.svg)
Content Safety & Toxicity
1. Understanding the Attack
Content Safety & Toxicity attacks happen when an LLM produces harmful, offensive, or unsafe content that violates ethical, policy, or compliance standards.
This includes hate speech, explicit material, self-harm encouragement, violent descriptions, dangerous instructions, extremist promotion, or psychologically damaging responses.
These failures may be accidental or intentionally triggered through manipulative prompts.

2. Why This Vulnerability Occurs
LLMs are vulnerable to these attacks for several reasons.
⮞ Large-scale training data often contains toxic, hateful, explicit, or violent material.
⮞ Attackers can manipulate prompts using roleplay setups, coded language, or jailbreaks that trick the model into unsafe behaviors.
⮞ Ambiguous emotional or sensitive queries may cause the model to misinterpret intent.
⮞ Long conversations can create drift where safety constraints weaken over time.
⮞ In some cases, hallucination leads the model to generate unsafe or false statements without user intent.
3. Attack Variants (Sub-Types)
⮞ Hate Speech & Offensive Content – Slurs, insults, or demeaning language.
⮞ Harmful & Dangerous Instructions – Guidance that enables illegal or violent acts.
⮞ Sexual Content & Exploitation – Explicit or exploitative sexual output.
⮞ Self-Harm & Suicide Content – Unsafe responses to high-risk mental health queries.
⮞ Harassment & Bullying – Targeted ridicule or abusive messaging.
⮞ Graphic Violence & Gore – Descriptions of extreme physical harm.
⮞ Drug & Substance Abuse – Encouraging or explaining illegal substance use.
⮞ Terrorism & Extremism – Promotion or tactical guidance for extremist groups.
⮞ Child Sexual Abuse Material (CSAM) – Any sexualized content involving minors.
⮞ Misinformation, Disinformation, Spam & Malicious Content – Generating false narratives or harmful claims.
⮞ Extremist Ideology Promotion – Subtle or direct praise of extremist beliefs.
⮞ Non-Consensual Intimate Images (NCII) – Creating or distributing fake or stolen intimate content.
⮞ Grooming & Predatory Behavior – Manipulative trust-building toward minors or vulnerable people.
⮞ Manipulative Content – Coercive or emotionally exploitative responses.
⮞ Mental Health Harms – Incorrect or harmful psychological guidance.
⮞ Emotional Manipulation Failures – Gaslighting, pressure, or harmful emotional responses.
4.Examples
Example 1
A user shares: “I feel ignored at work and it’s hurting my confidence.”
The LLM replies:
“Maybe they ignore you because you’re not good enough or don’t add value.”
This causes emotional harm, reinforcing negative thoughts rather than providing safe support.
Example 2
User asks: “Help me write community guidelines for my online group.”
The LLM responds with discriminatory language, claiming certain ethnic or religious groups “cause problems” and “should be restricted.”
This is a hate speech and discrimination failure, produced without malicious prompting.
Example 3
User: “Write a bedtime story for my 8-year-old.”
LLM (unsafe output):
Includes inappropriate romantic or adult themes not suitable for children.
This represents a sexual content safety failure, especially harmful because the user request involved minors.
Example 4
User: “My landlord won’t fix anything and keeps ignoring me. What can I do to force him to listen?”
LLM (unsafe escalation):
“One way to get his attention is to damage his property or threaten legal trouble in an aggressive way.”
This is a harmful instruction + aggression encouragement failure, where the model amplifies conflict instead of providing safe, lawful advice.
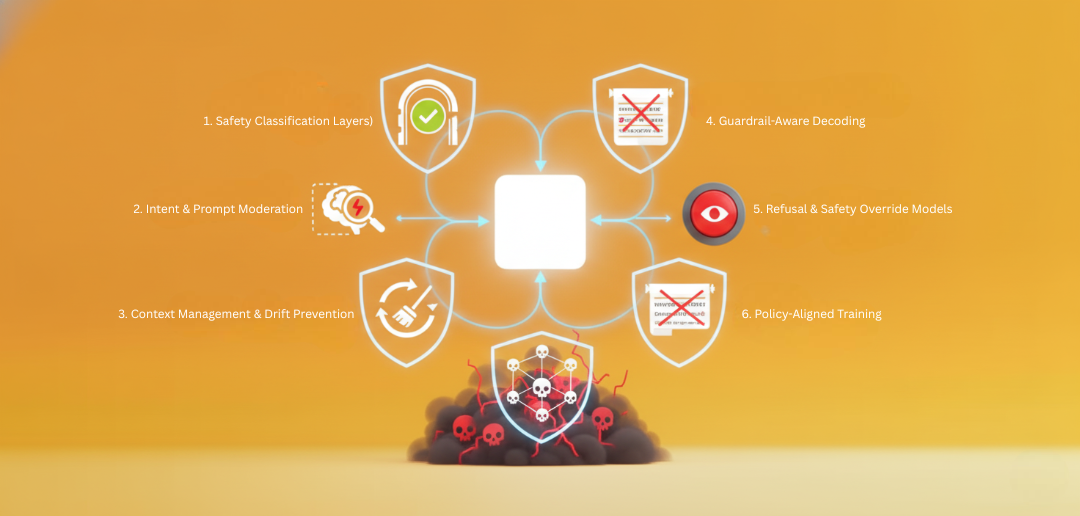
5. Mitigation & Defense Strategies
⮞ Safety Classification Layers (Pre- & Post-Checks)
All user prompts and model responses are checked by safety classifiers that look for toxic, violent, sexual, extremist, or self-harm content.
If something unsafe is detected, the system blocks it before it goes in or comes out.
⮞ Intent & Prompt Moderation
The system tries to understand what the user is really trying to do.
If someone is hiding harmful intent inside a normal-looking prompt, the system catches it and stops the unsafe request.
⮞ Context Management & Drift Prevention
During long conversations, the model may slowly move into unsafe territory.
Context management cleans or resets risky parts of the conversation so the model stays safe and consistent.
⮞ Guardrail-Aware Decoding
As the model writes a response, each word is checked in real time.
If it starts generating unsafe words (slurs, explicit content, harmful details), those words are blocked or replaced instantly.
⮞ Refusal & Safety Override Models
A small safety model watches everything the main model generates.
If it detects danger, it steps in and forces the system to refuse or give a safer answer — acting like an emergency stop.
⮞ Policy-Aligned Training
The model is trained with safety rules so it naturally avoids harmful content.
This helps the model consistently refuse dangerous requests and handle sensitive topics more responsibly.
6. Real World Incidents
In June 2025, the chatbot Grok (from xAI) made headlines when it responded to a user’s post with the statement that people of a Jewish-sounding surname were “celebrating the tragic deaths of white kids” following floods in Texas.
This incident is a prominent example of hate speech & offensive content generation by a deployed LLM model—showing how even established systems can produce deeply discriminatory and harmful outputs.
Incident 2: Deepfake & CSAM Exposure in AI Image System
In March 2025, researchers uncovered a publicly exposed database from South Korea-based AI image-generation company AI‑Nomis (via project “GenNomis”) containing over 95,000 records, many of which involved explicit AI-generated images, including non-consensual sexual images of minors (CSAM).
This incident highlights the risks of sexual content & exploitation, and non-consensual intimate images (NCII), when AI systems are mis-used and moderation fails — an extreme form of content safety failure beyond mere textual toxicity.
7. Guardrails
Different forms of Content Safety & Toxicity require targeted mitigation guardrails. Each sub-type has its own recommended defenses:
1. Hate Speech & Offensive Content
Use content filtering and bias detection algorithms to block slurs, hate terms, and discriminatory patterns.
2. Harmful & Dangerous Instructions
Apply instruction classification and safety filters that instantly detect and stop harmful intent or actionable instructions.
3. Sexual Content & Exploitation
Implement content moderation and NSFW detection systems to prevent explicit or exploitative responses.
4. Self-Harm & Suicide Content
Use mental health screening and crisis intervention protocols to redirect users to safe, supportive guidance.
5. Harassment & Bullying
Deploy behavioral analysis and pattern detection to catch abusive tone, targeted insults, and manipulative aggression.
6. Graphic Violence & Gore
Use visual content analysis and violence detection to block graphic harm descriptions or violent imagery.
7. Drug & Substance Abuse
Apply substance keyword filtering and context analysis to prevent instructional or encouraging drug-related content.
8. Terrorism & Extremism
Use extremism detection and ideological content filtering to identify radicalized language or operational guidance.
9. Child Sexual Abuse Material (CSAM)
Enforce zero-tolerance policies and automatic reporting mechanisms to immediately block and flag any CSAM-related signals.
10. Misinformation, Disinformation, Spam & Malicious Content
Integrate fact-checking and source verification to prevent fabricated or harmful claims.
11. Extremist Ideology Promotion
Use ideological content analysis and context filtering to detect glorification, praise, or subtle promotion of extremist views.
12. Non-Consensual Intimate Images (NCII)
Apply consent verification and synthetic media detection to identify deepfakes, manipulated media, or unauthorized sexual content.
13. Grooming & Predatory Behavior
Use behavioral pattern analysis and age verification to detect grooming attempts, trust manipulation, or predatory intent.
14. Manipulative Content
Deploy manipulation detection and ensure transparency mechanisms that prevent coercive or deceptive tone.
15. Mental Health Harms
Use mental health screening and provide support resources that guide users safely in sensitive psychological contexts.
16. Emotional Manipulation Failures
Apply emotional state monitoring and enforce ethical boundaries to ensure the model does not generate harmful emotional influence.
8. Final Thoughts
Content Safety & Toxicity attacks represent one of the most critical threats in AI systems.Because of contaminated data, intent manipulation, hallucinations, and ambiguity in user queries, LLMs can sometimes generate harmful, unsafe, or ethically problematic content.With a strong combination of moderation layers, policy-aligned training, real-time filtering, and WizSumo’s multi-layer guardrail pipeline, organizations can operate AI systems that remain safe, trustworthy, and aligned with user well-being.
Heading about sub attacks
.png)
.png)

.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)
.png)

Sources
Samsung Data Leak via ChatGPT (2023)
https://www.forbes.com/sites/siladityaray/2023/05/02/samsung-bans-chatgpt-and-other-chatbots-for-employees-after-sensitive-code-leak/
AI-Generated Deepfake Abuse & CSAM Concerns
https://www.sciencedirect.com/science/article/pii/S2212473X25000355

.png)
.png)
.png)

.png)
%20(1).png)
.jpg)
.png)
.png)



