deployments. Usage evolves. Prompts change. New edge cases emerge.
Operational controls therefore include telemetry monitoring, anomaly detection for unusual behavior patterns, and predefined shutdown triggers. If a model starts generating policy-violating content at scale, someone needs authority to pause it.
This is where responsible AI governance becomes real. Governance isn’t a policy PDF. It’s a chain of accountability tied to live monitoring.
Guardrails don’t eliminate risk. They reduce blast radius.
And in high-scale AI systems, blast radius is everything.
4. How AI Safety Guardrails Fail in Practice
Guardrails fail less dramatically than headlines suggest. Most of the time, they fail quietly. A missed edge case. An assumption that training was enough. A system shipped before monitoring was fully wired.
And then pressure hits.
Let’s examine where breakdowns usually happen.
Why do static rules fail against adaptive misuse?
Because attackers iterate faster than policy updates.
Many systems rely on fixed keyword blocks or narrow refusal templates. That works briefly. Then users rephrase. They embed instructions inside stories. They role-play around constraints. Jailbreak communities openly share techniques, and those techniques evolve.
When AI guardrails are static, misuse becomes a game of pattern matching. The model only needs one overlooked phrasing to comply.
Guardrails that don’t adapt become predictable. Predictability is exploitable.
Why doesn’t model alignment alone solve the problem?
Alignment reduces risk. It doesn’t eliminate it.
Even highly tuned models have been shown in public research to produce restricted content under carefully constructed prompts. Alignment happens at training time. Misuse happens at runtime.
Without live output inspection and escalation logic, AI safety guardrails depend entirely on prior training assumptions. That gap widens as systems are exposed to real-world variability.
How does governance disconnect create system abuse risk?
Technical teams often build controls. Leadership teams often define policy. But when the two don’t stay aligned, enforcement weakens.
For example:
⮞ Access controls defined on paper but not enforced in APIs
⮞ Monitoring dashboards built but not actively reviewed
⮞ No clear ownership when abuse patterns appear
This is where responsible AI governance becomes critical. Governance must define accountability for deployment, logging, and shutdown authority. Without ownership, guardrails become documentation instead of defense.
What happens when AI is deployed faster than oversight?
Shadow deployments.
Teams integrate AI into workflows before security review. Internal tools connect to sensitive systems. Usage scales quietly. Then a misuse incident reveals that no one was tracking behavior patterns.
At that point, failure isn’t technical. It’s structural.
When layered controls break — or never fully exist — misuse moves from isolated prompts to systemic exposure. And recovery becomes reactive rather than preventative.
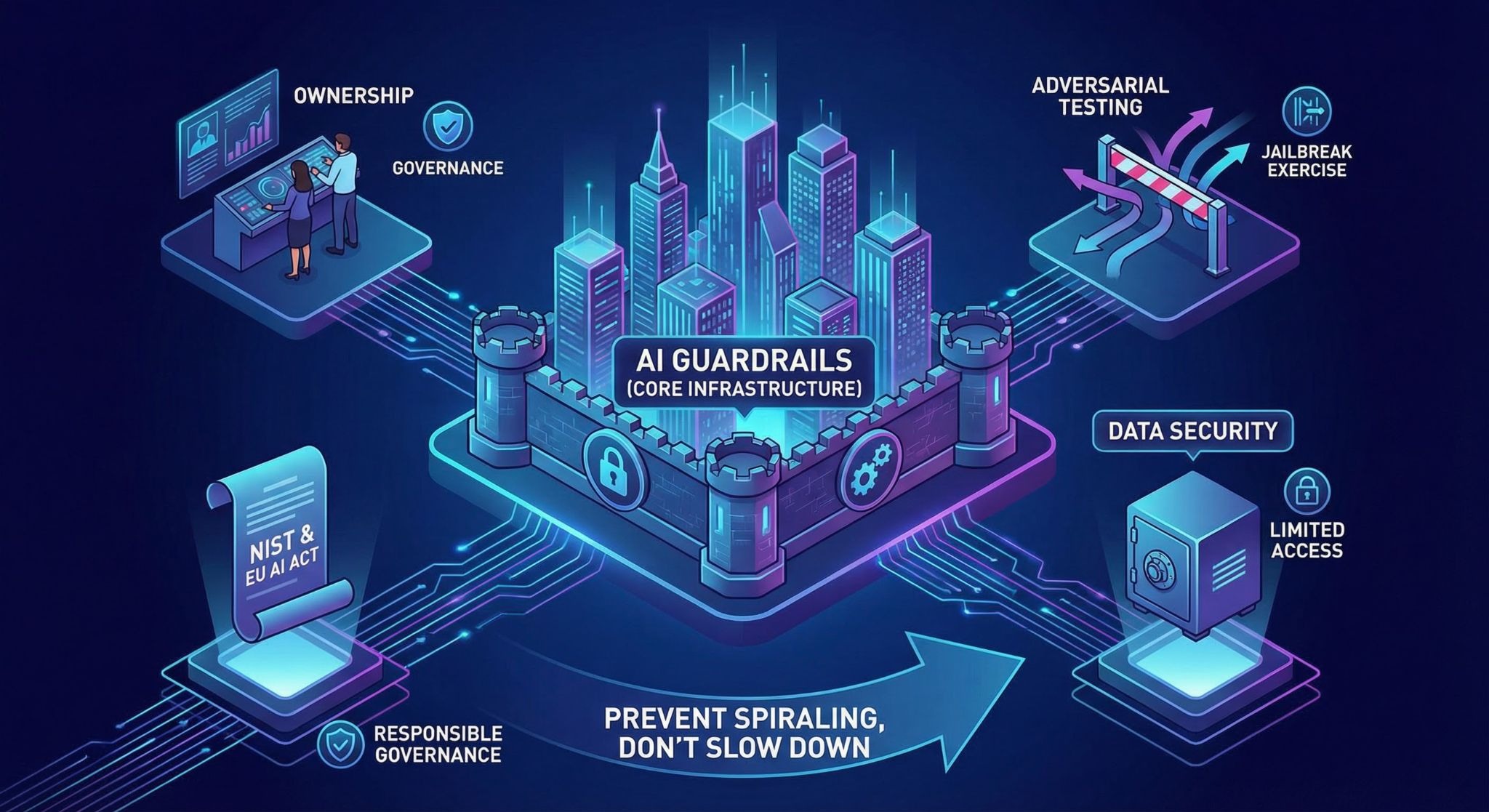
5. Recommendations for Organizations
Treat AI guardrails like core infrastructure. Not a feature toggle. Not a compliance checkbox. If they’re optional, they’ll be bypassed the first time delivery pressure rises.
Decide ownership early. Who monitors live model behavior? Who reviews anomaly alerts? Who can shut the system down if something drifts? Without clear authority, AI safety guardrails slowly become decorative.
Design specifically for adversarial pressure. Assume users will probe the edges. Run internal jailbreak exercises. Log what breaks. Fix it. Then test again. Guardrails that are never stressed tend to fail publicly.
Reduce data exposure wherever possible. Limit which systems an AI tool can access. Enforce role-based permissions. Build technical controls that actively prevent data leakage in AI instead of relying on policy warnings.
And anchor all of this in responsible AI governance that connects policy to engineering reality. Frameworks like NIST’s AI Risk Management Framework and the EU AI Act increasingly require risk assessment and monitoring. Those expectations aren’t theoretical anymore.
Guardrails don’t slow systems down. They prevent them from spiraling.
6. Conclusion
AI systems don’t fail only because models are flawed. They fail when boundaries are weak.
The rise of AI misuse shows a clear pattern: powerful systems attract pressure. Users experiment. Attackers probe. Internal teams move fast. Without layered controls, exposure scales quietly until something breaks in public.
That’s why AI guardrails can’t remain abstract principles. They must exist at the prompt boundary, at the output layer, and at the system level. AI safety guardrails are not about limiting capability — they are about constraining blast radius.
As regulatory expectations tighten and deployment accelerates, the organizations that operationalize responsible AI governance will absorb fewer shocks.
AI will keep evolving. So will misuse.
The difference between failure and resilience will come down to whether guardrails were built before they were needed.

“Powerful AI without guardrails is predictable risk.”






Protect your AI with WizSumo — deploy layered guardrails that stop misuse and preserve trust!

.png)
.png)
.png)



